
分布式系统中的领导选举
领导选举是分布式系统中最棘手的事情之一。同时,理解 Leader 是如何选举产生的以及leader的职责,是理解分布式系统的关键。
在分布式系统中, 通常一个服务由多个节点或实例组成服务集群, 提供可扩展性、高可用的服务。
这些节点可以同时工作, 提升服务处理、计算能力,但是,如果这些节点同时操作共享资源时,那就必须要协调它们的操作,防止每个节点覆盖其他节点所做的更改,从而产生数据错乱的问题。
所以,我们需要在所有节点中选出一个领导者 Leader, 来管理、协调集群的所有节点,这种也是最常见的 Master-Slave 架构。
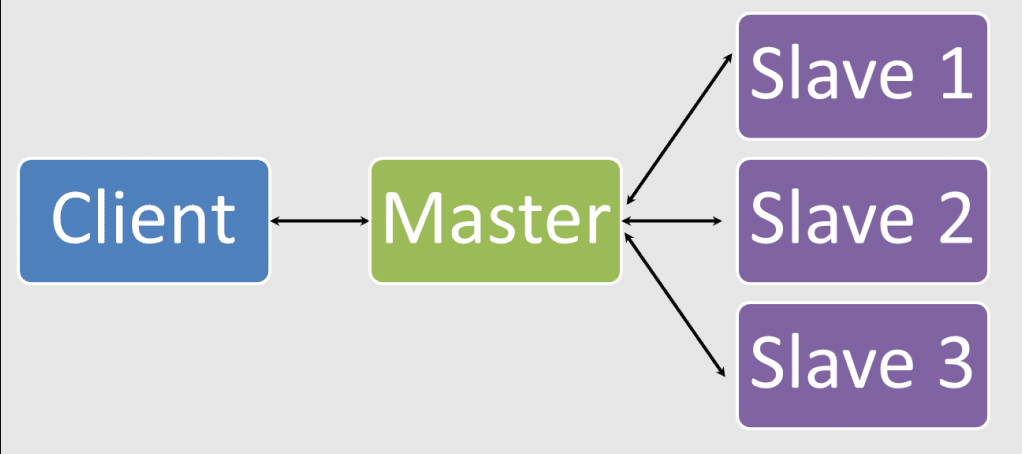
在分布式环境中的多个节点中选取主节点 Leader,通常会使用以下几种策略:
- 根据进程 Id 或者实例 Id,选择最大值,或者最小值作为主节点。
- 实现一种常见的领导者选举算法,比如 Raft,Bully 等。
- 通过分布式互斥锁,保证只有一段时间只有一个节点可以获取到锁,并成为主节点。
在本文中,我会介绍几种常见的选举算法,包括 Raft、ZAB、Bully、Token Ring Election,当然上面的一些算法中,领导选举只是其中一部分的功能,像 Raft 其实是共识算法, 所以,不要把他们的概念给搞混了。
Bully 算法
Garcia-Monila 在 1982 年的一篇论文中发明了 Bully 算法,这是分布式系统中很常见的选举算法,它的选举原则是“长者”为大,也就是在所有存活的节点中,选取 ID 最大的节点作为主节点。
假如有一个集群, 各个节点可以相互连接,并且每个节点都知道其他节点的信息( Id 和节点地址),如下:
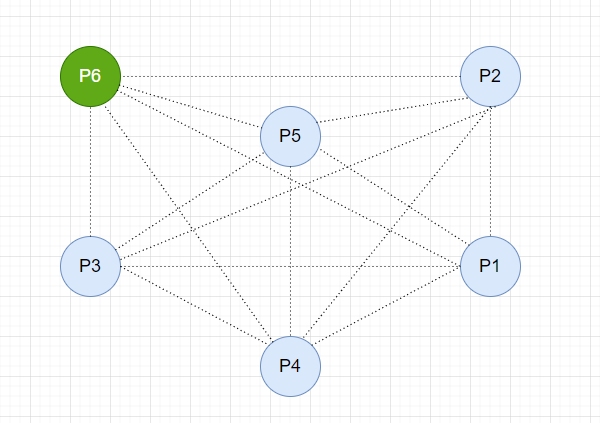
集群初始化时,各个节点首先判断自己是不是存活的节点中 ID 最大的,如果是,就向其他节点发送 Victory 消息,宣布自己成为主节点,根据规则,此时,集群中的 P6 节点成为 Master 主节点。
现在集群中出现了一些故障,导致节点下线。如果下线的是从节点, 集群还是一主多从,影响不大, 但是如果下线的是 P6 主节点,那就变成了一个群龙无首的场面。
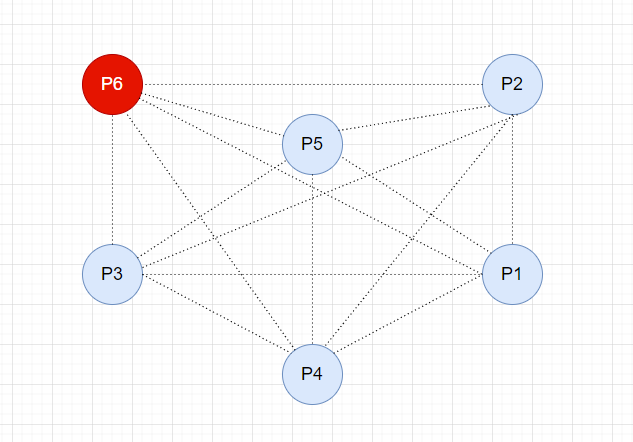
现在我们需要重新选举一个主节点!
我们的节点是可以相互连接,并且节点间定时进行心跳检查, 此时 P3 节点检测到 P6 主节点失败,然后 P3 节点就发起了新的选举。
首先 P3 会向比自己 ID 大的所有节点发送 Election 消息。
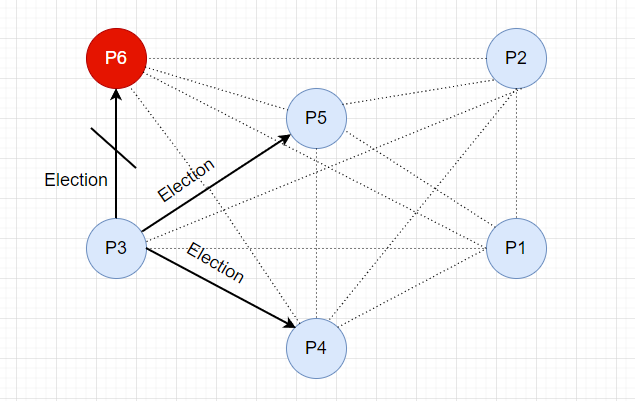
由于 P6 已经下线,请求无响应,而 P4,P5 可以接收到 Election 请求,并响应 Alive 消息。P3 节点收到消息后,停止选举,因为现在有比自己 Id 大的节点存活,他们接管了选举。
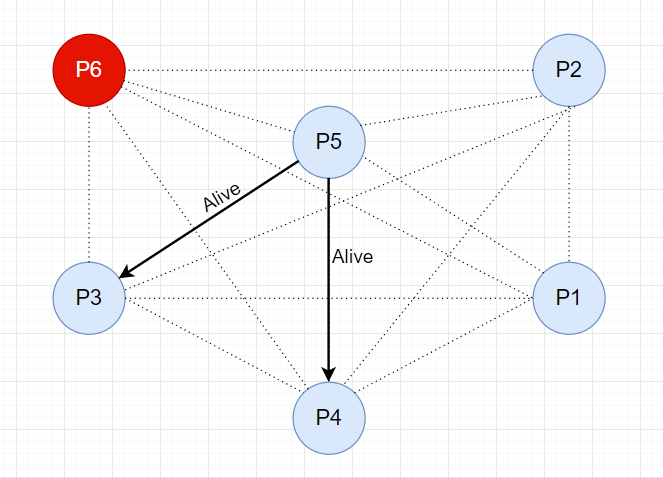
接下来,P4 节点向 P5 和 P6 节点发送选举消息。
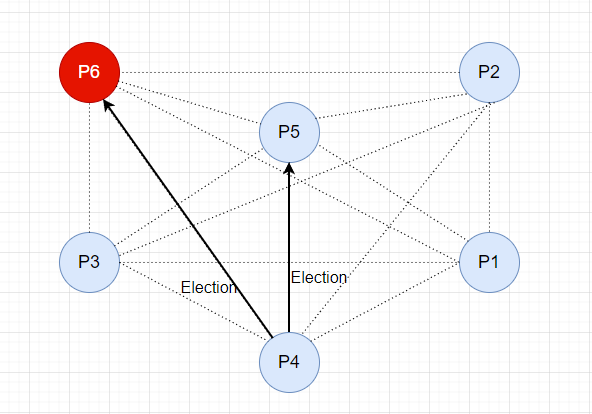
P5 节点响应 Alive 消息,并接管选举。
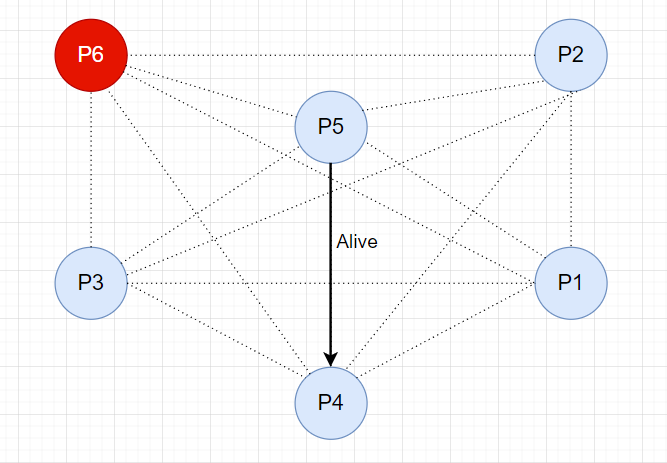
同样,P5 节点向 P6 节点发送选举消息。
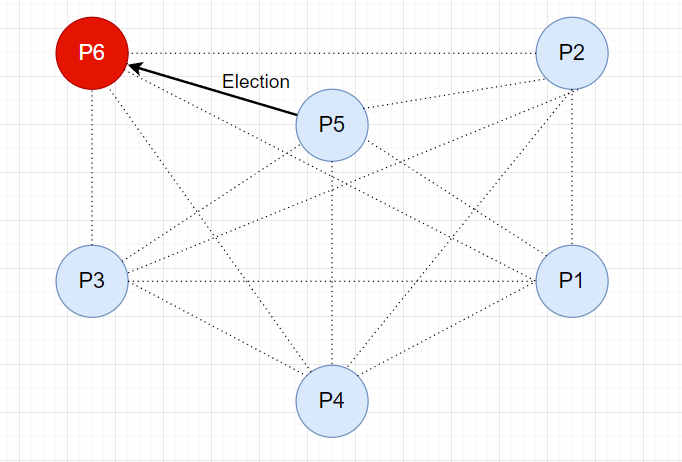
此时,P6 节点没有响应,而现在 P5 是存活节点中 ID 最大的节点,所以 P5 理所应当成为了新的主节点,并向其他节点发送 Victory 消息,宣布自己成为 Leader !
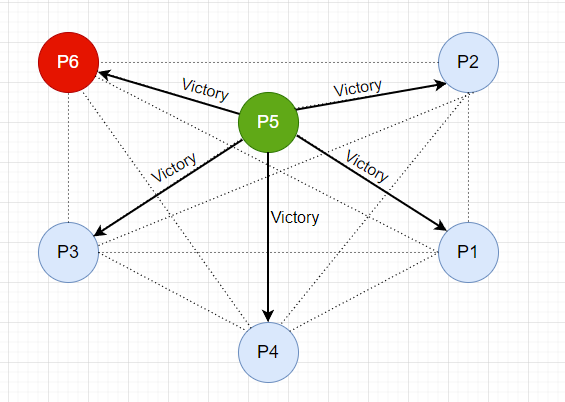
一段时间后,故障恢复,P6 节点重新上线,因为自己是 ID 最大的节点, 所以直接向其他节点发送 Victory 消息,宣布自己成为主节点,而 P5 收到比自己 ID 大的节点发起的选举请求后,降级变成从节点。
Token Ring 选举算法
Token Ring Election 算法和集群节点的网络拓扑有较大关系,它的特点是,所有的节点组成一个环,而每个节点知道下游节点,并能与之通信,如下
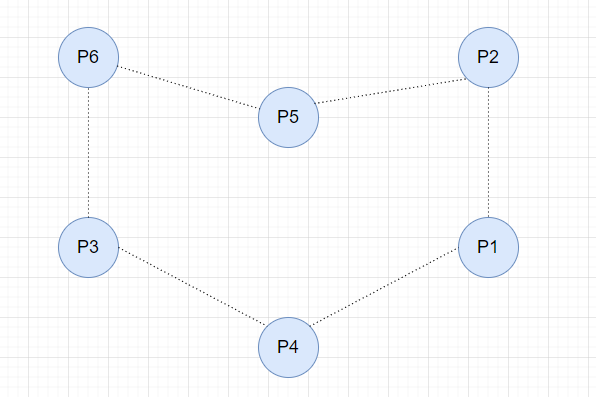
集群初始化的时候,其中一个节点会向下一个节点先发起选举消息,其中包含了当前节点的 ID,下一个节点收到消息后,会在消息中附加上自己的 ID,然后继续往下传递,最终形成闭环。
本次选举从 P3 节点发起。
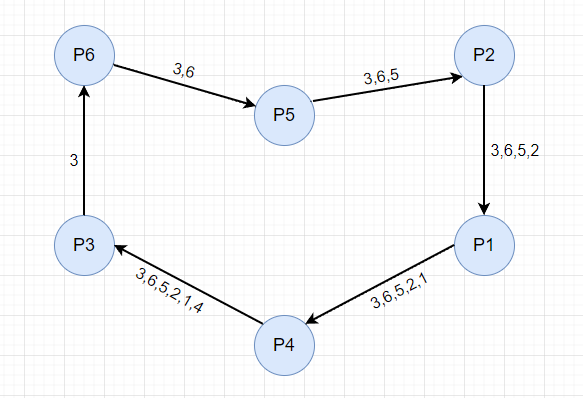
P3 节点收到 P4 的消息后,发现消息中包含自己的节点 ID,可以确定选举消息已经走了整个环,这时还是按照 “长者为大” 的原则,从消息 "3,6,5,2,1,4" 中选取最大的 Id 为主节点,也就是选举 P6 为 Leader。
接下来,P3 节点向下游节点发送消息,宣布 P6 是主节点,直到消息走了整个环,回到 P3,至此,本次选举完成。
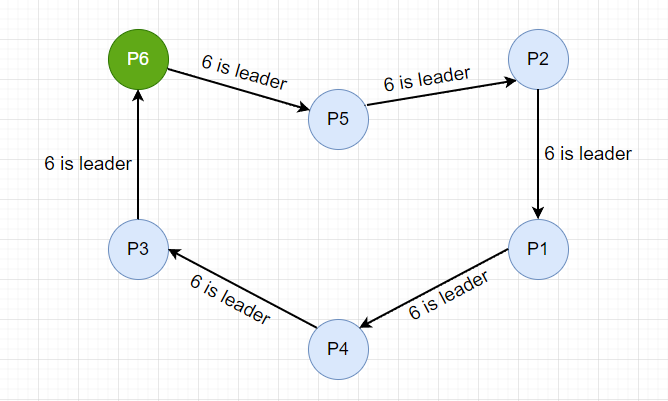
现在集群中出现了一些故障, 导致主节点 P6 下线,位于上游的 P3 节点首先发现了(通过心跳检查),然后 P3 节点重新发起选举,当下游的 P3 节点无法连接时,会尝试连接下游的下游节点 P5,发送选举消息,并带上自己的节点 Id,消息逐步往下游传递。
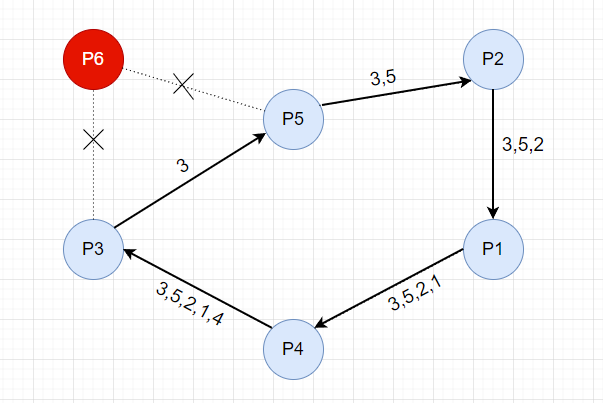
直到选举消息重新回到 P3 节点,从 "3,5,2,1,4" 节点列表中选取最大的 ID,也就是现在 P5 成为主节点。
接下来,P3 节点向下游节点发送消息,宣布 P5 是主节点。
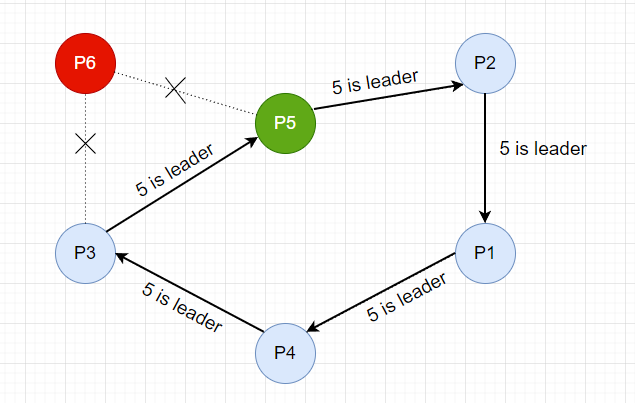
直到消息走了整个环,回到 P3,至此,本次选举完成。
Raft 共识算法
Raft 是一个比较新的算法, 它是斯坦福大学的 Diego Ongaro 和 John Ousterhout 开发的,并在 2014年发表论文, Raft 的设计就是为了让大家能更好地理解并实现共识,因为它的前身,就是 Lesli Lamport 开发的大名鼎鼎的 Paxos 算法,但是这个算法非常难以理解和实现, 所以,Diego 的论文标题是 “寻找可理解的共识算法”,更容易理解并且更容易实现,同时 Raft 也是分布式环境中使用最为广泛的共识算法。
Raft 的领导选举属于多数派投票选举算法,和其他选举算法的 "长者为大" 的原则不同, 它的原则是 "众生平等",核心思想是 “少数服从多数”, 也就是说,Raft 算法中,获得投票最多的节点成为主。
在 Raft 的领导选举中,定义了集群中的节点有三个角色
- Leader 领导者,负责协调和管理其他节点
- Follower 领导的跟随者
- Candidate 候选者,发起选举投票,它是从 Follower 到 Leader 的过渡状态

让我们看看 Raft 中的领导选举是怎样执行的!
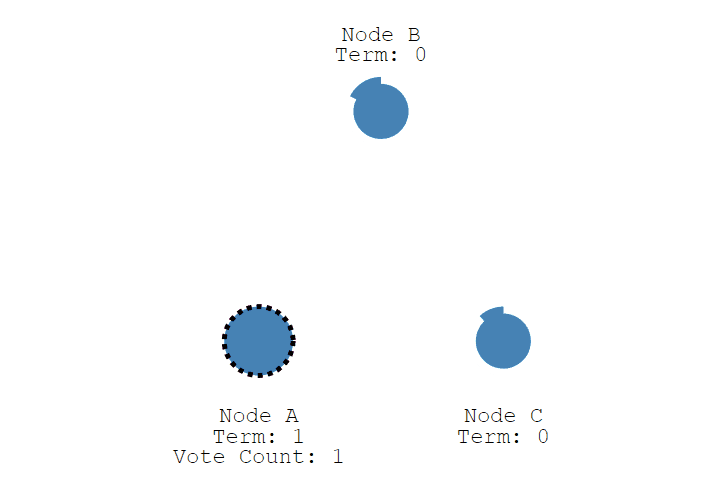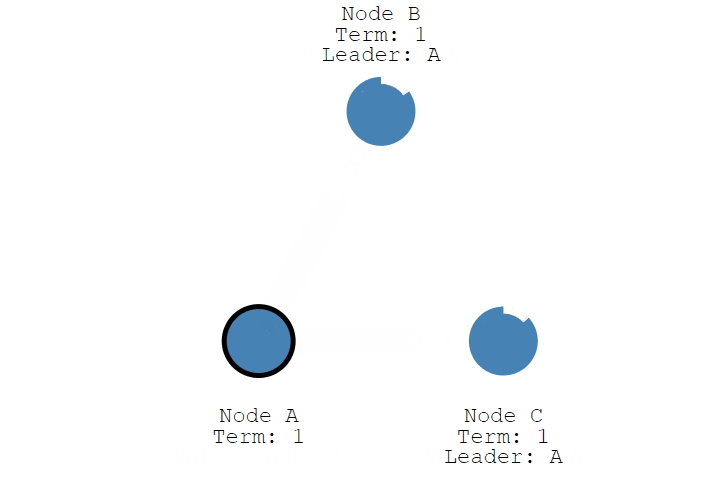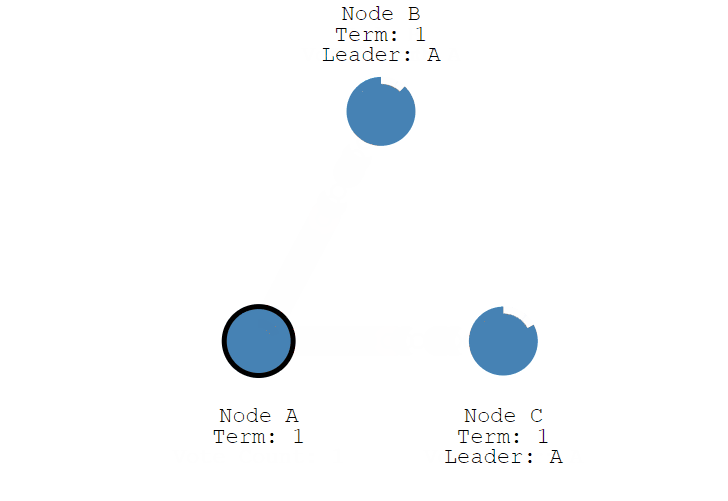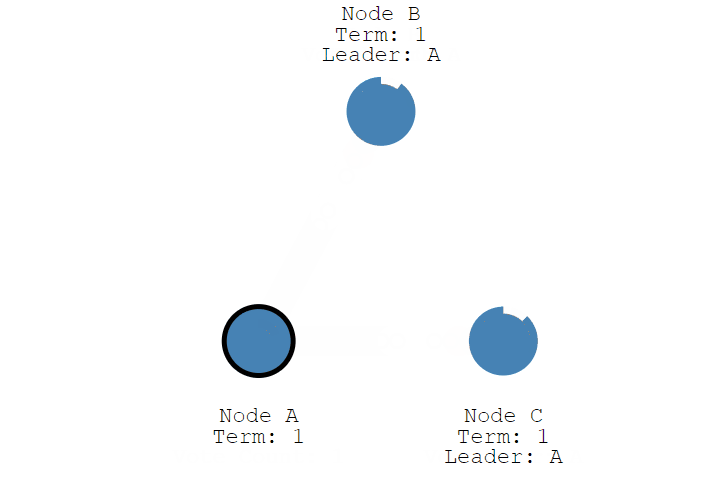
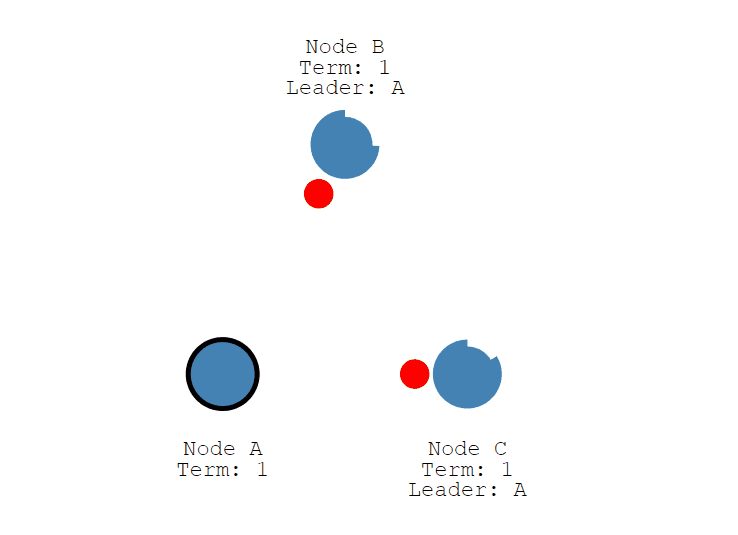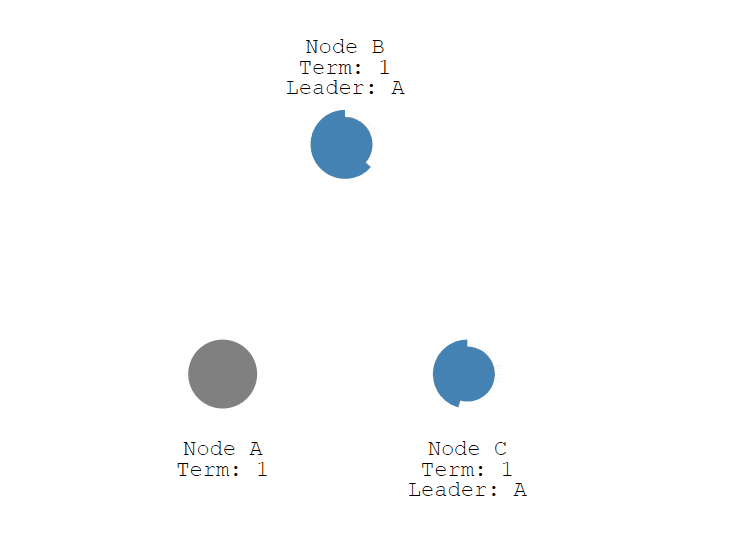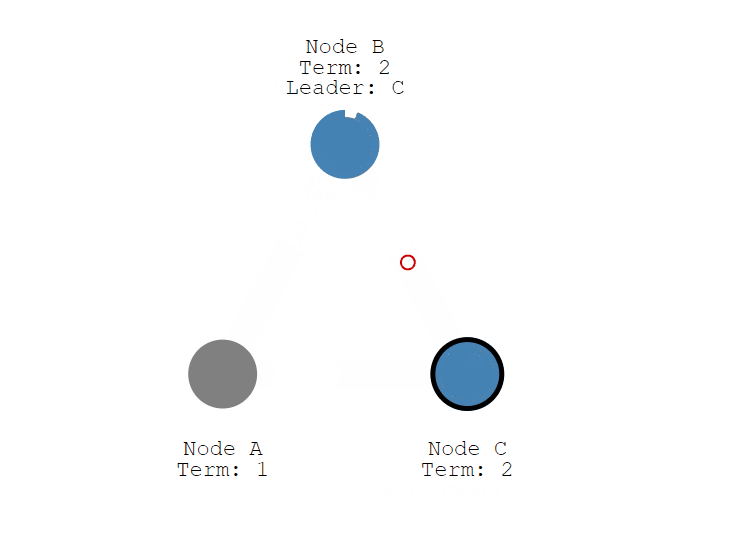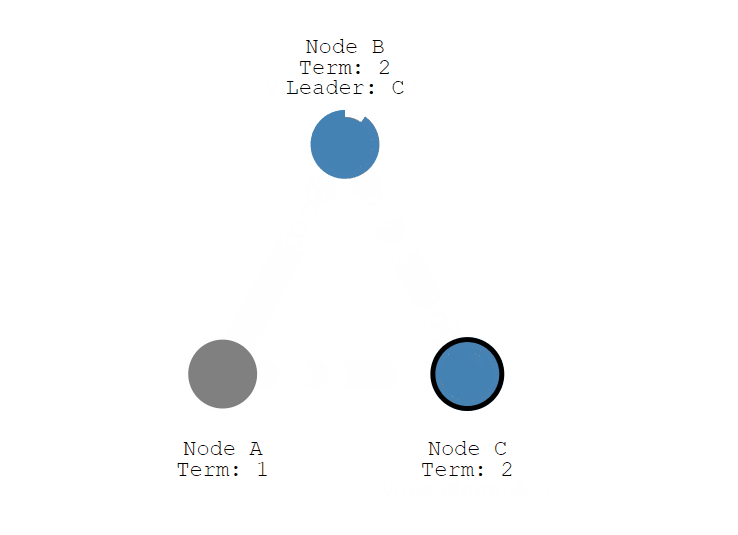
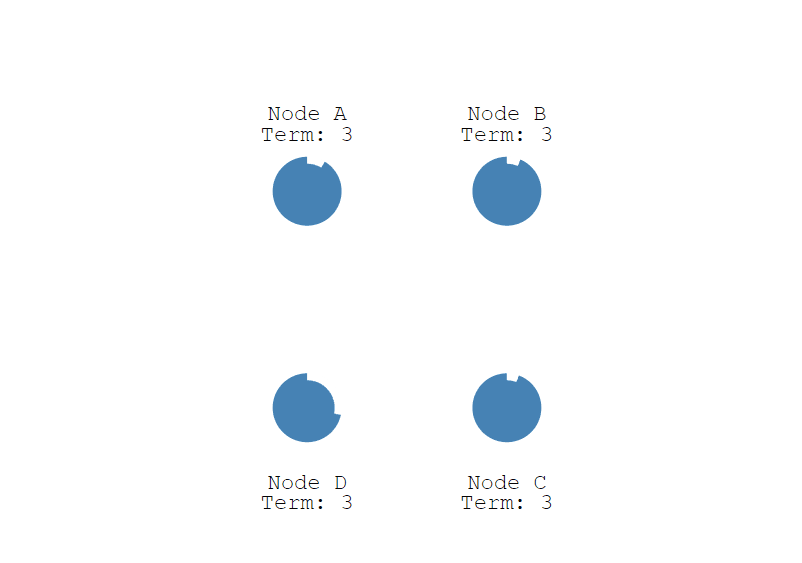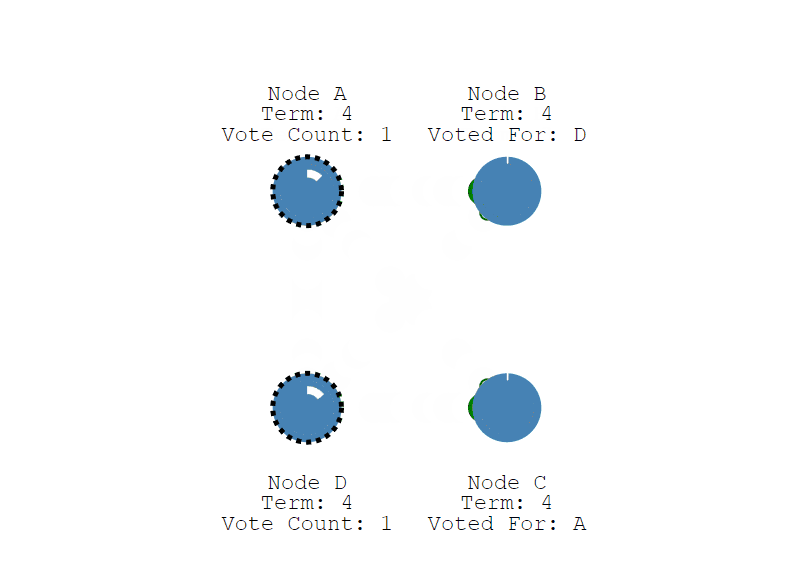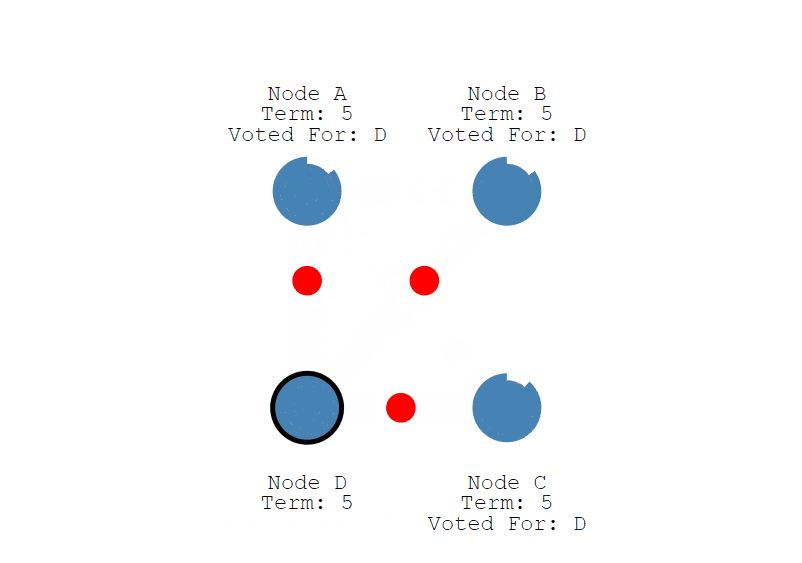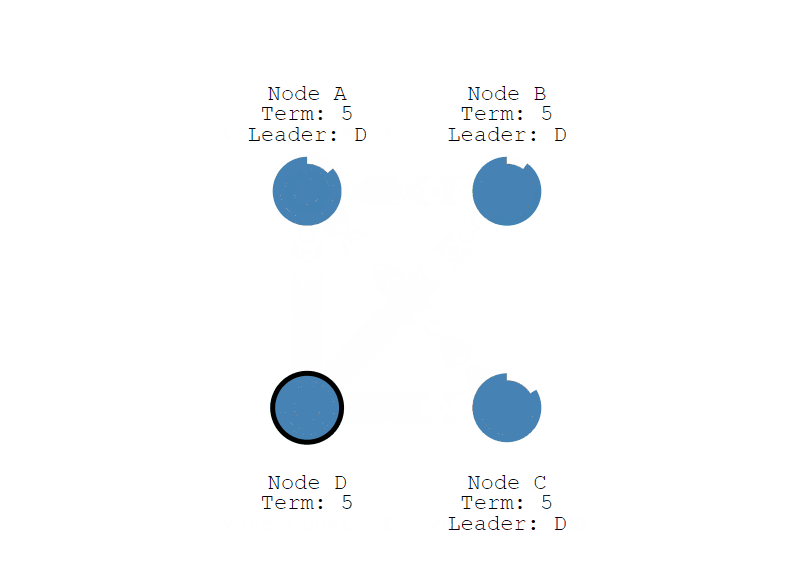
初始状态下,集群中有三个节点,Node A, B,C,它们现在都是 Follower
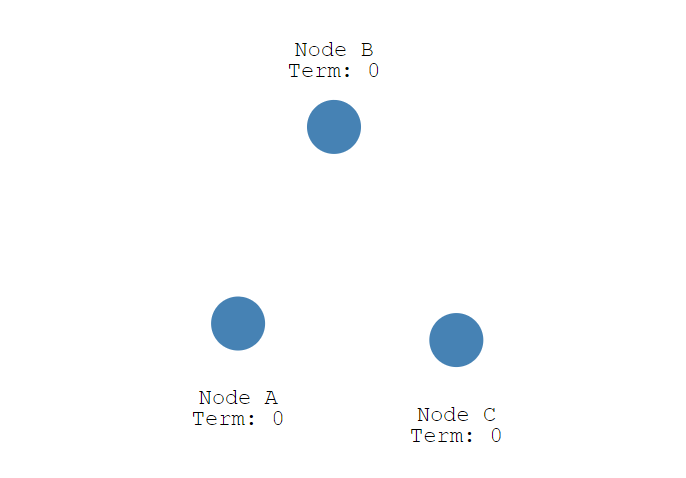
首先,每个节点随机生成 150 毫秒到 300 毫秒之间的时间值, 也就是选举超时(election timeout)设置, 并进行等待,超时后,节点会从 Follower 变成 Candidate , 下图中 Node A 首先变成了 Candidate,给自己投了一票,并开始了新的任期 (Term)。
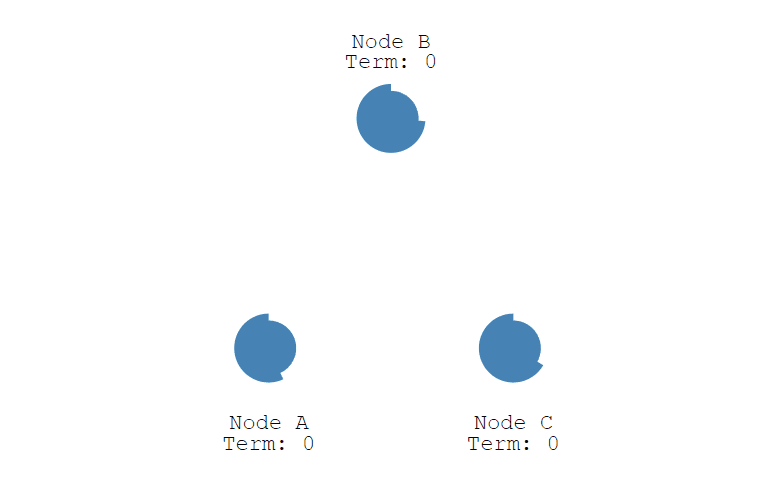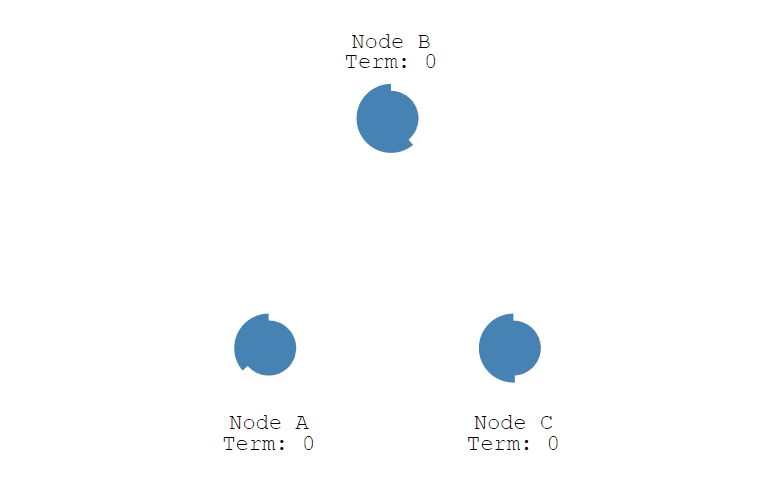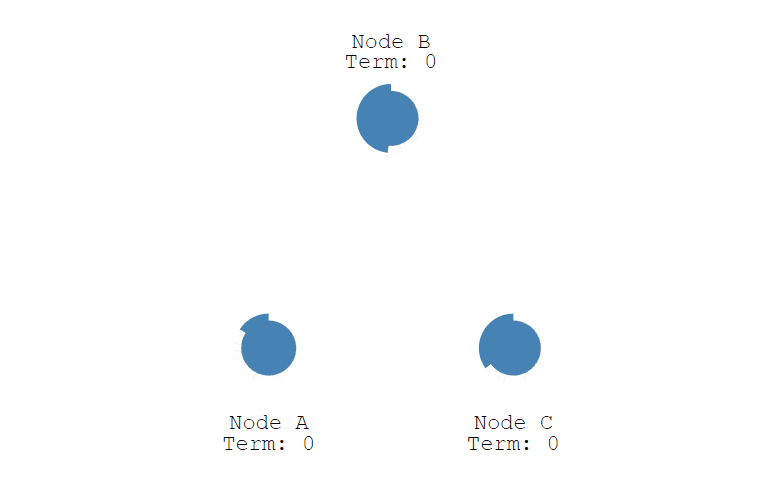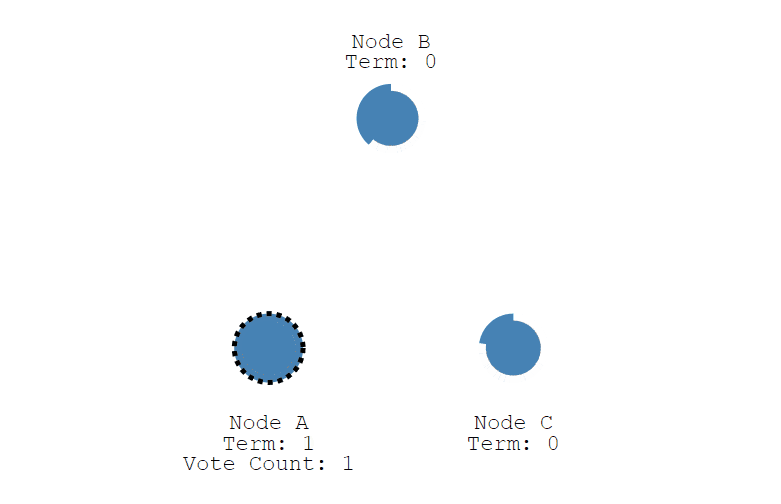
等等,什么是任期 (Term)?在 Raft 中,它是一个数字编号,初始化为 0,当一个节点从 Follower 变成 Candidate 时,就把当前的任期编号加1,而从 Candidate 变成 Follower 时,任期编号不加也不减,可以理解它就是一个递增计数器。
任期由每个节点在本地管理,同时,每次和其他节点通信时会带上它(任期号),如果接收到比自己大的任期号时,会更新自己的任期号到最新,如果接收到比自己小的任期号,就把自己的任期号返回,让对方节点去更新。
任期有什么用?
因为每次选举任期都会累加,在时间上来说,一个小的任期一定是在一个大的任期之前产生的,所以也就可以通过任期的大小确定事件的发生顺序,这样在应对节点的选举冲突时,就可以通过比较任期来推断,两次选举发生的先后顺序。
比如,由于网络分区问题,可能导致产生两个 Leader,也就是我们常说的脑裂现象,如果两个 Leader 同时处理数据,就会产生数据一致性问题,这种情况就可以比较任期号,比较小的就降级为 Follower 。
等等,不就是确定事件发生顺序吗?为什么搞这么麻烦?不应该用时间吗?实际上,要保证分布式环境中多个节点的时间绝对一致可不是个简单的事情,即使我们有 NTP 时间同步协议, 因为时间同步后就算只有几毫米的误差,也有可能会打乱事件的发生顺序。
所以,Raft 中任期的机制就是解决分布式环境的事件顺序问题,也就是 逻辑时钟 ,或者在分布式中我们更普遍地称为 epoch,在不使用物理时间的情况下,来确定事件的发生顺序。
接下来,我们继续看选举过程,上面说到 节点 A 变成了 Candidate 候选者,给自己的任期 Term + 1 ,并投了自己一票,然后会向其他节点发送投票消息,如果接收节点在自己的任期内还没有投过票,就会把票投给候选人 ,并重置自己的选举超时 (election timeout), 注意,一个节点一个任期只能投一次,现在节点 A 有了 3票,符合 "过半原则", 现在节点 A 从Candidate 变成了 Leader,并向 Follower 节点定时发送心跳,维持状态,Follower 节点收到后,同样也会重置自己的选举超时 (election timeout)。
让我们看看 Leader 节点下线会发生什么?
节点 A 下线后,B 和 C 的选举超时 (election timeout) 不会被重置,并且很快会超时,此时,节点 C 首先从 Follower 变成了 Candidate, 然后任期(Term)变成 2,投了自己一票,并发送选举消息,节点 B 收到后,因为没有投过票,就把票投了 节点C,现在节点 C 变成了 Leader。
我们上面说了,Raft 中的选举超时是随机的150毫秒到300毫秒,那就有一定的概率,两个节点同时成为 Candidate,产生分裂选举, 同时发起投票,并且获得的同样的票数,那怎么办呢?注意, 如果 Candidate 获得的票没有过半,就不会产生 Leader,那就重新选举一次,直到票数过半,成为 Leader。
ZAB - ZooKeeper 的原子广播协议
众所周知,Apache ZooKeeper 是云计算的分布式框架, 它的核心是一个基于 Paxos 实现的原子广播协议(ZooKeeper Atomic Broadcast),但实际上它既不是 Basic-Paxos 也不是 Multi-Paxos。
目前在 ZooKeeper 中有两种领导选举算法:LeaderElection 和 FastLeaderElection(默认), 而 FastLeaderElection 选举算法是标准的 Fast-Paxos算法实现。
下面我会介绍 ZAB 协议中的领导选举的实现。
首先,我们有三个节点,S1,S2,S3 , 每个节点在本地都有一份数据和投票箱,数据包括myid, zxid 和 epoch。
- myid 每个节点初始化的时候需要配置自己的节点 Id,不重复的数字
- epoch 选举的轮数,默认为0,选举时做累加操作,和 Raft 中的任期是一样的,也就是逻辑时钟, epoch 的大小可以表示选举的先后顺序
- zxid ZooKeeper 的全局事务Id, 64位不重复的数字,前 32 位是 epoch,后32位是 count 计数器, zxid 是怎么做到全局唯一的呢?实际上集群选中 Leader 后,一个写的操作,首先会统一在 Leader 节点递增 zxid,然后同步到 Follower 节点,在一个节点上保证一个数字递增并且不重复就简单多了, zxid 的大小可以表示事件发生的先后顺序。
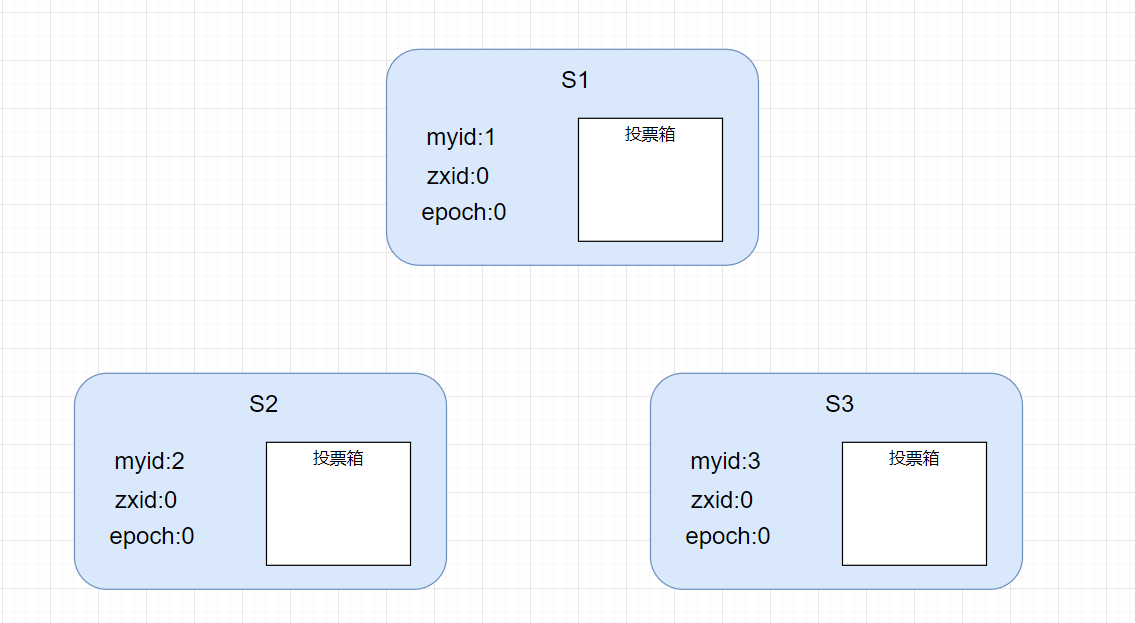
现在开始投票,投票内容就是上面说的节点的本地数据,【myid,zxid,epoch】, 每个节点先给自己投一票,并放到自己的投票箱,然后把这张票广播到其他节点。
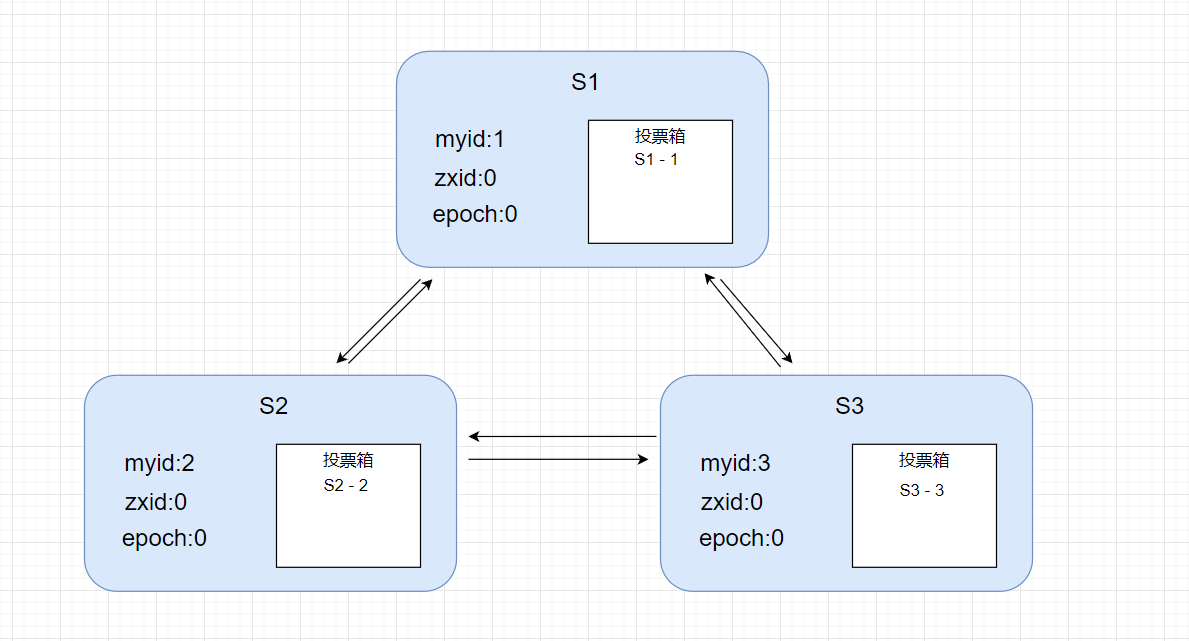
一轮投票交换后,现在,每个节点的投票箱都有所有节点的投票。
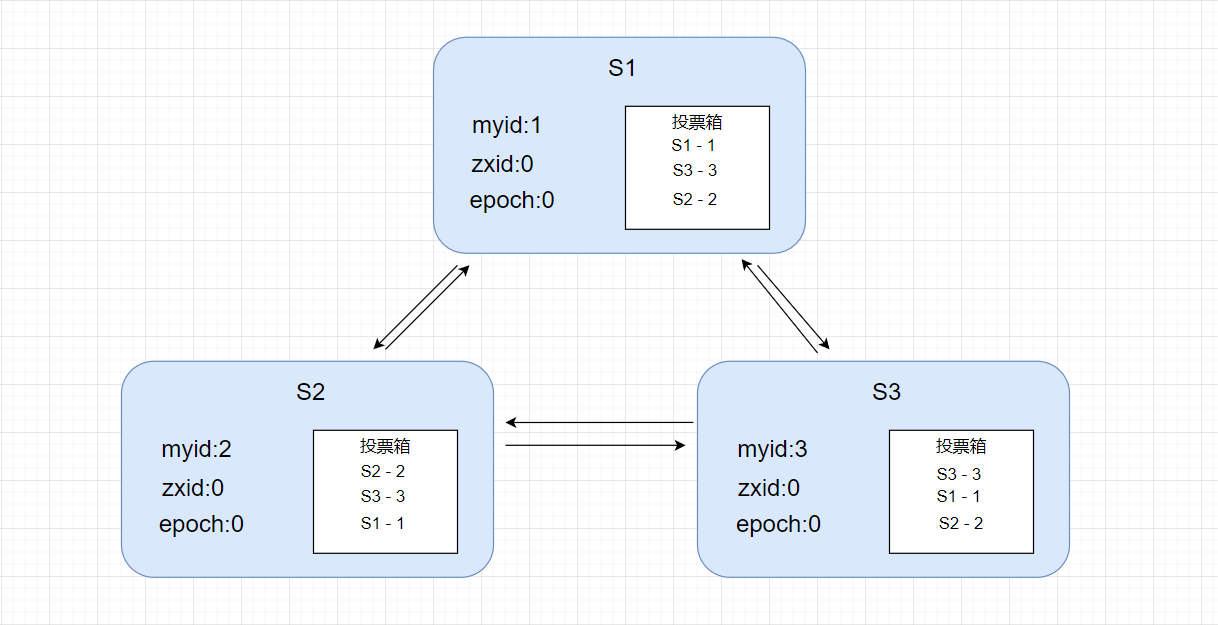
根据投票箱里的投票的节点信息,进行竞争,规则如下:
首先会对比 zxid,zxid 最大的胜出(zxid越大,表示数据越新), 如果 zxid 相同,再比较 myid (也就是 节点的 serverId),myid 较大的则胜出, 然后更新自己的投票结果,再次向其他节点广播自己更新后的投票 。
节点 S3: 根据竞争规则,胜出的票是 S3 自己,就无需更新本地投票和再次广播。
节点 S1 和 S2: 根据竞争规则, 重新投票给 S3,覆盖之前投给自己的票,再次把投票广播出去。
注意,如果接收到同一个节点同一轮选举的多次投票,那就用最后的投票覆盖之前的投票。
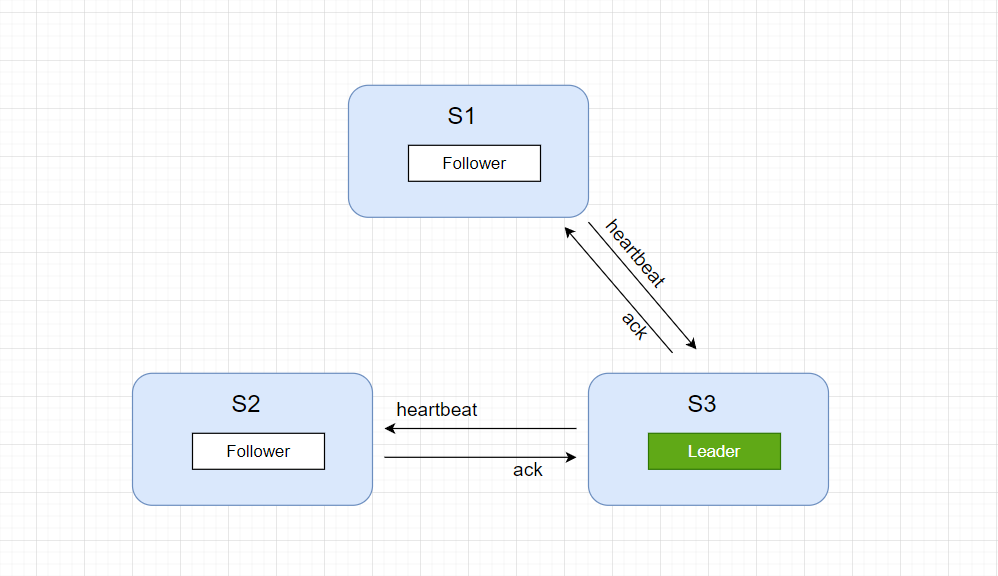
此时,节点 S3 收到节点 S1和S2的重新投票,都是投给自己,符合 "过半原则",节点 S3 成为 Leader,而 S1 和 S2 变成 Follower, 同时 Leader 向 Follower 定时发送心跳进行检查。
总结
本文主要介绍了分布式系统中几个经典的领导选举算法,Raft、ZAB、Bully、Token Ring Election, 选举规则有的是 "长者为大",而有的是 "民主投票",少数服从多数, 大家可以对比他们的优势和缺点,在实际应用中选择合适的选举算法。
为什么没有介绍 Paxos 算法呢?因为 Paxos 是共识算法,而 Basic-Paxos 中,是不需要 Leader 节点即可达成共识,可谓 "众生平等", 而在 Multi-Paxos 中提到的 Leader 概念,也仅仅是为了提高效率。当然 Paxos 是非常重要的,可以说它是分布式系统的根基。
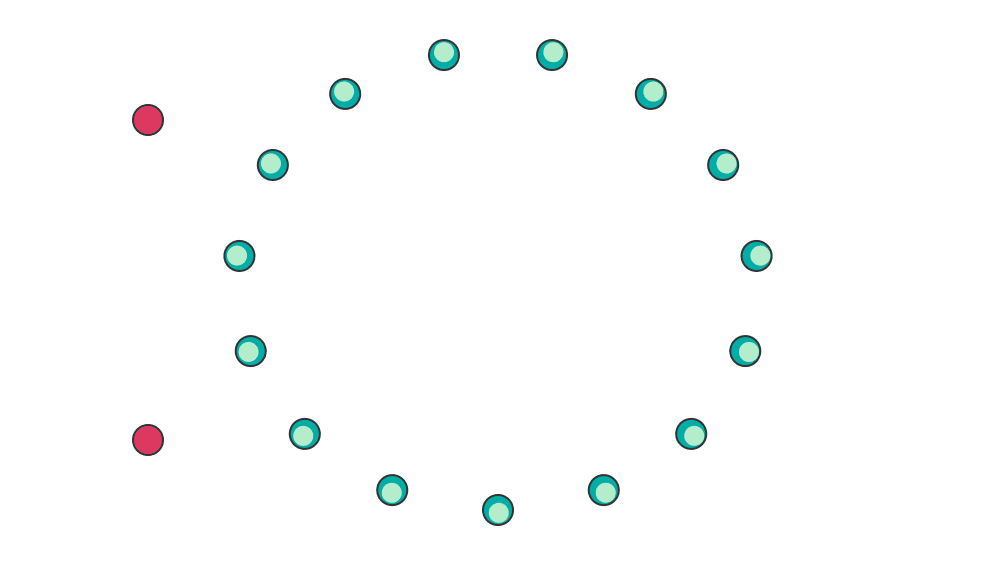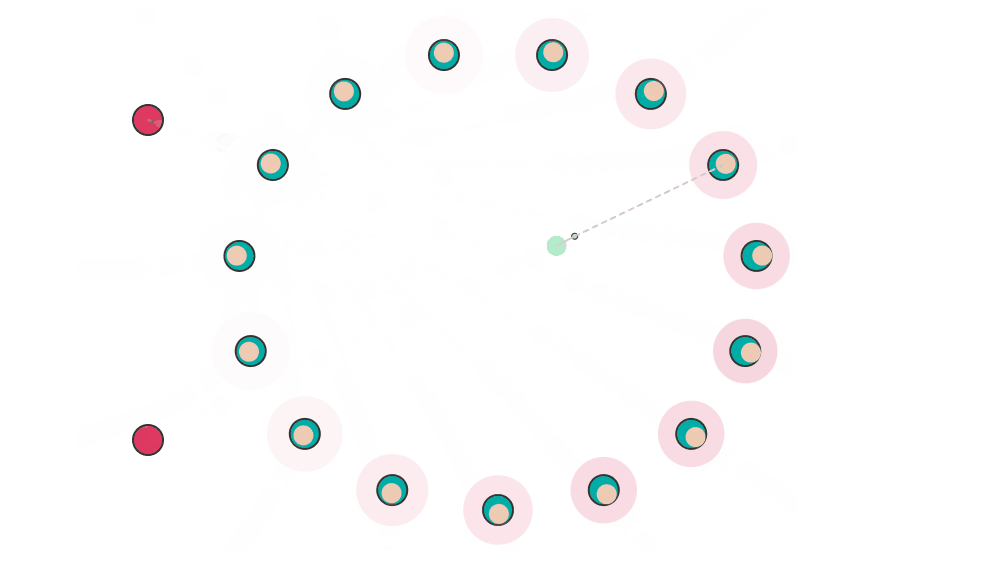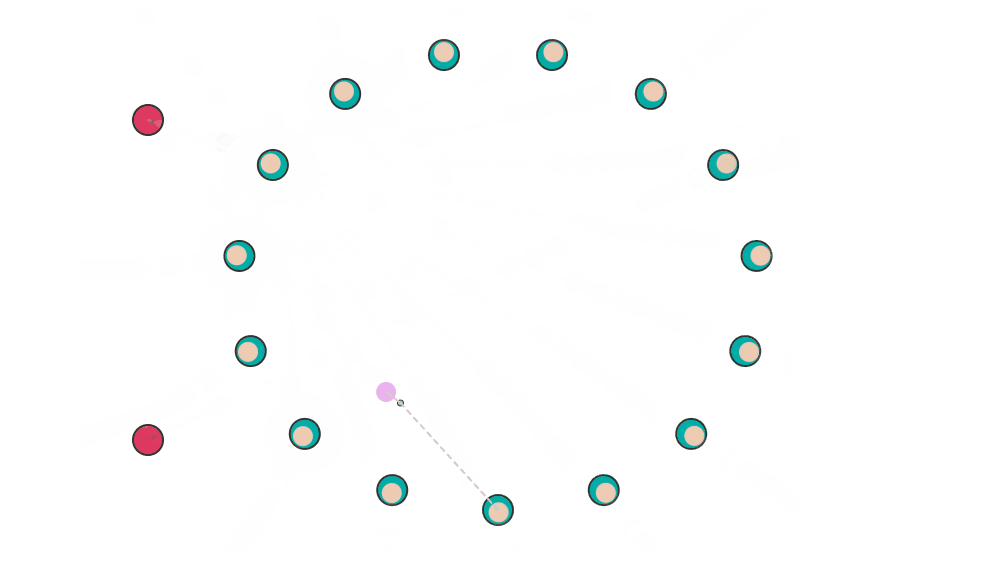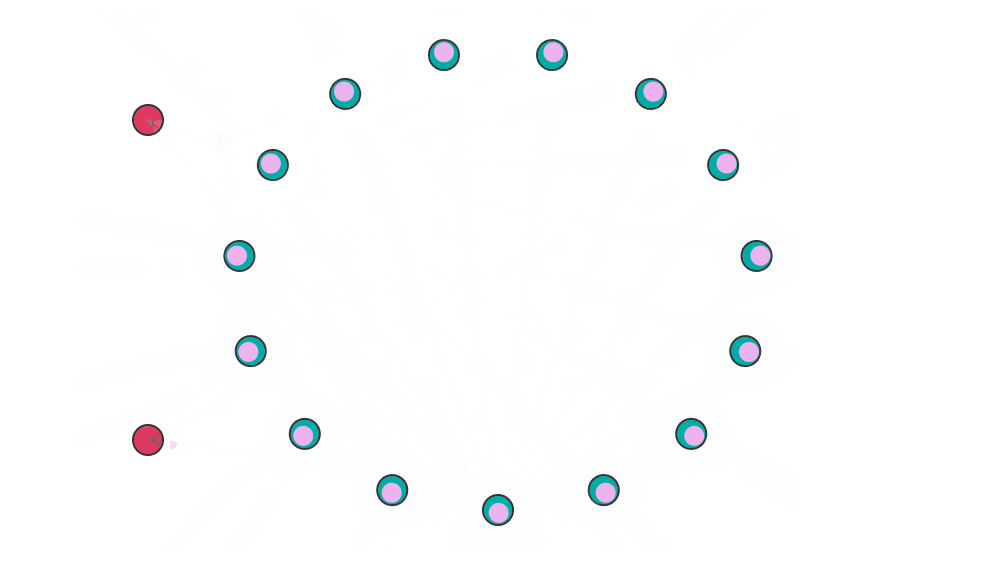
下图是 Paxos 算法写入数据时的模拟动画
Reference
http://thesecretlivesofdata.com/raft/
https://www.cs.colostate.edu/~cs551/CourseNotes/Synchronization/BullyExample.html
Zab: High-performance broadcast for primary-backup systems
ZooKeeper’s atomic broadcast protocol: Theory and practice
全文完......

 浙公网安备 33010602011771号
浙公网安备 33010602011771号