redis 主从复制常见的一些坑 转
出处: redis主从复制常见的一些坑
读写分离的问题
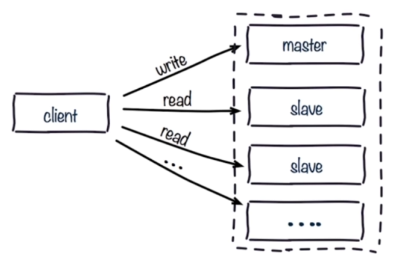
1.数据复制的延迟
读写分离时,master会异步的将数据复制到slave,如果这是slave发生阻塞,则会延迟master数据的写命令,造成数据不一致的情况
解决方法:可以对slave的偏移量值进行监控,如果发现某台slave的偏移量有问题,则将数据读取操作切换到master,但本身这个监控开销比较高,所以关于这个问题,大部分的情况是可以直接使用而不去考虑的。
2.读到过期的数据
产生原因:
redis的从库是无法主动的删除已经过期的key的,所以如果做了读写分离,就很有可能在从库读到脏数据
例子重现:
主Redis
setex test 20 1 +OK get test $1 1 ttl test :18
从Redis
get test $1 1 ttl test :7
以上都没问题,然而过几秒再看从Redis
ttl test :-1 get test $1 1
test这个key已经过期了,然而还是可以获取到test的值。
在使用Redis做锁的时候,如果直接取读从库的值,这就有大问题了。
为什么从库不删除数据?
redis删除过期数据有以下几个策略:
1.惰性删除:当读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期key,很明显,这是被动的!
2.定期删除:由于惰性删除策略无法保证冷数据被及时删掉,所以 redis 会定期主动淘汰一批已过期的key。(在第二节中会具体说明)
3.主动删除:当前已用内存超过maxMemory限定时,触发主动清理策略。主动设置的前提是设置了maxMemory的值
int expireIfNeeded(redisDb *db, robj *key) { time_t when = getExpire(db,key); if (when < 0) return 0; /* No expire for this key */ /* Don't expire anything while loading. It will be done later. */ if (server.loading) return 0; /* If we are running in the context of a slave, return ASAP: * the slave key expiration is controlled by the master that will * send us synthesized DEL operations for expired keys. * * Still we try to return the right information to the caller, * that is, 0 if we think the key should be still valid, 1 if * we think the key is expired at this time. */ if (server.masterhost != NULL) { return time(NULL) > when; } /* Return when this key has not expired */ if (time(NULL) <= when) return 0; /* Delete the key */ server.stat_expiredkeys++; propagateExpire(db,key); return dbDelete(db,key); }
解决方法:
1)通过一个程序循环便利所有的key,例如scan
2)通过ttl判断
3)升级到reidis3.2
主从配置不一致
这个问题一般很少见,但如果有,就会发生很多诡异的问题
例如:
1. maxmemory配置不一致:这个会导致数据的丢失
原因:例如master配置4G,slave配置2G,这个时候主从复制可以成功,但,如果在进行某一次全量复制的时候,slave拿到master的RDB加载数据时发现自身的2G内存不够用,这时就会触发slave的maxmemory策略,将数据进行淘汰。更可怕的是,在高可用的集群环境下,如果我们将这台slave升级成master的时候,就会发现数据已经丢失了。
2. 数据结构优化参数不一致(例如hash-max-ziplist-entries):这个就会导致内存不一致
原因:例如在master上对这个参数进行了优化,而在slave没有配置,就会造成主从节点内存不一致的诡异问题。
规避全量复制
首先,我们知道,redis复制有全量复制和部分复制两种(这个我前面博客有写到)而全量复制的开销是很大的。那么我们来看看,如何尽量去规避全量复制。
1.第一次全量复制
当我们某一台slave第一次去挂到master上时,是不可避免要进行一次全量复制的,那么,我们如何去想办法降低开销呢?
方案1:小主节点,例如我们把redis分成2G一个节点,这样一来,会加速RDB的生成和同步,同时还可以降低我们fork子进程的开销(master会fork一个子进程来生成同步需要的RDB文件,而fork是要拷贝内存快的,如果主节点内存太大,fork的开销就大)。
方案2:既然第一次不可以避免,那我们可以选在集群低峰的时间(凌晨)进行slave的挂载。
2.节点RunID不匹配
例如我们主节点重启(RunID发生变化),对于slave来说,它会保存之前master节点的RunID,如果它发现了此时master的RunID发生变化,那它会认为这是master过来的数据可能是不安全的,就会采取一次全量复制
解决办法:对于这类问题,我们只有是做一些故障转移的手段,例如master发生故障宕掉,我们选举一台slave晋升为master(哨兵或集群)
3.复制积压缓冲区不足
我在全量复制与部分复制那篇文章提到过,master生成RDB同步到slave,slave加载RDB这段时间里,master的所有写命令都会保存到一个复制缓冲队列里(如果主从直接网络抖动,进行部分复制也是走这个逻辑),待slave加载完RDB后,拿offset的值到这个队列里判断,如果在这个队列中,则把这个队列从offset到末尾全部同步过来,这个队列的默认值为1M。而如果发现offset不在这个队列,就会产生全量复制。
解决办法:增大复制缓冲区的配置 rel_backlog_size 默认1M,我们可以设置大一些,从而来加大我们offset的命中率。这个值,我们可以假设,一般我们网络故障时间一般是分钟级别,那我们可以根据我们当前的QPS来算一下每分钟可以写入多少字节,再乘以我们可能发生故障的分钟就可以得到我们这个理想的值。
规避复制风暴
什么是复制风暴?举例:我们master重启,其master下的所有slave检测到RunID发生变化,导致所有从节点向主节点做全量复制。尽管redis对这个问题做了优化,即只生成一份RDB文件,但需要多次传输,仍然开销很大。
1.单主节点复制风暴:主节点重启,多从节点全量复制
解决:更换复制拓扑如下图:
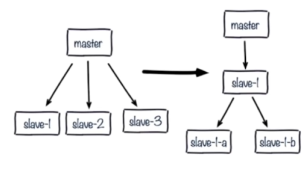
1.我们将原来master与slave中间加一个或多个slave,再在slave上加若干个slave,这样可以分担所有slave对master复制的压力。(这种架构还是有问题:读写分离的时候,slave1也发生了故障,怎么去处理?)
2.如果只是实现高可用,而不做读写分离,那当master宕机,直接晋升一台slave即可。
2.单机器复制风暴:机器宕机后的大量全量复制,如下图:
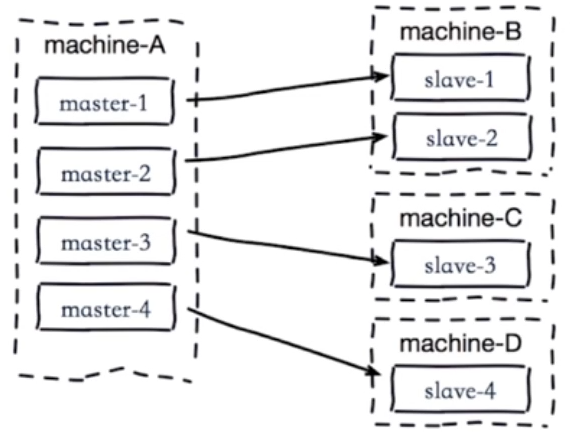
当machine-A这个机器宕机重启,会导致该机器所有master下的所有slave同时产生复制。(灾难)
解决:
1.主节点分散多机器(将master分散到不同机器上部署)
2.还有我们可以采用高可用手段(slave晋升master)就不会有类似问题了。
附录一份文章关于数据库主从数据不一致问题
数据库主从不一致问题解决方案
问:常见的数据库集群架构如何?
答: 一主多从,主从同步,读写分离。

如上图:
(1)一个主库提供写服务
(2)多个从库提供读服务,可以增加从库提升读性能
(3)主从之间同步数据
画外音:任何方案不要忘了本心,加从库的本心,是提升读性能。
问:为什么会出现不一致?
答:主从同步有时延,这个时延期间读从库,可能读到不一致的数据。
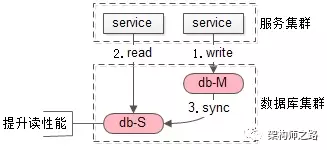
如上图:
(1)服务发起了一个写请求
(2)服务又发起了一个读请求,此时同步未完成,读到一个不一致的脏数据
(3)数据库主从同步最后才完成
画外音:任何数据冗余,必将引发一致性问题。
问:如何避免这种主从延时导致的不一致?
答:常见的方法有这么几种。
方案一:忽略
任何脱离业务的架构设计都是耍流氓,绝大部分业务,例如:百度搜索,淘宝订单,QQ消息,58帖子都允许短时间不一致。
画外音:如果业务能接受,最推崇此法。
如果业务能够接受,别把系统架构搞得太复杂。
方案二:强制读主
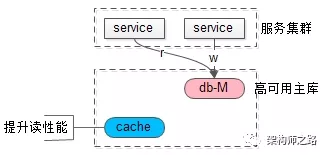
如上图:
(1)使用一个高可用主库提供数据库服务
(2)读和写都落到主库上
(3)采用缓存来提升系统读性能
这是很常见的微服务架构,可以避免数据库主从一致性问题。
方案三:选择性读主
强制读主过于粗暴,毕竟只有少量写请求,很短时间,可能读取到脏数据。
有没有可能实现,只有这一段时间,可能读到从库脏数据的读请求读主,平时读从呢?
可以利用一个缓存记录必须读主的数据。
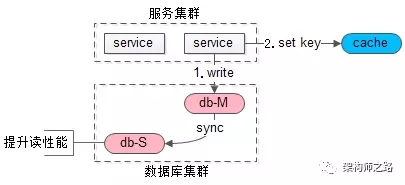
如上图,当写请求发生时:
(1)写主库
(2)将哪个库,哪个表,哪个主键三个信息拼装一个key设置到cache里,这条记录的超时时间,设置为“主从同步时延”
画外音:key的格式为“db:table:PK”,假设主从延时为1s,这个key的cache超时时间也为1s。

如上图,当读请求发生时:
这是要读哪个库,哪个表,哪个主键的数据呢,也将这三个信息拼装一个key,到cache里去查询,如果,
(1)cache里有这个key,说明1s内刚发生过写请求,数据库主从同步可能还没有完成,此时就应该去主库查询
(2)cache里没有这个key,说明最近没有发生过写请求,此时就可以去从库查询
以此,保证读到的一定不是不一致的脏数据。
总结
数据库主库和从库不一致,常见有这么几种优化方案:
(1)业务可以接受,系统不优化
(2)强制读主,高可用主库,用缓存提高读性能
(3)在cache里记录哪些记录发生过写请求,来路由读主还是读从

 浙公网安备 33010602011771号
浙公网安备 33010602011771号