java.lang包【Object类】
基本描述:
(1)Object类位于java.lang包中,java.lang包包含着Java最基础和核心的类,在编译时会自动导入;
(2)Object类是所有Java类的祖先。每个类都使用 Object 作为超类。所有对象(包括数组)都实现这个类的方法。可以使用类型为Object的变量指向任意类型的对象
Object的主要方法介绍:
package java.lang;
public class Object {
/* 一个本地方法,具体是用C(C++)在DLL中实现的,然后通过JNI调用。*/
private static native void registerNatives();
/* 对象初始化时自动调用此方法*/
static {
registerNatives();
}
/* 返回此 Object 的运行时类。*/
public final native Class<?> getClass();
public native int hashCode();
hashCode()方法:
hash值:Java中的hashCode方法就是根据一定的规则将与对象相关的信息(比如对象的存储地址,对象的字段等)映射成一个数值,这个数值称作为散列值。
情景:考虑一种情况,当向集合中插入对象时,如何判别在集合中是否已经存在该对象了?(注意:集合中不允许重复的元素存在)。
大多数人都会想到调用equals方法来逐个进行比较,这个方法确实可行。但是如果集合中已经存在一万条数据或者更多的数据,如果采用equals方法去逐一比较,效率必然是一个问题。此时hashCode方法的作用就体现出来了,当集合要添加新的对象时,先调用这个对象的hashCode方法,得到对应的hashcode值。实际上在HashMap的具体实现中会用一个table保存已经存进去的对象的hashcode值,如果table中没有该hashcode值,它就可以直接存进去,不用再进行任何比较了;如果存在该hashcode值, 就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址。
重写hashCode()方法的基本规则:
· 在程序运行过程中,同一个对象多次调用hashCode()方法应该返回相同的值。
· 当两个对象通过equals()方法比较返回true时,则两个对象的hashCode()方法返回相等的值。
· 对象用作equals()方法比较标准的Field,都应该用来计算hashCode值。
Object本地实现的hashCode()方法计算的值是底层代码的实现,采用多种计算参数,返回的并不一定是对象的(虚拟)内存地址,具体取决于运行时库和JVM的具体实现。
public boolean equals(Object obj) {
return (this == obj);
}
equals()方法:比较两个对象是否相等
我们知道所有的对象都拥有标识(内存地址)和状态(数据),同时“==”比较两个对象的的内存地址,所以说使用Object的equals()方法是比较两个对象的内存地址是否相等,即若object1.equals(object2)为true,则表示equals1和equals2实际上是引用同一个对象。虽然有时候Object的equals()方法可以满足我们一些基本的要求,但是我们必须要清楚我们很大部分时间都是进行两个对象的比较,这个时候Object的equals()方法就不可以了,实际上JDK中,String、Math等封装类都对equals()方法进行了重写。
protected native Object clone() throws CloneNotSupportedException;
clone()方法:快速创建一个已有对象的副本
第一:Object类的clone()方法是一个native方法,native方法的效率一般来说都是远高于Java中的非native方法。这也解释了为什么要用Object中clone()方法而不是先new一个类,然后把原始对象中的信息复制到新对象中,虽然这也实现了clone功能。
第二:Object类中的 clone()方法被protected修饰符修饰。这也意味着如果要应用 clone()方 法,必须继承Object类。
第三:Object.clone()方法返回一个Object对象。我们必须进行强制类型转换才能得到我们需要的类型。
克隆的步骤:1:创建一个对象; 2:将原有对象的数据导入到新创建的数据中。
clone方法首先会判对象是否实现了Cloneable接口,若无则抛出CloneNotSupportedException, 最后会调用internalClone. intervalClone是一个native方法,一般来说native方法的执行效率高于非native方法。
复制对象 or 复制引用
Person p = new Person(23, "zhang"); Person p1 = p; System.out.println(p); System.out.println(p1); 打印出来: com.pansoft.zhangjg.testclone.Person@2f9ee1ac com.pansoft.zhangjg.testclone.Person@2f9ee1ac
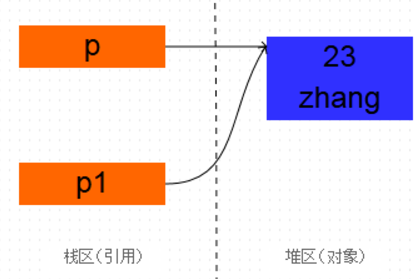
可已看出,打印的地址值是相同的,既然地址都是相同的,那么肯定是同一个对象。p和p1只是引用而已,他们都指向了一个相同的对象Person(23, "zhang") 。 可以把这种现象叫做引用的复制。
Person p = new Person(23, "zhang"); Person p1 = (Person) p.clone(); System.out.println(p); System.out.println(p1); 打印出: com.pansoft.zhangjg.testclone.Person@2f9ee1ac com.pansoft.zhangjg.testclone.Person@67f1fba0
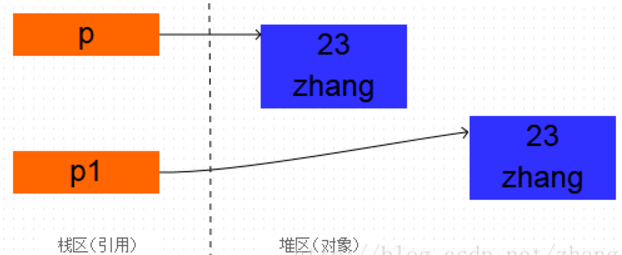
从打印结果可以看出,两个对象的地址是不同的,也就是说创建了新的对象, 而不是把原对象的地址赋给了一个新的引用变量:
深拷贝 or 浅拷贝
public class Person implements Cloneable{
private int age ;
private String name;
public Person(int age, String name) {
this.age = age;
this.name = name;
}
public Person() {}
public int getAge() {
return age;
}
public String getName() {
return name;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return (Person)super.clone();
}
}
Person中有两个成员变量,分别是name和age, name是String类型, age是int类型
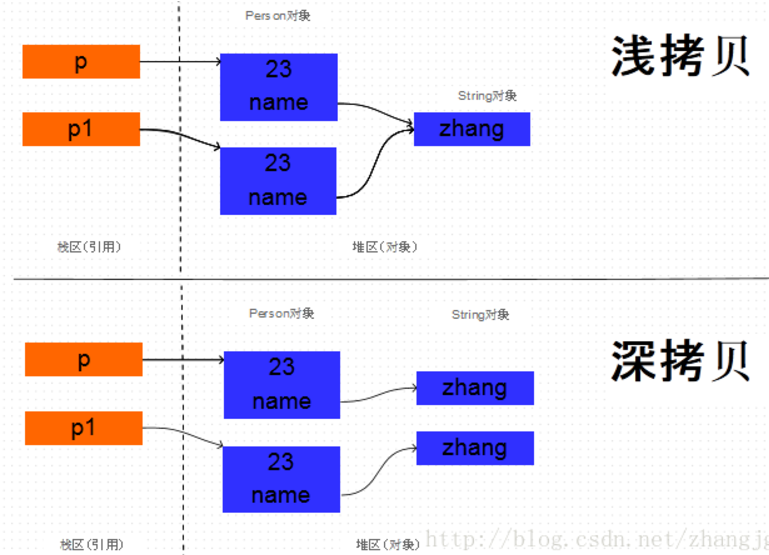
由于age是基本数据类型, 那么对它的拷贝没有什么疑议,直接将一个4字节的整数值拷贝过来就行。但是name是String类型的, 它只是一个引用, 指向一个真正的String对象,那么对它的拷贝有两种方式: 直接将源对象中的name的引用值拷贝给新对象的name字段, 或者是根据原Person对象中的name指向的字符串对象创建一个新的相同的字符串对象,将这个新字符串对象的引用赋给新拷贝的Person对象的name字段。这两种拷贝方式分别叫做浅拷贝和深拷贝。
通过下面代码进行验证。如果两个Person对象的name的地址值相同, 说明两个对象的name都指向同一个String对象, 也就是浅拷贝, 而如果两个对象的name的地址值不同, 那么就说明指向不同的String对象, 也就是在拷贝Person对象的时候, 同时拷贝了name引用的String对象, 也就是深拷贝。
Person p = new Person(23, "zhang");
Person p1 = (Person) p.clone();
String result = p.getName() == p1.getName()
? "clone是浅拷贝的" : "clone是深拷贝的";
System.out.println(result);
打印出:
clone是浅拷贝的
对于对象的浅拷贝和深拷贝还有更深的细节,可以参考:详解Java中的clone方法 -- 原型模式
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
toString()方法:toString 方法会返回一个“以文本方式表示”此对象的字符串。结果应是一个简明但易于读懂的信息表达式。建议所有子类都重写此方法。
Object 类的 toString 方法返回一个字符串,该字符串由类名(对象是该类的一个实例)、at 标记符“@”和此对象哈希码的无符号十六进制表示组成。
/*唤醒在此对象监视器上等待的单个线程。*/
public final native void notify();
/*唤醒在此对象监视器上等待的所有线程。*/
public final native void notifyAll();
/*在其他线程调用此对象的 notify() 方法或 notifyAll() 方法,或者超过指定的时间量前,导致当前线程等待。*/
public final native void wait(long timeout) throws InterruptedException;
/* 在其他线程调用此对象的 notify() 方法或 notifyAll() 方法,或者其他某个线程中断当前线程,或者已超过某个实际时间量前,导致当前线程等待。*/
public final void wait(long timeout, int nanos) throws InterruptedException {
if (timeout < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (nanos < 0 || nanos > 999999) {
throw new IllegalArgumentException(
"nanosecond timeout value out of range");
}
if (nanos >= 500000 || (nanos != 0 && timeout == 0)) {
timeout++;
}
wait(timeout);
}
/*在其他线程调用此对象的 notify() 方法或 notifyAll() 方法前,导致当前线程等待。换句话说,此方法的行为就好像它仅执行 wait(0) 调用一样。
当前线程必须拥有此对象监视器。该线程发布对此监视器的所有权并等待,直到其他线程通过调用 notify 方法,或 notifyAll 方法通知在此对象的监视器上等待的线程醒来。然后该线程将等到重新获得对监视器的所有权后才能继续执行。*/
public final void wait() throws InterruptedException {
wait(0);
}
protected void finalize() throws Throwable { }
finalize()方法:垃圾回收器准备释放内存的时候,会先调用finalize()。
(1). 对象不一定会被回收。
(2).垃圾回收不是析构函数。
(3).垃圾回收只与内存有关。
(4).垃圾回收和finalize()都是靠不住的,只要JVM还没有快到耗尽内存的地步,它是不会浪费时间进行垃圾回收的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号