
【系统设计】分布式键值数据库
键值存储 ( key-value store ),也称为 K/V 存储或键值数据库,这是一种非关系型数据库。每个值都有一个唯一的 key 关联,也就是我们常说的 键值对。
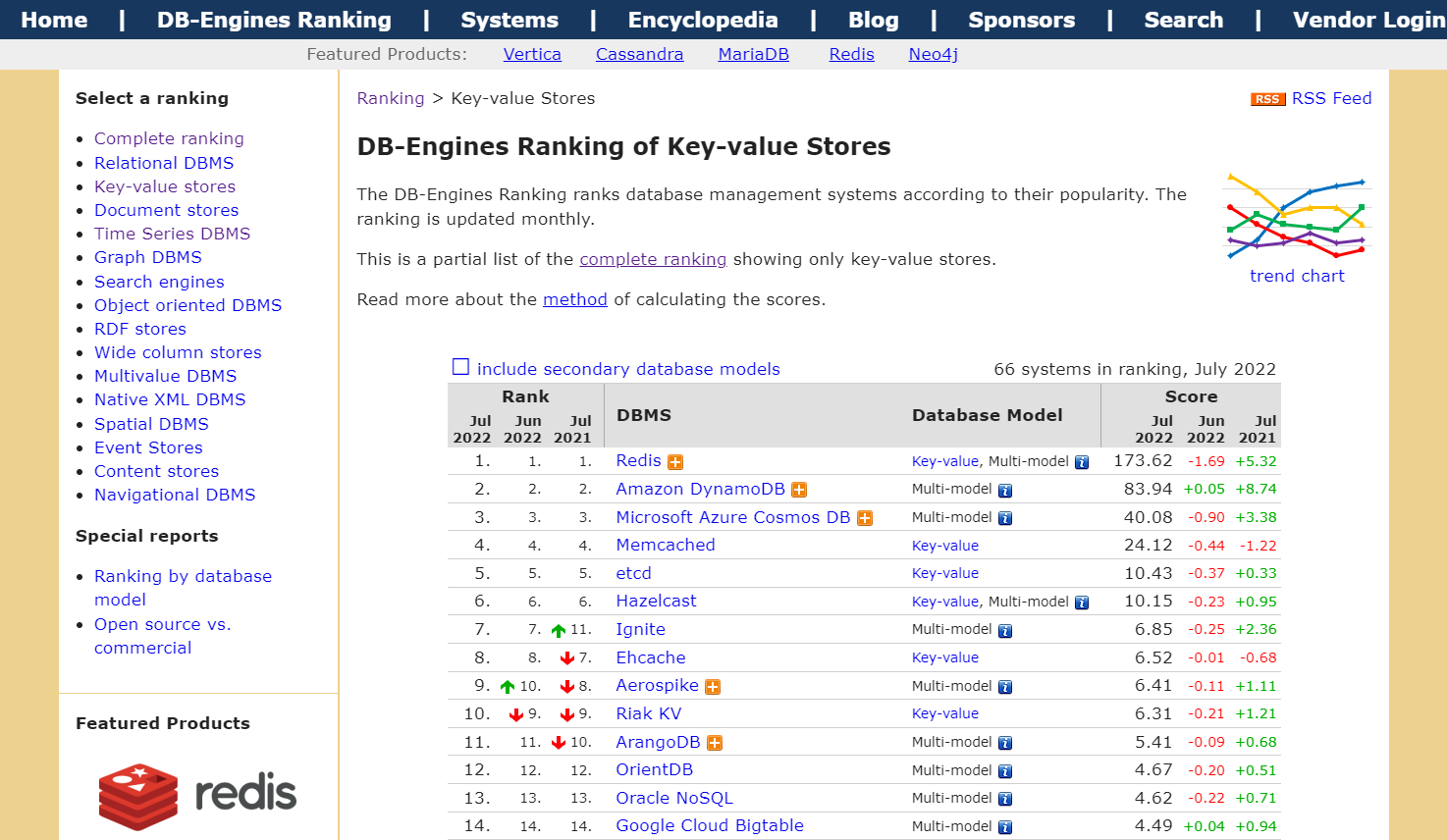
常见的键值存储有 Redis, Amazon DynamoDB,Microsoft Azure Cosmos DB,Memcached,etcd 等。
你可以在 DB-Engines 网站上看到键值存储的排行。
设计要求

在这个面试的系统设计环节中,我们需要设计一个键值存储, 要满足下面的几个要求
- 每个键值的数据小于 10kB。
- 有存储大数据的能力。
- 高可用,高扩展性,低延迟。
单机版 - 键值存储
对于单个服务器来说,开发一个键值存储相对来说会比较简单,一种简单的做法是,把键值都存储在内存中的哈希表中,这样查询速度非常快。但是,由于内存的限制,把所有的数据放到内存中明显是行不通的。
所以,对于热点数据(经常访问的数据)可以加载到内存中,而其他的数据可以存储在磁盘。但是,当数据量比较大时,单个服务器仍然会很快达到容量瓶颈。
分布式 - 键值存储
分布式键值存储也叫分布式哈希表,把键值分布在多台服务器上。在设计分布式系统时,理解 CAP(一致性,可用性,分区容错性) 定理很重要。
CAP 定理
CAP 定理指出,在分布式系统中,不可能同时满足一致性、可用性和分区容错性。让我们认识一下这三个定义:
- 一致性: 无论连接到哪一个节点,所有的客户端在同一时间都会看到相同的数据。
- 可用性:可用性意味着任何请求数据的客户端都会得到响应,即使某些节点因故障下线。
- 分区容错性:分区表示两个节点之间的网络通信中断。分区容错性意味着,当存在网络分区时,系统仍然可以继续运行。
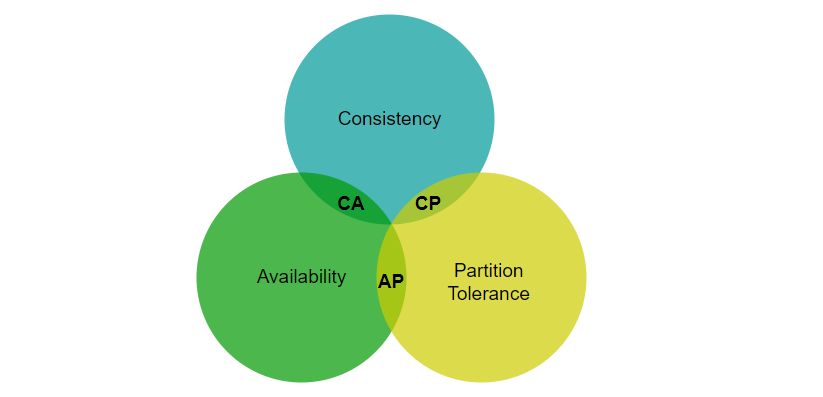
通常可以用 CAP 的两个特性对键值存储进行分类:
CP(一致性和分区容错性)系统:牺牲可用性的同时支持一致性和分区容错。
AP(可用性和分区容错性)系统:牺牲一致性的同时支持可用性和分区容错。
CA(一致性和可用性)系统:牺牲分区容错性的同时支持一致性和可用性。
由于网络故障是不可避免的,所以在分布式系统中,必须容忍网络分区。
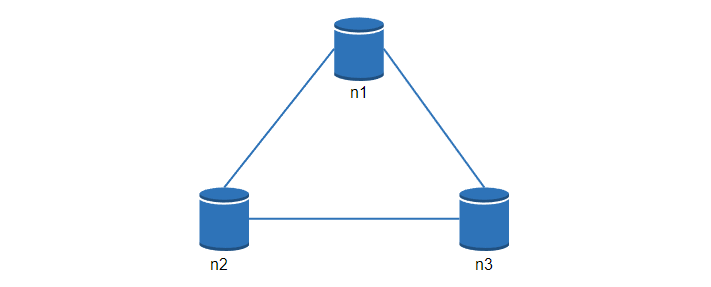
让我们看一些具体的例子,在分布式系统中,为了保证高可用,数据通常会在多个系统中进行复制。假设数据在三个节点 n1, n2, n3 进行复制,如下:
理想情况
在理想的情况下,网络分区永远不会发生。写入 n1 的数据会自动复制到 n2 和 n3,实现了一致性和可用性。
现实世界的分布式系统
在分布式系统中,网络分区是无法避免的,当发生分区时,我们必须在一致性和可用性之间做出选择。
在下图中,n3 出现了故障,无法和 n1 和 n2 通信,如果客户端把数据写入 n1 或 n2,就没办法复制到 n3,就会出现数据不一致的情况。
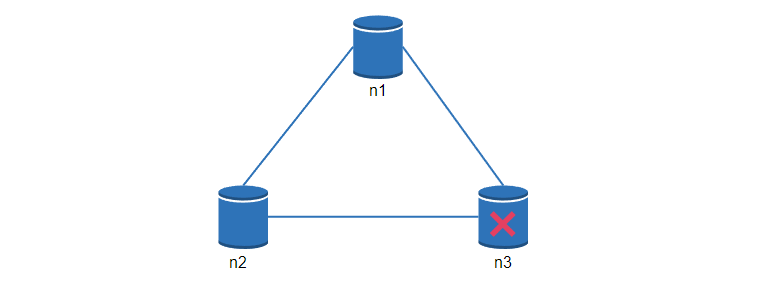
如果我们选择一致性优先(CP系统),当 n3 故障时, 就必须阻止所有对 n1 和 n2 的写操作,避免三个节点之间的数据不一致。涉及到钱的系统通常有极高的一致性要求。
如果我们选择可用性优先(AP系统),当 n3 故障时,系统仍然可以正常的写入读取,但是可能会返回旧的数据,当网络分区恢复后,数据再同步到 n3 节点。
选择合适的 CAP 是构建分布式键值存储的重要一环。
核心组件和技术
接下来,我们会讨论构建键值存储的核心组件和技术:
- 数据分区
- 数据复制
- 一致性
- 不一致时的解决方案
- 故障处理
- 系统架构图
- 数据写入和读取流程
数据分区
在数据量比较大场景中,把数据都存放在单个服务器明显是不可行的,我们可以进行数据分区,然后保存到多个服务器中。
需要考虑到的是,多个服务器之间的数据应该是均匀分布的,在添加或者删除节点时,需要移动的数据应该尽量少。
一致性哈希非常适合在这个场景中使用,下面的例子中,8台服务器被映射到哈希环上,然后我们把键值的 key 也通过哈希算法映射到环上,然后找到顺时针方向遇到的第一个服务器,并进行数据存储。
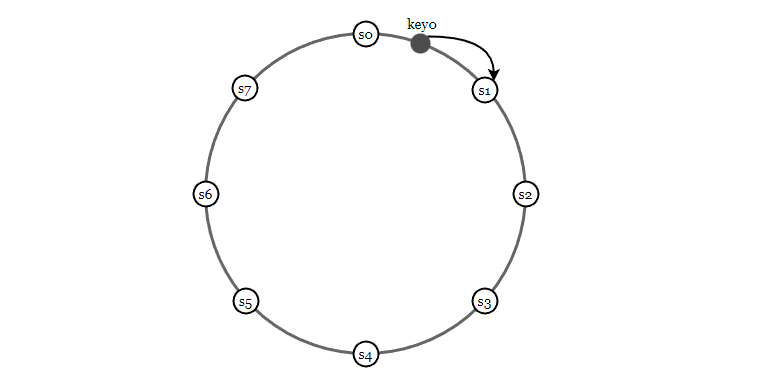
使用一致性哈希,在添加和删除节点时,只需要移动很少的一部分数据。
数据复制
为了实现高可用性和可靠性,一条数据在某个节点写入后,会复制到其他的节点,也就是我们常说的多副本。
那么问题来了,如果我们有 8 个节点,一条数据需要在每个节点上都存储吗?
并不是,副本数和节点数没有直接关系。副本数应该是一个可配置的参数,假如副本数为 3,同样可以借助一致性哈希环,按照顺时针找到 3 个节点,并进行存储,如下
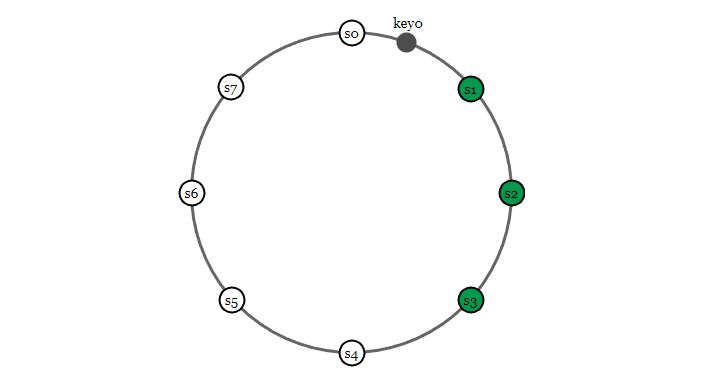
一致性
因为键值数据在多个节点上复制,所以我们必须要考虑到数据一致性问题。
Quorum 共识算法可以保证读写操作的一致性,我们先看一下 Quorum 算法中 NWR 的定义。
N = 副本数, 也叫复制因子,在分布式系统中,表示同一条数据有多少个副本。
W = 写一致性级别,表示一个写入操作,需要等待几个节点的写入后才算成功。
R = 读一致性级别,表示读取一个数据时,需要同时读取几个副本数,然后取最新的数据。
如下图,N = 3
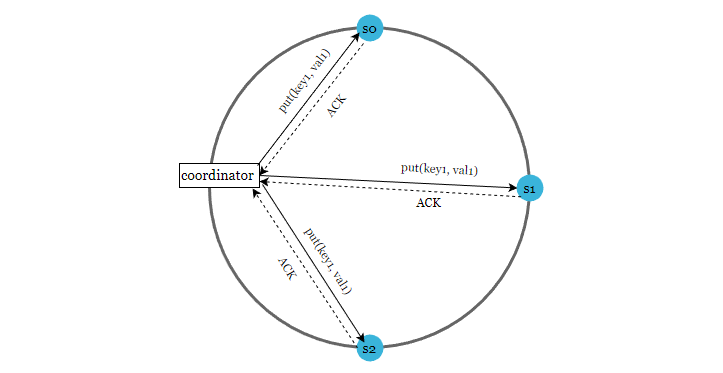
注意,W = 1 并不意味着数据只写到一个节点,控制写入几个节点的是 N 副本数。
N = 3 表示,一条数据会写入到 3 个节点,W = 1 表示,只要收到任何节点的第一个写入成功确认消息(ACK)后,就直接返回写入成功。
这里的重点是,对 N、W、R的值进行不同的组合时,会产生不同的一致性效果。
- 当 W + R > N 的时候,通常是 N = 3, W = R = 2,对于客户端来讲,整个系统能保证强一致性,一定能返回更新后的那份数据。
- 当 W + R <= N 的时候,对于客户端来讲,整个系统只能保证最终一致性,所以可能会返回旧数据。
通过 Quorum NWR,可以调节系统一致性的程度。
一致性模型
一致性模型是设计键值存储要考虑的另外一个重要因素,一致性模型定义了数据一致性的程度。
- 强一致性: 任何一个读取操作都会返回一个最新的数据。
- 弱一致性: 数据更新之后,读操作可能会返回最新的值,也有可能会返回更新前的值。
- 最终一致性: 这是弱一致性的另外一种形式。可能当前节点的值是不一致的,但是等待一段时间的数据同步之后,所有节点的值最终会保持一致。
强一致性的通常做法是,当有副本节点因为故障下线时,其他的副本会强制中止写入操作。一致性程度比较高,但是牺牲了系统的高可用。
而 Dynamo 和 Cassandra 都采用了最终一致性,这也是键值存储推荐使用的一致性模型,当数据不一致时,客户端读取多个副本的数据,进行协调并返回数据。
不一致的解决方案:版本控制
多副本数据复制提供了高可用性,但是多副本可能会存在数据不一致的问题。
版本控制和向量时钟(vector clock )是一个很好的解决方案。向量时钟是一组 [server,version] 数据,它通过版本来检查数据是否发生冲突。
假设向量时钟由 D([S1, v1], [S2, v2], ..., [Sn, vn]) 表示,其中 D 是数据项,v1 是版本计数器,下面是一个例子
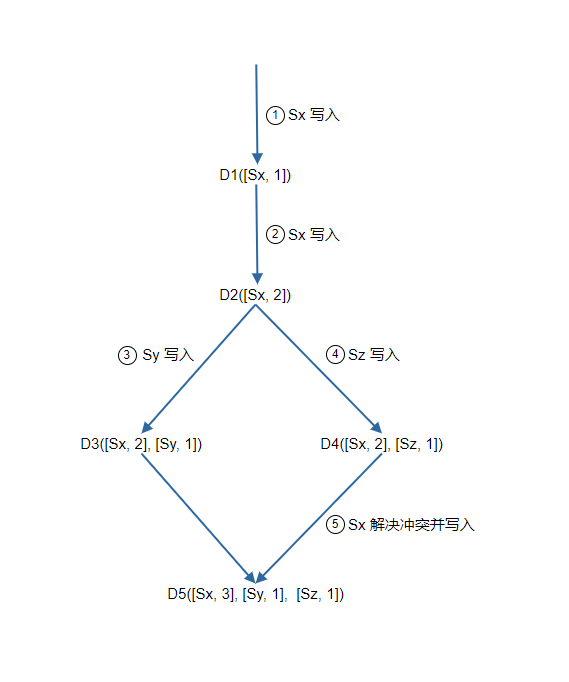
- 客户端把数据 D1 写入系统,写入操作由 Sx 处理,服务器 Sx 现在有向量时钟 D1[(Sx, 1)]。
- 客户端把 D2 写入系统,假如这次还是由 Sx 处理,则版本号累加,现在的向量时钟是 D2([Sx, 2])。
- 客户端读取 D2 并更新成 D3,假如这次的写入由 Sy 处理, 现在的向量时钟是D3([Sx, 2], [Sy, 1]))。
- 客户端读取 D2 并更新成 D4,假如这次的写入由 Sz 处理,现在的向量时钟是 D4([Sx, 2], [Sz, 1]))。
- 客户端读取到 D3 和 D4,检查向量时钟后发现冲突(因为不能判断出两个向量时钟的顺序关系),客户端自己处理解决冲突,然后再次写入。假如写入是 Sx 处理,现在的向量时钟是 D5([Sx, 3], [Sy, 1], [Sz, 1])。
注意,向量时钟只能检测到冲突,如何解决,那就需要客户端读取多个副本值自己处理了。
故障处理
在分布式大型系统中,发生故障是很常见的,接下来,我会介绍常见的故障处理方案。
故障检测
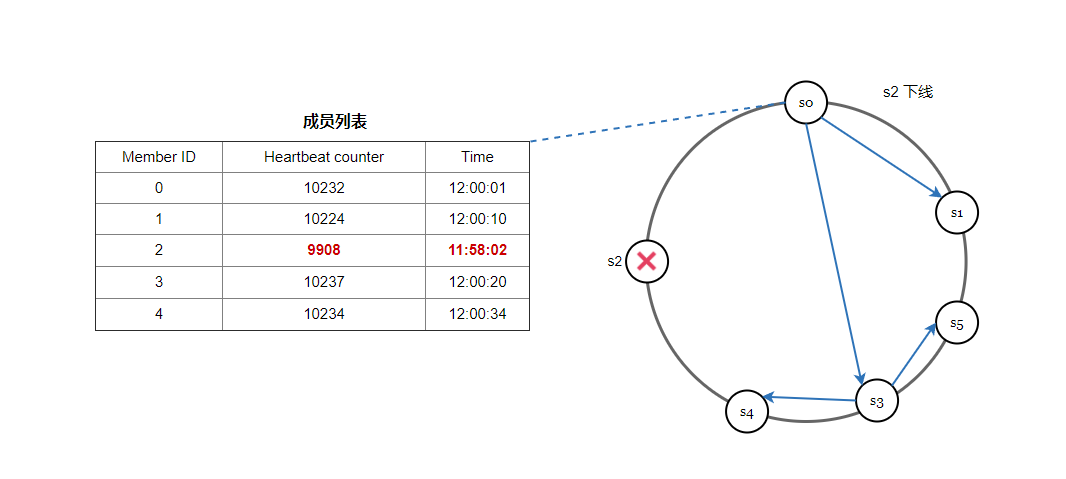
一种很常见的方案是使用 Gossip 协议,我们看一下它的工作原理:
- 每个节点维护一个节点成员列表,其中包含成员 ID 和心跳计数器。
- 每个节点周期性地增加它的心跳计数器。
- 每个节点周期性地向一组随机节点发送心跳,这些节点依次传播到另一组节点。
- 一旦节点收到心跳,成员列表就会更新为最新信息。
- 如果在定义的周期内,发现心跳计数器的值比较小,则认为该成员离线。
处理临时故障
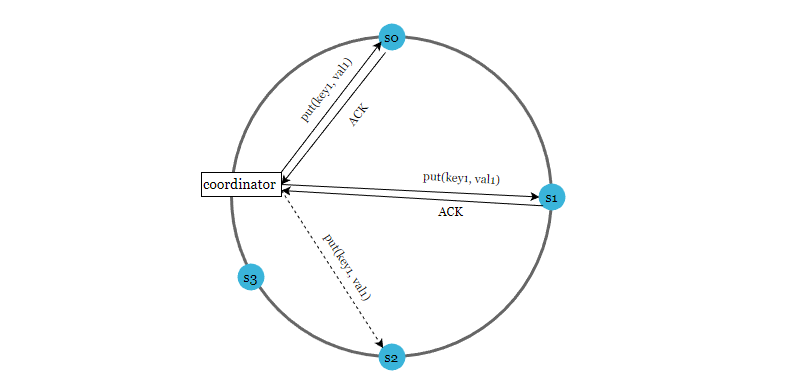
通过 gossip 协议检测到故障后,为了保证数据一致性,严格的 Quorum 算法会阻止写入操作。而 sloppy quorum 可以在临时故障的情况下,保证系统的可用性。
当网络或者服务器故障导致服务不可用时,会找一个临时的节点进行数据写入,当宕机的节点再次启动后,写入操作会更新到这个节点上,保持数据一致性。
如下图所示,当 s2 不可用时,写入操作暂时由 s3 处理, 在一致性哈希环上顺时针查找到下一个节点就是s3,当 s2 重新上线时,s3 会把数据还给 s2。
处理长时间故障
数据会在多个节点进行数据复制,假如节点发生故障下线,并且在一段时间后恢复,那么,节点之间的数据如何同步? 全量对比?明显是低效的。我们需要一种高效的方法进行数据对比和验证。
使用 Merkle 树是一个很好的解决方案,Merkle 树也叫做哈希树,这是一种树结构,最下面的叶节点包含数据或哈希值,每个中间节点是它的子节点内容的哈希值,根节点也是由它的子节点内容的哈希值组成。
下面的过程,展示了 Merkle 树是如何构建的。
第 1 步,把键值的存储空间划分为多个桶,一个桶可以存放一定数量的键值。
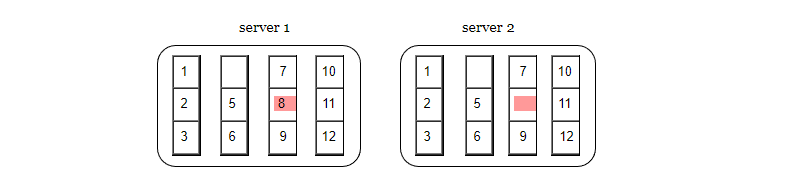
第 2 步,创建桶之后,使用哈希算法计算每个键的哈希值。
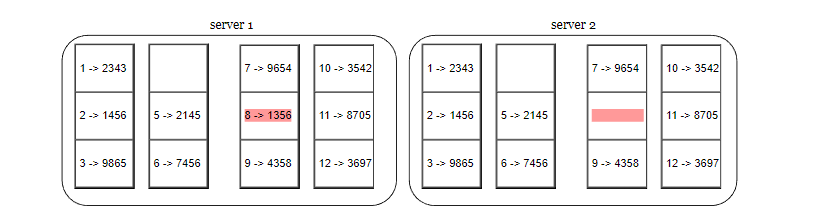
第 3 步,根据桶里面的键的哈希值,计算桶的哈希值。
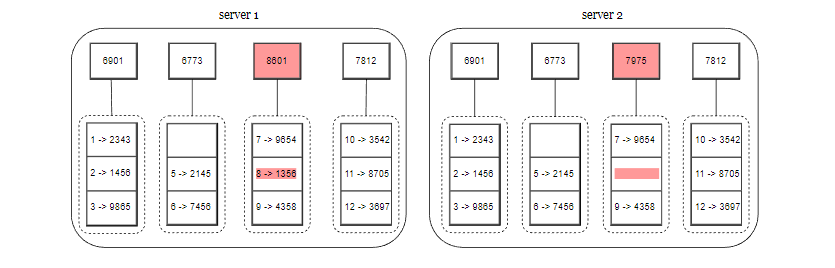
第 4 步,计算子节点的哈希值,并向上构建树,直到根节点结束。
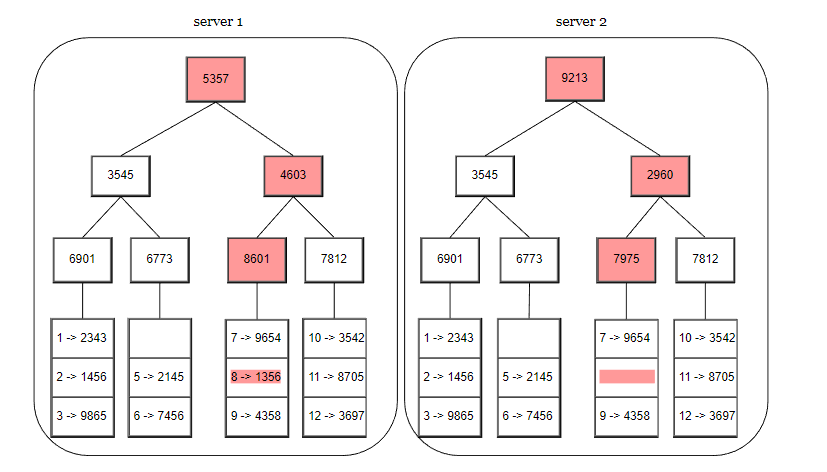
如果要比较两个 Merkle 树,首先要比较根哈希,如果根哈希一致,表示两个节点有相同的数据。如果根哈希不一致,就遍历匹配子节点,这样可以快速找到不一致的数据,并进行数据同步。
系统架构图
我们已经讨论了设计键值存储要考虑到的技术问题,现在让我们关注一下整体的架构图,如下
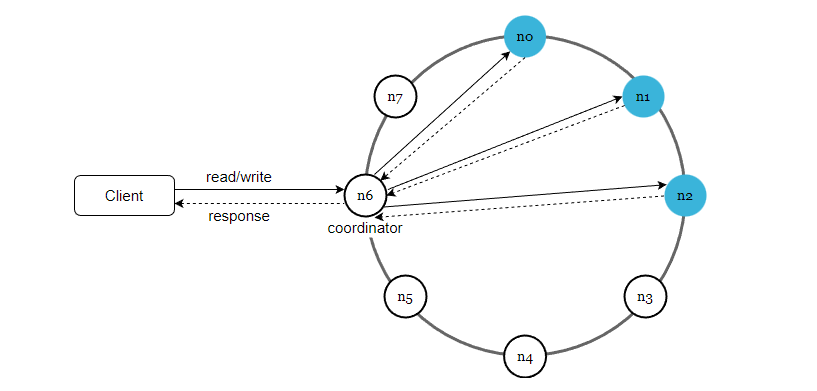
这个架构主要有下面几个特点:
- 客户端通过简单的 API 和键值存储进行通信,get (key) 和 put (key, value)。
- coordinator 协调器充当了客户端和键值存储之间的代理节点。
- 所有节点映射到了一致性哈希环上。
- 数据在多个节点上进行复制。
写入流程
下图展示了数据写入到存储节点的过程,主要基于 Cassandra 的架构设计。
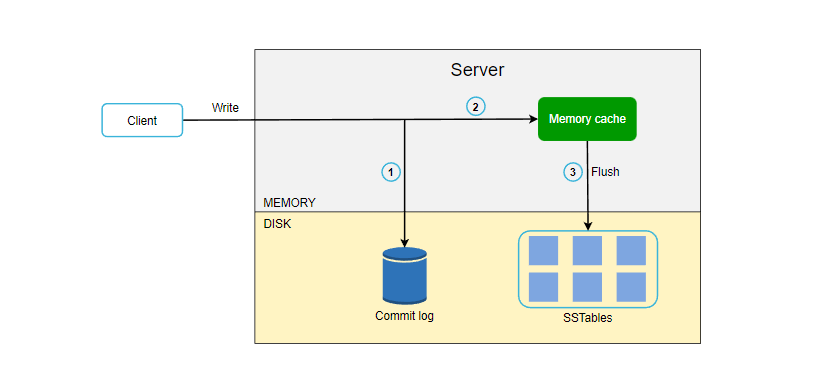
- 写入请求首先被持久化在提交日志文件中。
- 然后数据保存在内存缓存中。
- 当内存已满或者达到阈值时,数据移动到本地磁盘的 SSTable,这是一种高阶数据结构,感兴趣的读者自行查阅资料了解。
读取流程
在进行数据读取时,它首先检查数据是否在内存缓存中,如果是,就把数据返回给客户端,如下图所示:
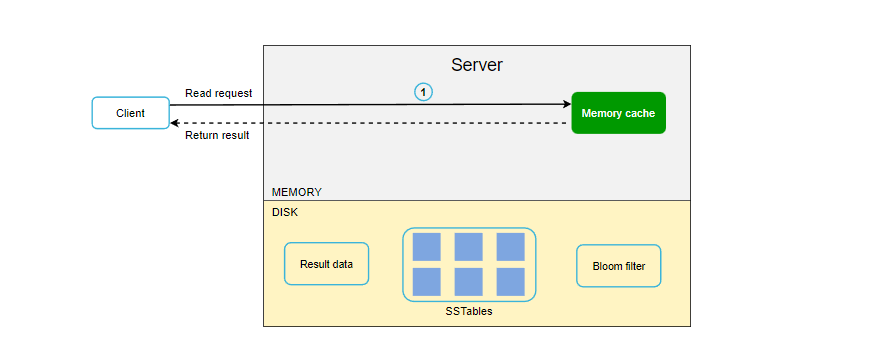
如果数据不在内存中,就会从磁盘中检索。我们需要一种高效的方法,找到数据在哪个 SSSTable 中,通常可以使用布隆过滤器来解决这个问题。
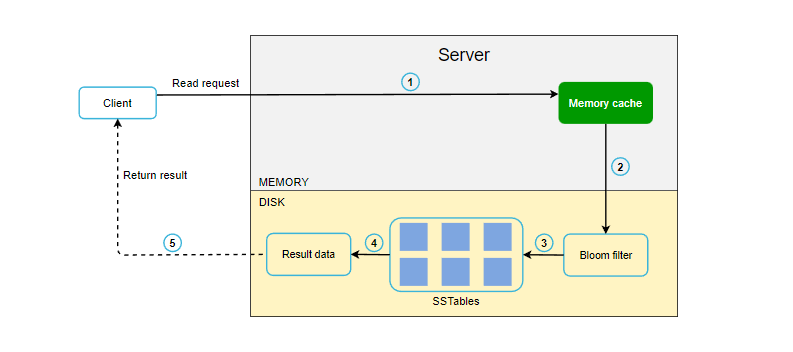
- 系统首先检查数据是否在内存缓存中。
- 如果内存中没有数据,系统会检查布隆过滤器。
- 布隆过滤器可以快速找出哪些 SSTables 可能包含密钥。
- SSTables 返回数据集的结果。
- 结果返回给客户端。
Reference
[0] System Design Interview Volume 2:
https://www.amazon.com/System-Design-Interview-Insiders-Guide/dp/1736049119
[1] Amazon DynamoDB: https://aws.amazon.com/dynamodb/
[2] memcached: https://memcached.org/
[3] Redis: https://redis.io/
[4] Dynamo: Amazon’s Highly Available Key-value Store:
https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
[5] Cassandra: https://cassandra.apache.org/
[6] Bigtable: A Distributed Storage System for Structured Data:
https://static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf
[7] Merkle tree: https://en.wikipedia.org/wiki/Merkle_tree
[8] Cassandra architecture: https://cassandra.apache.org/doc/latest/architecture/
[9] SStable: https://www.igvita.com/2012/02/06/sstable-and-log-structured-storage-leveldb/
[10] Bloom filter https://en.wikipedia.org/wiki/Bloom_filter

 浙公网安备 33010602011771号
浙公网安备 33010602011771号