Fork and Join: Java也可以轻松地编写并发程序
出处:Fork and Join: Java也可以轻松地编写并发程序
如今,多核处理器在服务器,台式机及笔记本电脑上已经很普遍了,同时也被应用在更小的设备上,比如智能手机和平板电脑。这就开启了并发编程新的潜力,因为多个线程可以在多个内核上并发执行。在应用中要实现最大性能的一个重要技术手段是将密集的任务分隔成多个可以并行执行的块,以便可以最大化利用计算能力。
处理并发(并行)程序,一向都是比较困难的,因为你必须处理线程同步和共享数据的问题。对于java平台在语言级别上对并发编程的支持就很强大,这已经在Groovy(GPars), Scala和Clojure的社区的努力下得以证明。这些社区都尽量提供全面的编程模型和有效的实现来掩饰多线程和分布式应用带来的痛苦。Java语言本身在这方面不应该被认为是不行的。Java平台标准版(Java SE) 5 ,和Java SE 6引入了一组包提供强大的并发模块。Java SE 7中通过加入了对并行支持又进一步增强它们。
接下来的文章将以Java中一个简短的并发程序作为开始,以一个在早期版本中存在的底层机制开始。在展示由Java SE7中的fork/join框架提供的fork/join任务之前,将看到java.util.concurrent包提供的丰富的原语操作。然后就是使用新API的例子。最后,将对上面总结的方法进行讨论。
在下文中,我们假定读者具有Java SE5或Java SE6的背景,我们会一路呈现一些Java SE7带来的一些实用的语言演变。
Java中普通线程的并发编程
首先从历史上来看,java并发编程中通过java.lang.Thread类和java.lang.Runnable接口来编写多线程程序,然后确保代码对于共享的可变对象表现出的正确性和一致性,并且避免不正确的读/写操作,同时不会由于竞争条件上的锁争用而产生死锁。这里是一个基本的线程操作的例子:
Thread thread = new Thread() { @Override public void run() { System.out.println("I am running in a separate thread!"); } }; thread.start(); thread.join();
例子中的代码创建了一个线程,并且打印一个字符串到标准输出。通过调用join()方法,主线程将等待创建的(子)线程执行完成。
对于简单的例子,直接操作线程这种方式是可以的,但对于并发编程,这样的代码很快变得容易出错,特别是好几个线程需要协作来完成一个更大的任务的时候。这种情况下,它们的控制流需要被协调。
例如,一个线程的执行完成可能依赖于其他将要执行完成的线程。通常熟悉的例子就是生产者/消费者的例子,因为如果消费者队列是空的,那么生产者应该等待消费者,并且如果生产者队列是空的,那么消费者也应该等待生产者。该需求可能通过共享状态和条件队列来实现,但是你仍然必须通过使用共享对象上的java.lang.Object.nofity()和java.lang.Object.wait()来实现同步,这很容易出错。
最终,一个常见的错误就是在大段代码甚至整个方法上使用synchronize进行互斥。虽然这种方法能实现线程安全的代码,但是通常由于排斥时间太长而限制了并行性,从而造成性能低下。
在通常的计算过程中,操作低级原语来实现复杂的操作,这是对错误敞开大门。因此,开发者应该寻求有效地封装复杂性为更高级的库。Java SE5提供了那样的能力。
java.util.concurrent包中丰富的原语
Java SE5引入了一个叫java.util.concurrent的包家族,在Java SE6中得到进一步增强。该包家族提供了下面这些并发编程的原语,集合以及特性:
- Executors,增强了普通的线程,因为它们(线程)从线程池管理中被抽象出来。它们执行任务类似于传递线程(实际上,是实现了java.util.Runnable的实例被封装了)。好几种实现都提供了线程池和调度策略。而且,执行结果既可以同步也可以异步的方式来获取。
- 线程安全的队列允许在并发任务中传递数据。一组丰富的实现通过基本的数据结构(如数组链表,链接链表,或双端队列)和并发行为(如阻塞,支持优先级,或延迟)得以提供。
- 细粒度的超时延迟规范,因为大部分java.util.concurrent包中的类都支持超时延迟。比如一个任务如果没有在有限之间内完成,就会被executor中断。
- 丰富的同步模式超越了java提供的互斥同步块。这些同步模式包含了常见的俗语,如信号量或同步栅栏。
- 高效的并发数据集合(maps, lists和sets)通过写时复制和细粒度锁的使用,使得在多线程上下文中表现出卓越的性能。
- 原子变量屏蔽开发者访问它们时执行同步操作。这些变量包装了通用的基本类型,比如Integers或Booleans,和对象引用。
- 大量锁超越了内部锁提供的加锁/通知功能,比如,支持重入,读写锁,超时,或者基于轮询的加锁尝试。
作为一个例子,让我们想想下面的程序:
注意:由于Java SE7引入了新的整数字面值,下划线可以在任何地方插入以提高可读性(比如,1_000_000)。
import java.util.*; import java.util.concurrent.*; import static java.util.Arrays.asList; public class Sums { static class Sum implements Callable<Long> { private final long from; private final long to; Sum(long from, long to) { this.from = from; this.to = to; } @Override public Long call() { long acc = 0; for (long i = from; i <= to; i++) { acc = acc + i; } return acc; } } public static void main(String[] args) throws Exception { ExecutorService executor = Executors.newFixedThreadPool(2); List <Future<Long>> results = executor.invokeAll(asList( new Sum(0, 10), new Sum(100, 1_000), new Sum(10_000, 1_000_000) )); executor.shutdown(); for (Future<Long> result : results) { System.out.println(result.get()); } } }
注:shutdown():停止接收新任务,原来的任务继续执行
英文原意:关闭,倒闭;停工。 这里的意思是 关闭线程池。与使用数据库连接池一样,每次使用完毕后,都要关闭线程池。
1、停止接收新的submit的任务;
2、已经提交的任务(包括正在跑的和队列中等待的),会继续执行完成;
3、等到第2步完成后,才真正停止;
这个例子程序利用executor来计算长整形数值的和。内部的Sum类实现了Callable接口,并被excutors用来执行结果计算,而并发工作则放在call方法中执行。java.util.concurrent.Executors类提供了好几个工具方法,比如提供预先配置的Executors和包装普通的java.util.Runnable对象为Callable实例。使用Callable比Runnable更优势的地方在于Callable可以有确切的返回值。
该例子使用executor分发工作给2个线程。ExecutorService.invokeAll()方法放入Callable实例的集合,并且等待直到它们都返回。其返回Future对象列表,代表了计算的“未来”结果。如果我们想以异步的方式执行,我们可以检测每个Future对象对应的Callable是否完成了它的工作和是否抛出了异常,甚至我们可以取消它。相比当使用普通的线程时,你必须通过一个共享可变的布尔值来编码取消逻辑,并且通过定期检查该布尔值来破坏该代码。因为invokeAll()是阻塞的,我们可以直接迭代Future实例来获取它们的计算和。
另外要注意executor服务必须被关闭。如果它没有被关闭,主方法执行完后JVM就不会退出,因为仍然有激活线程存在。
Fork/Join 任务
概览
Executors相对于普通的线程已经是一个很大的进步,因为executors很容易管理并发任务。有些类型的算法存在需要创建子任务,并且让它们彼此通信来完成任务。这些都是”分而治之”的算法,也被称为”map and reduce”,这是参考函数式编程的同名函数。想法是将数据区通过算法处理分隔为更小切独立的块,这是”map”阶段。反过来,一旦这些块被处理完成了,各部分的结果就可以收集起来形成最终的结果,这就是”reduce”阶段。
一个简单的例子想要计算出一个庞大的整形数组的和(如图1)。由于加法是可交换的,可以拆分数组分更小的部分,并且用并发线程计算各部分和。各部分和可以被加来从而计算出总和。因为线程可以独立对一个数组的不同区域使用这种算法操作。相比于单线程算法(迭代数组中每个整形),你将看到在多核架构中有了明显的性能提升。
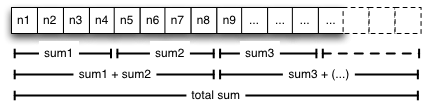
图1:整形数组中的部分和
通过executors解决上面的问题是很容易的:将数组分为n(可用的物理处理单元)部分,创建Callable实例来计算每一部分的和,提交它们到一个管理了n个线程的池中,并且收集结果计算出最终结果。
然而,对其他类型的算法和数据结构,其执行计划并不是那么简单。特别是,识别出要以有效的方式被独立处理的“足够小”的数据块的”map”阶段并不能提前知道到数据空间的拓扑结构。基于图和基于树的数据结构尤为如此。在这些情况下,算法应该创建层级”划分”,即在部分结果返回之前等待子任务完成,虽然在像图1中的数组性能较差,但有好几个并发部分和的计算的级别可以使用(比如,在双核处理器上将数组分为4个子任务)。
为了实现分而治之算法的executors的问题是创建不相关的子任务,因为一个Callable是无限制的提交一个新的子任务给它的executors,并且以同步或异步的方式等待它的结果。问题是并行:当一个Callable等待另一个Callable的结果时,它就处于等待状态,从而浪费了一个机会来处理队列中等待执行的另一个Callable。
通过Doug Lea努力填补了这一缺陷,在Java SE7中,fork/join框架被加到了java.util.concurrent包中。java.util.concurrent的Java SE5和Java SE6版本帮助处理并发,并且Java SE7的添加则帮助处理并行。
添加支持并行
核心的添加是新的ForkJoinPool执行者,专门执行实现了ForkJoinTask接口的实例。ForkJoinTask对象支持创建子任务来等待子任务完成。有了这些清晰的语义,当一个任务正在等待另一个任务完成并且有待执行的任务时,executor就能够通过”偷取”任务,在内部的线程池里分发任务。
ForkJoinTask对象主要有两个重要的方法:
- fork()方法允许ForkJoinTask任务异步执行,也允许一个新的ForkJoinTask从存在的ForkJoinTask中被启动。
- 反过来, join()方法允许一个ForkJoinTask等待另一个ForkJoinTask执行完成。
如图2所示,通过fork()和join()实现任务间的相互合作。注意fork()和join()方法名称不应该与POSIX中的进程能够复制自己的过程相混淆。fork()只会让ForkJoinPool调度一个新的任务,而不会创建子虚拟机。

图2:Fork和Join任务间的协作
有两种类型的ForkJoinTask的定义:
- RecursiveAction的实例代表执行没有返回结果。
- 相反,RecursiveTask会有返回值。
通常,RecursiveTask是首选的,因为大部分分而治之的算法会在数据集上计算后返回结果。对于任务的执行,不同的同步和异步选项是可选的,这样就可以实现复杂的模式。
例子:计算文档中的单词出现次数
为了阐述新的fork/join框架的使用,让我们用一个简单的例子(计算一个单词在文档集中的出现次数)。首先,也是最重要的,fork/join任务应该是纯内存算法,而没有I/O操作。此外,应该尽可能避免通过共享状态来进行任务间的通信,因为这通常意味着加锁会被执行。理想情况下,仅当一个任务fork另一个任务或一个任务join另一个任务时才进行任务通信。
我们的应用操作一个文件目录结构并且加载每一个文件的内容到内存中。因此,我们需要下面的类来表示模型。文档表示为一些列行:
class Document { private final List<String> lines; Document(List<String> lines) { this.lines = lines; } List<String> getLines() { return this.lines; } static Document fromFile(File file) throws IOException { List<String> lines = new LinkedList<>(); try(BufferedReader reader = new BufferedReader(new FileReader(file))) { String line = reader.readLine(); while (line != null) { lines.add(line); line = reader.readLine(); } } return new Document(lines); } }
注意:如果你对Java SE7比较陌生,你应该会对fromFlie方法中的亮点感到惊讶:
- LinkedList使用钻石语法(<>)让编译器推断出范型参数类型。因为lines是List<String>类型,所以LinkedList<>被扩展为LinkedList<String>。钻石操作符使得范型处理更容易,其避免了重复类型,因为这些类型在编译时就能被轻易的推断出来。
- try块使用了自动资源管理的语言特性。任何实现了java.lang.AutoClosable的类都可以在try块中打开。而不管是否有异常抛出,任何在try块中声明的资源将会在执行离开try块时合理地关闭。在Java SE7之前,正确地关闭资源很快变成嵌套的if/try/catch/finally块的一张噩梦,而且经常很难写正确。
一个文件夹时一个简单的基于树的结构:
class Folder { private final List<Folder> subFolders; private final List<Document> documents; Folder(List<Folder> subFolders, List<Document> documents) { this.subFolders = subFolders; this.documents = documents; } List<Folder> getSubFolders() { return this.subFolders; } List<Document> getDocuments() { return this.documents; } static Folder fromDirectory(File dir) throws IOException { List<Document> documents = new LinkedList<>(); List<Folder> subFolders = new LinkedList<>(); for (File entry : dir.listFiles()) { if (entry.isDirectory()) { subFolders.add(Folder.fromDirectory(entry)); } else { documents.add(Document.fromFile(entry)); } } return new Folder(subFolders, documents); } }
现在我们可以开始我们的主类了:
import java.io.*; import java.util.*; import java.util.concurrent.*; public class WordCounter { String[] wordsIn(String line) { return line.trim().split("(\\s|\\p{Punct})+"); } Long occurrencesCount(Document document, String searchedWord) { long count = 0; for (String line : document.getLines()) { for (String word : wordsIn(line)) { if (searchedWord.equals(word)) { count = count + 1; } } } return count; } }
occurrencesCount方法返回一个单词在文档中的出现次数,利用wordIn方法产生一行内的单词组,它会基于空格或标点符号来分割每一行。
我们将实现两种类型的fork/join任务。一个文件夹下的单词出现次数就是该单词在该文件夹下的所有的子文件夹和文档中出现次数的总和。因此,我们将用一个任务计数在文档中的出现次数和用另一个任务在文件夹下的计数,后者将forks子任务,然后将这些任务join起来,集合他们的结果。
依赖的任务关系很容易理解,如图3所示,因为它直接映射底层文档或文件夹树结构。fork/join框架通过在等待一个任务执行文档或文件夹单词计数时可以通过join()同时执行一个文件夹任务,实现了并行最大化。
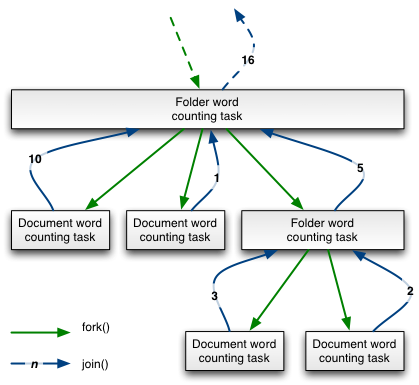
图3:Fork/Join单词计数任务
让我们以DocumentSearchTask任务开始,它将计算一个文档中单词的出现次数:
class DocumentSearchTask extends RecursiveTask<Long> { private final Document document; private final String searchedWord; DocumentSearchTask(Document document, String searchedWord) { super(); this.document = document; this.searchedWord = searchedWord; } @Override protected Long compute() { return occurrencesCount(document, searchedWord); } }
因为我们的任务需要返回值,因此它们扩展自RecursiveTask类,由于出现次数用long值表示,所以用Long作为范型参数。compute()方法是RecursiveTask的核心,这里的实现就简单的委派给上面的occurencesCount()方法。现在我们可以实现FolderSearchTask,该任务将对树结构中的文件夹进行操作:
class FolderSearchTask extends RecursiveTask<Long> { private final Folder folder; private final String searchedWord; FolderSearchTask(Folder folder, String searchedWord) { super(); this.folder = folder; this.searchedWord = searchedWord; } @Override protected Long compute() { long count = 0L; List<RecursiveTask<Long>> forks = new LinkedList<>(); for (Folder subFolder : folder.getSubFolders()) { FolderSearchTask task = new FolderSearchTask(subFolder, searchedWord); forks.add(task); task.fork(); } for (Document document : folder.getDocuments()) { DocumentSearchTask task = new DocumentSearchTask(document, searchedWord); forks.add(task); task.fork(); } for (RecursiveTask<Long> task : forks) { count = count + task.join(); } return count; } }
该任务的compute()方法的实现简单地对构造函数中传递的文件夹的每个元素fork出新的文档或文件夹任务,然后join所有的计算出的部分和并返回部分和。
对于fork/join框架,我们现在缺少一个方法来引导单词 计数操作和一个fork/join池执行者:
private final ForkJoinPool forkJoinPool = new ForkJoinPool(); Long countOccurrencesInParallel(Folder folder, String searchedWord) { return forkJoinPool.invoke(new FolderSearchTask(folder, searchedWord)); }
一个初始的FolderSearchTask引导了所有任务。ForkJoinPool的invoke方法允许等待计算的完成。在上面的例子中,使用了ForkJoinPool的空构造函数,并行性将匹配硬件可用的处理器单元数(比如,在双核处理器上该值为2)。
现在我们可以写main()方法,通过命令行参数来获得要操作的文件夹和搜索的单词:
public static void main(String[] args) throws IOException { WordCounter wordCounter = new WordCounter(); Folder folder = Folder.fromDirectory(new File(args[0])); System.out.println(wordCounter.countOccurrencesOnSingleThread(folder, args[1])); }
此示例的完整源代码还包括更传统的,基于递归实现的相同算法,并运行在一个运行在单线程上:
Long countOccurrencesOnSingleThread(Folder folder, String searchedWord) { long count = 0; for (Folder subFolder : folder.getSubFolders()) { count = count + countOccurrencesOnSingleThread(subFolder, searchedWord); } for (Document document : folder.getDocuments()) { count = count + occurrencesCount(document, searchedWord); } return count; }
讨论
在来自Oracle的Sun Fire T2000服务器上进行了一个非正式的测试,该服务器可以规定Java虚拟机可用的处理器核数。上述的fork/join和单线程实例的不同版本都运行来查找JDK源代码文件中import的出现次数。
这些不同版本都会运行好几次,以确保Java虚拟机热点优化有足够的时间来执行。对于2, 4, 8和12核最佳的执行时间被收集了起来并且在加速,那就是说,这些比值(单线程耗时/fork-join耗时)被计算出来了。图4核表1反应了其结果。
如你所见,随着处理器核数极小的增长就实现了近似线性地加速,因为fork/join框架关心的是最大化并行。
表1:非正式的测试执行时间和加速
| Number of Cores | Single-Thread Execution Time (ms) | Fork/Join Execution Time (ms) | Speedup |
| 2 | 18798 | 11026 | 1.704879376 |
| 4 | 19473 | 8329 | 2.337975747 |
| 8 | 18911 | 4208 | 4.494058935 |
| 12 | 19410 | 2876 | 6.748956885 |

图4:随着核数(水平轴)增长而加速(垂直轴)
我们也可以通过让fork任务不操作在文档级别,而是行级别来改进计算能力。这使得并发任务可能在同一文档的不同行执行。然而这将是牵强的。事实上,fork/join任务应该执行足够的计算量,以克服fork/join线程池或任务管理开销。行级别的操作很琐碎,反而影响方法的效率。
附带的源代码还有一个基于整型数组的归并算法fork/join例子,有趣的是它使用RecursiveAction来实现的。fork/join任务在调用join()时不会返回值。而是,这些任务共享可变状态:待排序的数组。实验再次 表明随内核数量增长,将实现近线性地加速。
总结
本文讨论了Java中并发编程并强烈关注Java SE 7中所提供的新的fork / join任务,使得编写并行程序更容易。这篇文章显示,利用多核处理器,使用丰富的原语并组合它们编写出高性能的程序,所有这些都无需处理线程的低级别操作和共享状态同步。这篇文章通过一个既有吸引力又容易掌握的单词计数例子阐释了那些新APIs的使用,在非正式的测试中,随处理器核数增长,获得了接近线性的加速比。这些结果表面fork/join框架是多么有用。因为我们没又更改代码或调整Java虚拟机硬件的最大化核心利用率。
你也可以应用该技术到你的问题和数据模型。只要你以”分而治之”的方式重写你的算法来释放I/O操作和锁,你将看到明显的变化。
鸣谢
作者要感谢Brian Goetz和迈克Duigou在早期的文章中有用的反馈修正。他还要感谢Scott Oaks and Alexis Moussine-Pouchkine,在合适的硬件上运行这些测试。
参考
JavSE Downloads: http://www.oracle.com/technetwork/java/javase/downloads/index.html
Sample Code: http://www.oracle.com/technetwork/articles/java/forkjoinsources-430155.zip
Java SE 7 API: http://download.java.net/jdk7/docs/api/
JSR-166 Interest Site by Doug Lea: http://gee.cs.oswego.edu/dl/concurrency-interest/
Project Coin: http://openjdk.java.net/projects/coin/
Java Concurrency in Practice by Brian Goetz, Tim Peierls, Joshua Bloch, Joseph Bowbeer, David Holmes and Doug Lea (Addision-Wesley Professional):
http://www.informit.com/store/product.aspx?isbn=0321349601
Merge-sort algorithm: http://en.wikipedia.org/wiki/Merge_sort
Groovy: http://groovy.codehaus.org/
GPars: http://gpars.codehaus.org/
Scala: http://scala-lang.org
Clojure: http://clojure.org/
附录: 完整代码示例
BasicThread.java
public class BasicThread { public static void main(String[] args) throws InterruptedException { Thread thread = new Thread() { @Override public void run() { System.out.println(">>> I am running in a separate thread!"); } }; thread.start(); thread.join(); } }
Sums.java
import java.util.List; import java.util.concurrent.Future; import java.util.concurrent.Callable; import java.util.concurrent.Executors; import java.util.concurrent.ExecutorService; import static java.util.Arrays.asList; public class Sums { static class Sum implements Callable<Long> { private final long from; private final long to; Sum(long from, long to) { this.from = from; this.to = to; } @Override public Long call() { long acc = 0; for (long i = from; i <= to; i++) { acc = acc + i; } return acc; } } public static void main(String[] args) throws Exception { ExecutorService executor = Executors.newFixedThreadPool(2); List<Future<Long>> results = executor.invokeAll(asList( new Sum(0, 10), new Sum(100, 1_000), new Sum(10_000, 1_000_000) )); executor.shutdown(); for (Future<Long> result : results) { System.out.println(result.get()); } } }
WordCounter.java
/* ......................................................................................... */ import java.io.*; import java.util.*; import java.util.concurrent.*; /* ......................................................................................... */ class Document { private final List<String> lines; Document(List<String> lines) { this.lines = lines; } List<String> getLines() { return this.lines; } static Document fromFile(File file) throws IOException { List<String> lines = new LinkedList<>(); try(BufferedReader reader = new BufferedReader(new FileReader(file))) { String line = reader.readLine(); while (line != null) { lines.add(line); line = reader.readLine(); } } return new Document(lines); } } /* ......................................................................................... */ class Folder { private final List<Folder> subFolders; private final List<Document> documents; Folder(List<Folder> subFolders, List<Document> documents) { this.subFolders = subFolders; this.documents = documents; } List<Folder> getSubFolders() { return this.subFolders; } List<Document> getDocuments() { return this.documents; } static Folder fromDirectory(File dir) throws IOException { List<Document> documents = new LinkedList<>(); List<Folder> subFolders = new LinkedList<>(); for (File entry : dir.listFiles()) { if (entry.isDirectory()) { subFolders.add(Folder.fromDirectory(entry)); } else { documents.add(Document.fromFile(entry)); } } return new Folder(subFolders, documents); } } /* ......................................................................................... */ public class WordCounter { /* ......................................................................................... */ String[] wordsIn(String line) { return line.trim().split("(\\s|\\p{Punct})+"); } Long occurrencesCount(Document document, String searchedWord) { long count = 0; for (String line : document.getLines()) { for (String word : wordsIn(line)) { if (searchedWord.equals(word)) { count = count + 1; } } } return count; } /* ......................................................................................... */ Long countOccurrencesOnSingleThread(Folder folder, String searchedWord) { long count = 0; for (Folder subFolder : folder.getSubFolders()) { count = count + countOccurrencesOnSingleThread(subFolder, searchedWord); } for (Document document : folder.getDocuments()) { count = count + occurrencesCount(document, searchedWord); } return count; } /* ......................................................................................... */ class DocumentSearchTask extends RecursiveTask<Long> { private final Document document; private final String searchedWord; DocumentSearchTask(Document document, String searchedWord) { super(); this.document = document; this.searchedWord = searchedWord; } @Override protected Long compute() { return occurrencesCount(document, searchedWord); } } /* ......................................................................................... */ class FolderSearchTask extends RecursiveTask<Long> { private final Folder folder; private final String searchedWord; FolderSearchTask(Folder folder, String searchedWord) { super(); this.folder = folder; this.searchedWord = searchedWord; } @Override protected Long compute() { long count = 0L; List<RecursiveTask<Long>> forks = new LinkedList<>(); for (Folder subFolder : folder.getSubFolders()) { FolderSearchTask task = new FolderSearchTask(subFolder, searchedWord); forks.add(task); task.fork(); } for (Document document : folder.getDocuments()) { DocumentSearchTask task = new DocumentSearchTask(document, searchedWord); forks.add(task); task.fork(); } for (RecursiveTask<Long> task : forks) { count = count + task.join(); } return count; } } /* ......................................................................................... */ private final ForkJoinPool forkJoinPool = new ForkJoinPool(); Long countOccurrencesInParallel(Folder folder, String searchedWord) { return forkJoinPool.invoke(new FolderSearchTask(folder, searchedWord)); } /* ......................................................................................... */ public static void main(String[] args) throws IOException { WordCounter wordCounter = new WordCounter(); Folder folder = Folder.fromDirectory(new File(args[0])); final int repeatCount = Integer.decode(args[2]); long counts; long startTime; long stopTime; long[] singleThreadTimes = new long[repeatCount]; long[] forkedThreadTimes = new long[repeatCount]; for (int i = 0; i < repeatCount; i++) { startTime = System.currentTimeMillis(); counts = wordCounter.countOccurrencesOnSingleThread(folder, args[1]); stopTime = System.currentTimeMillis(); singleThreadTimes[i] = (stopTime - startTime); System.out.println(counts + " , single thread search took " + singleThreadTimes[i] + "ms"); } for (int i = 0; i < repeatCount; i++) { startTime = System.currentTimeMillis(); counts = wordCounter.countOccurrencesInParallel(folder, args[1]); stopTime = System.currentTimeMillis(); forkedThreadTimes[i] = (stopTime - startTime); System.out.println(counts + " , fork / join search took " + forkedThreadTimes[i] + "ms"); } System.out.println("\nCSV Output:\n"); System.out.println("Single thread,Fork/Join"); for (int i = 0; i < repeatCount; i++) { System.out.println(singleThreadTimes[i] + "," + forkedThreadTimes[i]); } System.out.println(); } } /* ......................................................................................... */

 浙公网安备 33010602011771号
浙公网安备 33010602011771号