【系统设计】设计一个限流组件
限速器 (Rate Limiter) 相信大家都不会陌生,在网络系统中,限速器可以控制客户端发送流量的速度,比如 TCP, QUIC 等协议。而在 HTTP 的世界中, 限速器可以限制客户端在一段时间内发送请求的次数,如果超过设定的阈值,多余的请求就会被丢弃。
生活中也有很多这样的例子,比如
- 用户一分钟最多能发 5 条微博
- 用户一天最多能投 3 次票
- 用户一小时登录超过5次后,需要等待一段时间才能重试。
限速器(Rate Limiter)有很多好处,可以防止一定程度的 Dos 攻击,也可以屏蔽掉一些网络爬虫的请求,避免系统资源被耗尽,导致服务不可用。
设计要求
让我们从一个面试开始吧!

面试官:你好,我想考察一下你的设计能力,如果让你设计一个限速器 (Rate Limiter),你会怎么做?
面试者: 我们需要什么样的限速器? 它是在客户端限速还是在服务端限速?
面试官:这个问题很好,没有固定要求,取决于你的设计。
面试者:我想了解一下限速的规则,我们是根据 IP、UserId,或者手机号码进行限速吗?
面试官:这个不固定,限速器应该是灵活的,要能很方便的支持不同的规则。
面试者:如果请求被限制了,需要提示给用户吗?
面试官:需要提示,要给用户提供良好的体验。
面试者:好吧,那系统的规模是多大的?是单机还是分布式场景?
面试官:我们是 TOC 的产品, 系统流量很大,并且是分布式的环境, 所以限速器要支持海量请求。
面试者:(小声嘀咕)你这是造火箭呢?
我们总结一下限速器的设计要求:
- 低延迟,性能要好
- 需要适用于分布式场景。
- 用户的请求受到限制时,需要提示具体的原因。
- 高容错,如果限速器故障,不应该影响整个系统。
限速器应该放在哪里?
从系统整体的角度上来看,我们的限速器应该放在哪里?通常有三种选择,如下
客户端
是的,我们可以在客户端设置限速器。但是有个问题是,我们都知道在 Web 前端做一些限制实际上是不安全的,同样客户端也是一样的, 限速客户端可以做,但是远远不够。
服务端
在服务端设置限速器是很常见且安全的,如下

中间件
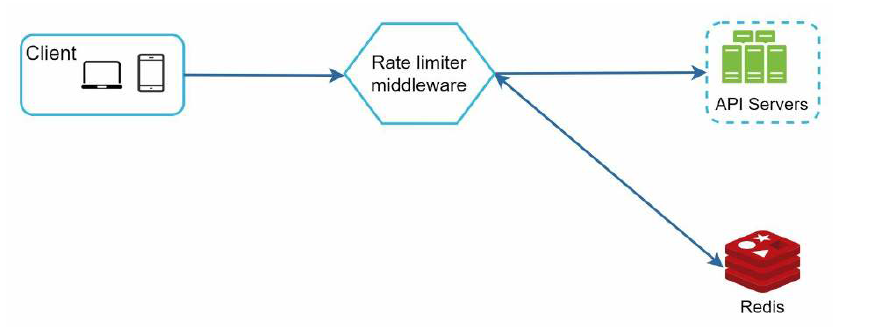
还有一种做法是,我们可以提供一个单独的限速中间件,如下
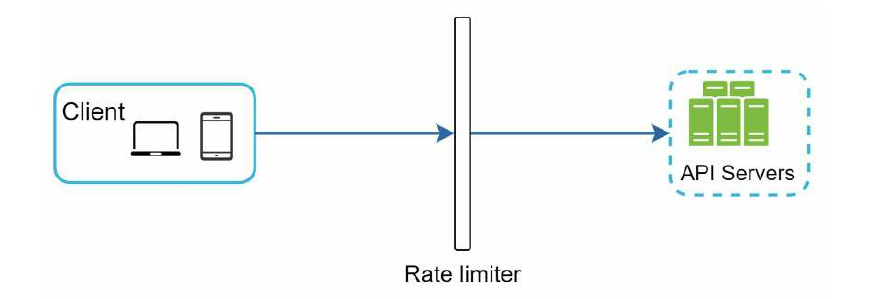
假如限速器设置了每秒最大允许2个请求,那么客户端发出的多余的请求就会被拒绝,并返回 HTTP 状态码 429, 表示用户发送了太多的请求。
实际上,很多网关都有限速的实现,包括认证、IP 白名单功能。
限速器应该放在哪里?没有固定的答案,它取决于公司的技术栈,系统规模。
限速算法
实际上,我们可以用算法实现限速器,下面是几种经典的限速算法,每种算法都有自己的优点和缺点,了解这些可以帮助我们选择更适合的算法。
- 令牌桶 (Token bucket)
- 漏桶(Leaking bucket)
- 固定窗口计数器(Fixed window counter)
- 滑动窗口日志(Sliding window log)
- 滑动窗口计数器(Sliding window counter)
令牌桶算法
令牌桶算法是实现限速使用很广泛的算法,它很简单也很好理解。
令牌桶是固定容量的容器。
一方面,按照一定的速率,向桶中添加令牌,桶装满后,多余的令牌就会被丢弃。
如下图,桶的容量为4,每次填充2个令牌。
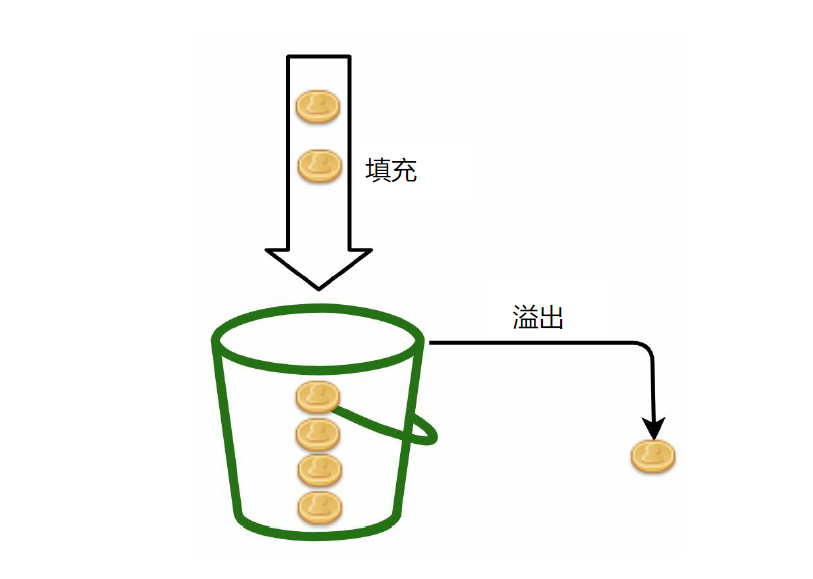
另一方面,一个请求消耗一个令牌,如果桶中没有令牌了,则拒绝请求。直到下个时间段,继续向桶中填充新的令牌。
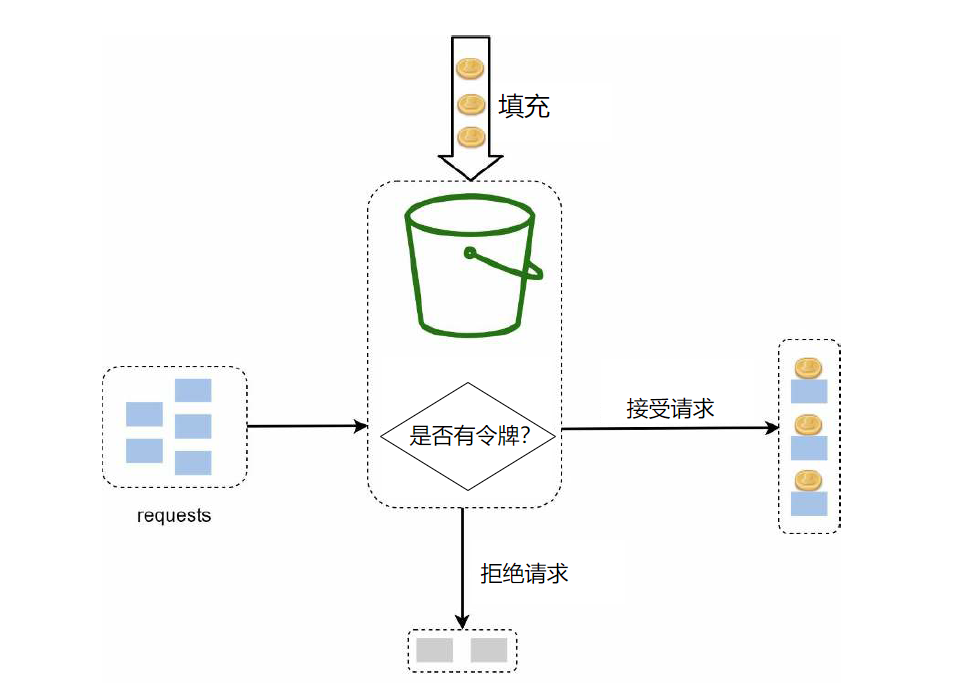
令牌桶算法有两个重要的参数,分别是桶大小和填充率,另外有时候可能需要多个桶,比如多个 api 限速的规则是不一样的。
令牌桶算法的优点是简单易实现,并且允许短时间的流量并发。缺点是,在应对流量变化时,正确地调整桶大小和填充率,会比较有挑战性。
漏桶算法
漏桶算法和令牌桶算法是类似的,同样有一个固定容量的桶。
一方面,当一个请求进来时,会被填充到桶里,如果桶满了,就拒绝这个请求。
另一方面,想象桶下面有一个漏洞,桶里的元素以固定的速率流出。
通常可以用先入先出的队列实现,如下图
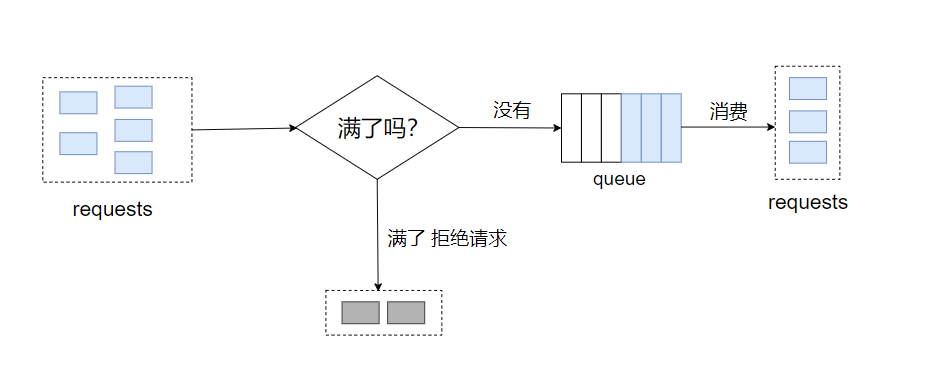
漏桶算法有两个参数,分别是桶大小和流出率,优点是使用队列易实现,缺点是,面对突发流量时,虽然有的请求已经推到队列中了,但是由于消费的速率是固定的,存在效率问题。
固定窗口计数器算法
固定窗口计数器算法的工作原理是,把时间划分成固定大小的时间窗口,每个窗口分配一个计数器,接收到一个请求,计数器就加一,一旦计数器达到设定的阈值,新的请求就会被丢弃,直到新的时间窗口,新的计数器。
让我们通过下面的例子,来看看它是如何工作的。一个时间窗口是1秒,每秒最多允许3个请求,超出的请求就会被丢弃。
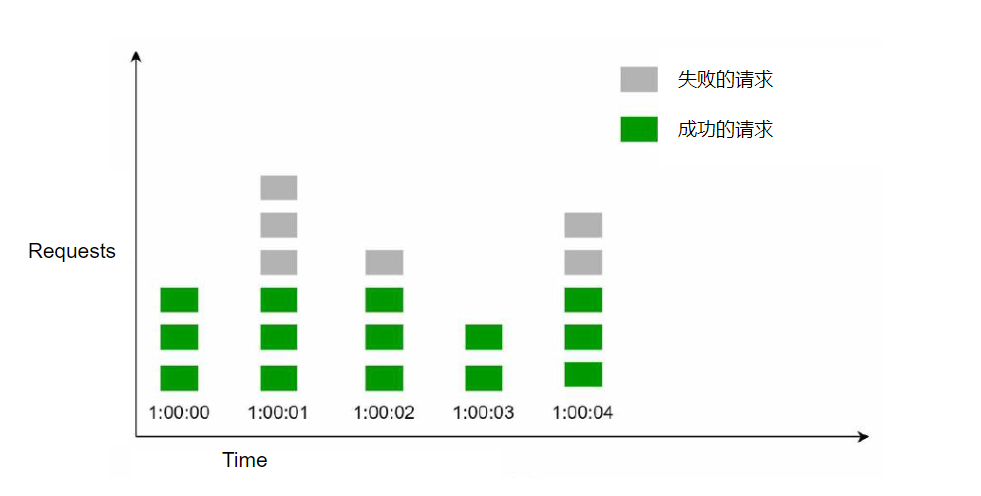
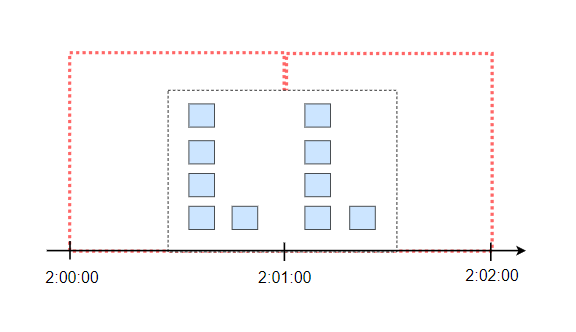
不过这个算法有一个问题是,如果在时间窗口的边缘出现突发流量时,可能会导致通过的请求数超过阈值,什么意思呢?我们看看下面的情况
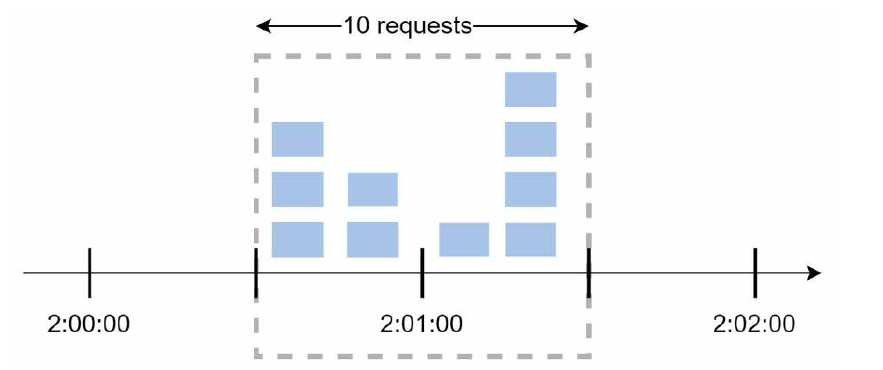
一个时间窗口是1分钟,每分钟最多允许5个请求。如果前一个时间窗口的后半段有5个请求,后一个时间窗口的前半段有5个请求,也就是 2:00:30 到 2:01:30 的一分钟内,是可以通过10个请求的,这明显超过了我们设置的阈值。
固定窗口计数器的优点是,简单易于理解,缺点是,时间窗口的边缘应对流量高峰时,可能会让通过的请求数超过阈值。
滑动窗口日志算法
我们上面看到了,固定窗口计数器算法有一个问题,在窗口边缘可能会突破限制,而滑动窗口日志算法可以解决这个问题。
它的工作原理是,假如设定1分钟内最多允许2个请求,每个请求都需要记录请求时间,比如保存在 Redis 的 sorted sets 中,保存之后还需要删除掉过时的日志,过时日志是如何定义的?比如某次请求的时间是 1:01:36,那么往前推1分钟,1:00:36 之前的日志都算过时的,需要从集合中删掉。同时,判断集合中的数量是否大于阈值,如果大于2则丢弃请求,如果小于或等于2,则处理这个请求。
让我们看看下面的例子
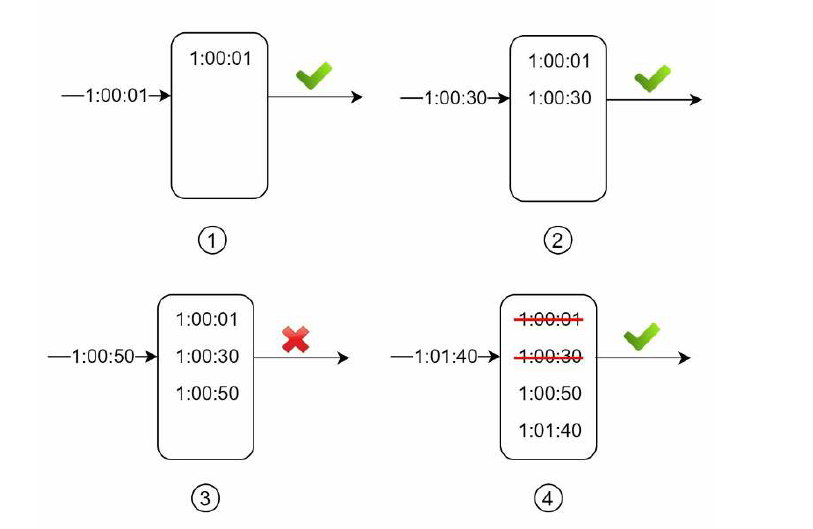
- 在 1:00:01 来了一个请求,第一步,记录请求时间到日志中,第二步,判断是否有过时的日志, 也就是 0:59:01 之前的日志,明显没有,第三步判断日志中的数量,没有大于2,处理这次请求。
- 在 1:00:30 来了一个请求,执行上面的三个步骤,最后处理这次请求。
- 在 1:00:50 的新请求,没有过时的日志,然后发现日志的数量为3,拒绝这次请求。
- 在 1:01:40 的新请求,清除2条过时的日志,也就是 1:00:40 之前的日志,此时,日志中的数量为2,处理这次请求。
这个算法实现的限速非常准确,但是它可能会消耗较多的内存。
滑动窗口计数器算法
滑动窗口计数器可以说是固定窗口计数器的升级版,上面提到了,固定窗口计数器存在窗口边缘可能会有超出限制的情况,如下
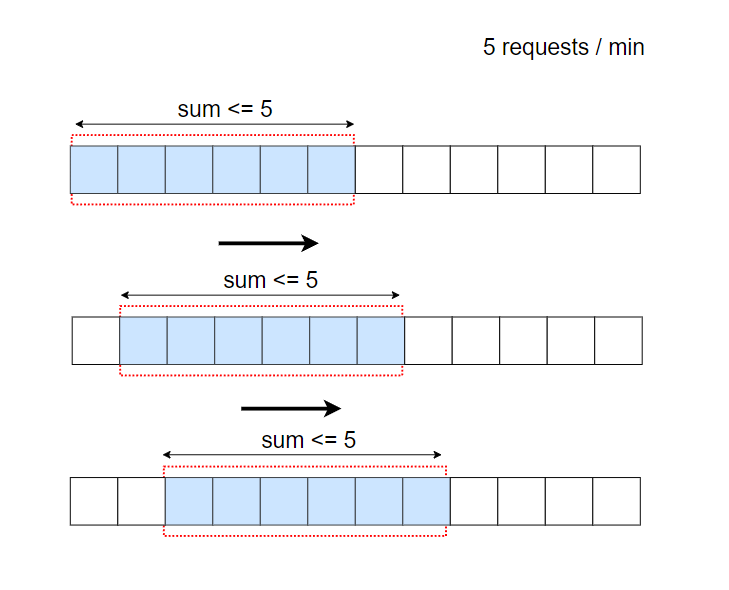
而滑动窗口把固定的窗口又分成了很多小的窗口单位,比如下图,每个固定窗口的大小为1分钟,又拆分成了6份,每次移动一个小的单位,保证总和不超过阈值。
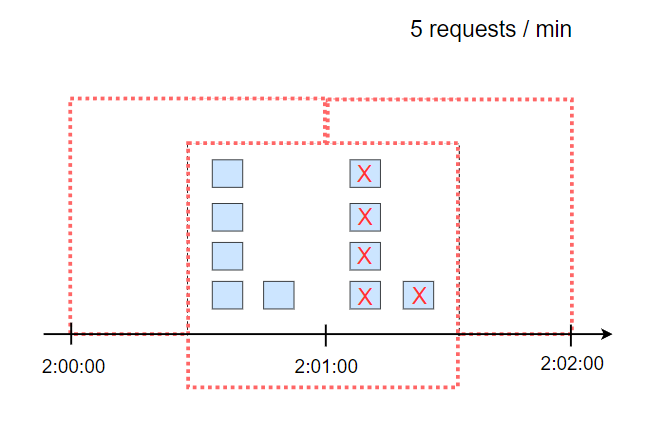
这样就可以避免上面的窗口边缘超出限制的问题。
使用 Redis 实现高效计数器
限速器算法的思想其实很简单,我们需要使用计数器记录用户的请求,如果超过阈值,服务这个请求,否则,拒绝这个请求。
一个很重要的问题是,我们应该把计数器放在哪里?我们知道,磁盘速度比较慢,使用数据库明显是不太现实的方案,想要更快的话,可以使用内存缓存,最常见的就是 Redis,是的,我们可以使用 Redis 实现高效计数器,如下
规则引擎
Lyft 是一个开源的限速组件,可以供我们参考,它通过 Yaml 配置文件实现灵活的限速规则,看下面的示例
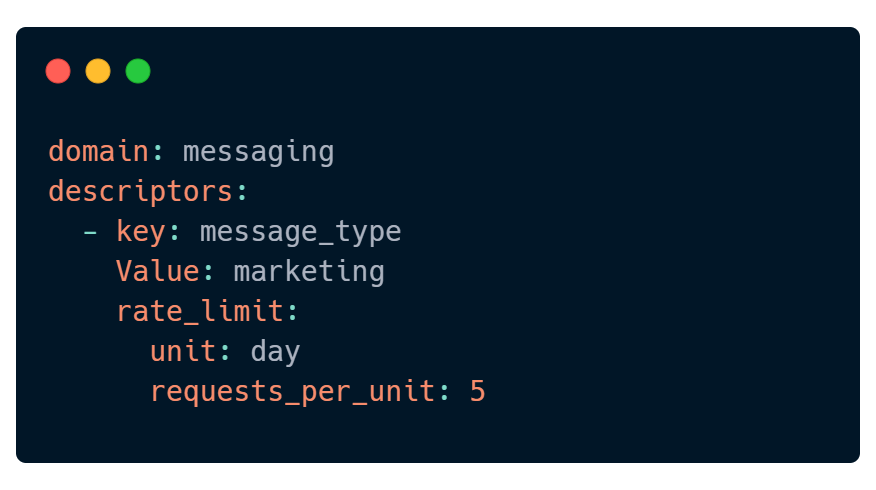
这个配置表示系统每天只能发送 5 条营销信息。
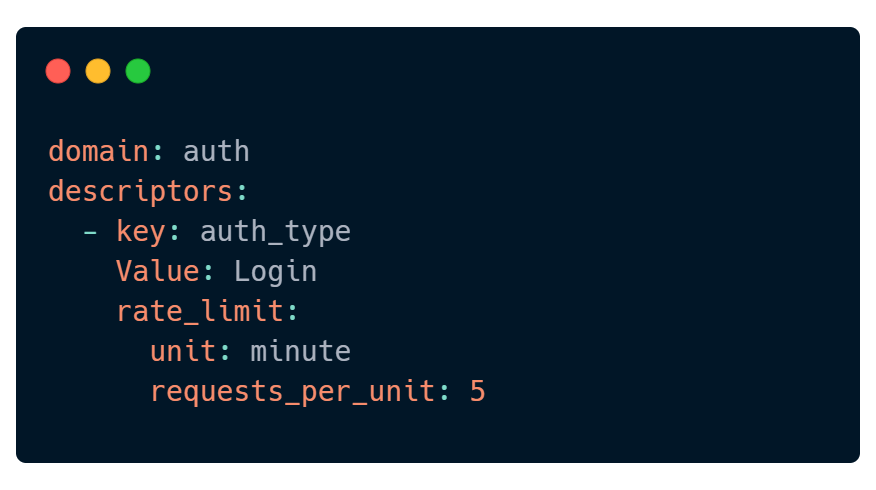
这个配置表示 1分钟的登录次数不能超过 5 次。
可以看到,基于配置文件,声明式的限速规则是非常灵活的,我们可以把配置文件保存到磁盘中。
返回限速信息
当请求超过限制时,限速器会拒绝掉其他的请求,这样其实不够,为了更好的用户体验,我们需要返回友好的错误信息给用户,并提示。
首先,限速器拒绝请求后,可以返回 HTTP 状态码 429,表示请求过多。
其次,我们可以返回更详细的信息,比如,剩余请求次数、等待时间等。一种很常见的做法时,把这些信息放到 Http 响应的 Header 中返回,如下
- X-Ratelimit-Remaining:表示剩余次数
- X-Ratelimit-Limit:表示客户端每个时间窗口可以进行多少次调用
- X-Ratelimit-Retry-After:表示等待多长时间可以进行重试
看起来不错!让我们看看现在的架构设计
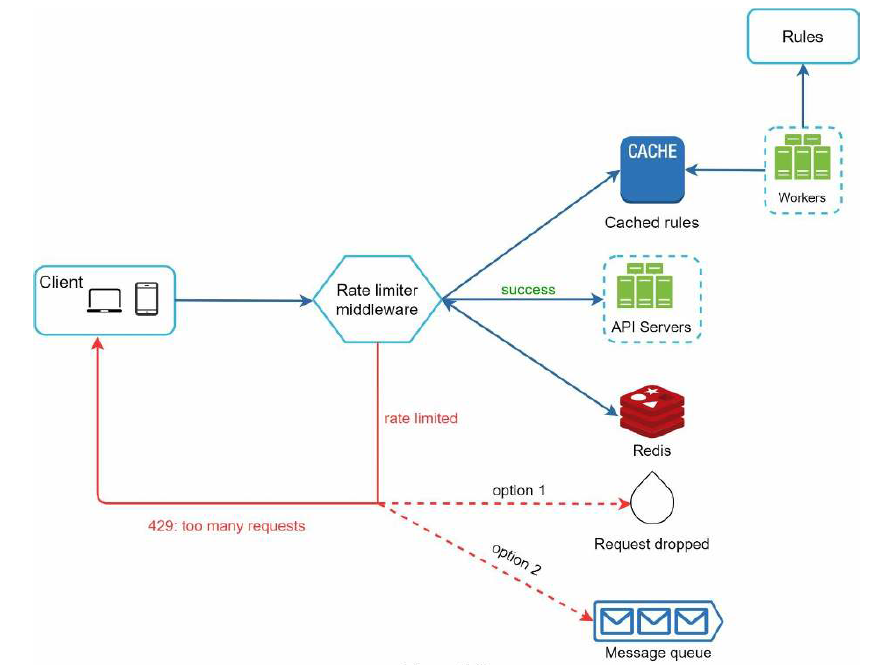
首先,限速规则存储在磁盘上,因为要经常访问,可以添加到缓存中。当客户端向服务器发送请求时,会先发送到限速中间件。限速中间件从缓存中拉取限速规则,同时把请求数据写入到 Redis 的计数器,然后判断是否超出限制。如果没有超出限制,把请求转发给我们的后端服务器。如果超出了限制,第一种方案,丢弃多余的请求,返回 429,第二种方案,把多余的请求推送到消息队列中,后续再进行处理。使用哪种方案,取决于您的实际场景。
分布式环境
构建一个在单服务器运行的限速器是很简单的,但是在分布式环境中,支持多台服务器,那就完全是另外一回事了。
我们主要要考虑两个问题:
- 并发问题
- 数据同步问题
并发问题,我们的限速器的工作原理是,当接收到新的请求时,从 Redis 中读取计数器 counter,然后做加一的操作,在高并发场景中,可能存在多个线程读到了旧的值,比如,两个线程同时读取到 counter 的值为3,然后都把 counter 改成了4,这样是有问题的,其实最终应该是 5。
有朋友说,我们可以用锁,但实际上,锁的效率是不高的。解决这个问题通常有两个方案,第一个是使用 Lua 脚本,第二个是使用 Redis 的 sorted sets 数据结构,具体的细节本文不做过多介绍。
数据同步问题,在流量比较大的情况下,一个限速器是难以支撑的,我们需要多个限速器。由于 Web 层通常是无状态的,客户端的请求会随机发送给不同的限速器,如下
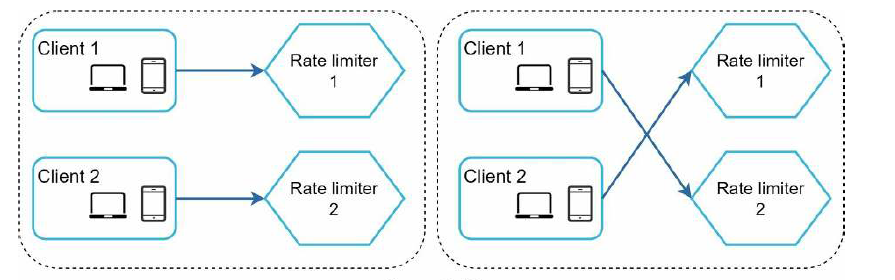
这种情况下,如果没有数据同步,我们的限速器肯定是没办法正常工作的。
我们可以使用像 Redis 这样的集中式数据存储,如下
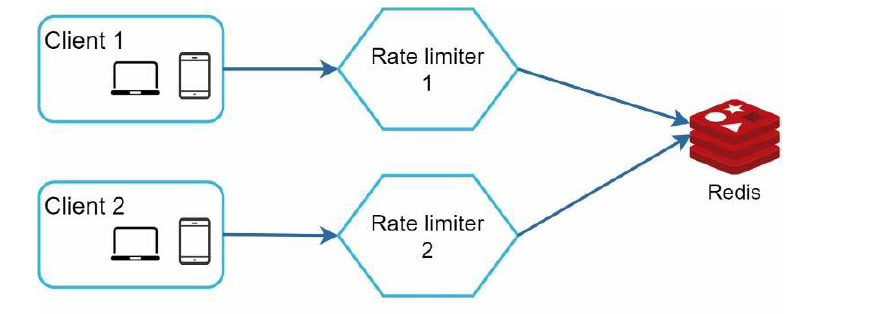
性能优化
当我们的系统是面向全球用户时,为了让各个地区的用户都能有一个不错的体验,通常会在不同的地区设置多个数据中心。另外,现在很多云服务商在全球各地都有边缘服务器,流量会自动路由到最近的边缘服务器,来减少网络的延迟。
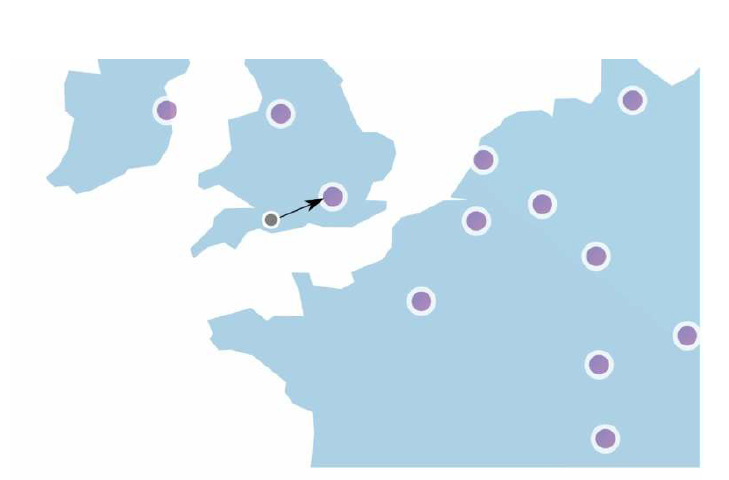
当然,存在多个数据中心时,可能还要考虑到数据的最终一致性。
总结
在本文中,我们讨论了不同的限速算法,以及它们有优缺点,算法包括:
- 令牌桶
- 漏桶
- 固定窗口计数器
- 滑动窗口日志
- 滑动窗口计数器
然后,我们讨论了分布式环境中的系统架构,并发问题和数据同步问题,和灵活配置的限速规则,最后你会发现,实现一个限速器,其实没有那么难!
希望对您有用!
译:等天黑
作者:Alex Xu
来源:《System Design Interview》
简介: Alex Xu 是一位经验丰富的软件工程师, 曾在 Twitter, Apple 和 Oracle 任职,来自CS名校卡内基梅隆大学,热衷于系统设计。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号