关于进程与线程的简单解释
进程(process)和线程(thread)是操作系统的基本概念,但是它们比较抽象,不容易掌握。最近,我读到一篇材料,发现有一个很好的类比,可以把它们解释地清晰易懂。
1. 计算机的核心是CPU,它承担了所有的计算任务。它就像一座工厂,时刻在运行。

2.假定工厂的电力有限,一次只能供给一个车间使用。也就是说,一个车间开工的时候,其他车间都必须停工。背后的含义就是,单个CPU一次只能运行一个任务。

3.进程就好比工厂的车间,它代表CPU所能处理的单个任务。任一时刻,CPU总是运行一个进程,其他进程处于非运行状态。

4.一个车间里,可以有很多工人。他们协同完成一个任务。

5.线程就好比车间里的工人。一个进程可以包括多个线程。

6.车间的空间是工人们共享的,比如许多房间是每个工人都可以进出的。这象征一个进程的内存空间是共享的,每个线程都可以使用这些共享内存。
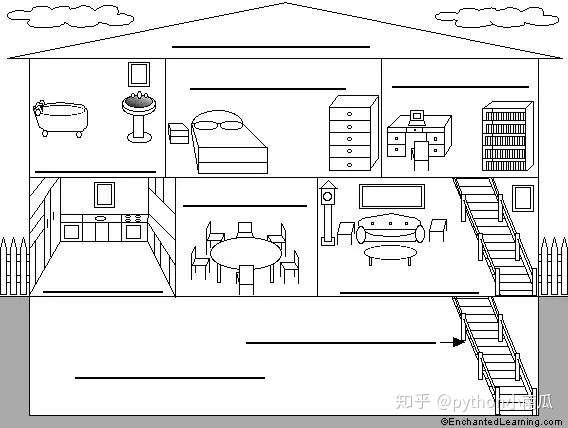
7.可是,每间房间的大小不同,有些房间最多只能容纳一个人,比如厕所。里面有人的时候,其他人就不能进去了。这代表一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。
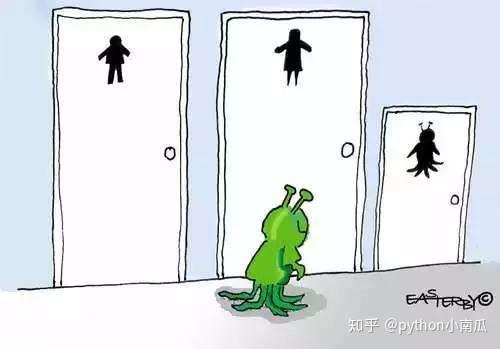
8.一个防止他人进入的简单方法,就是门口加一把锁。先到的人锁上门,后到的人看到上锁,就在门口排队,等锁打开再进去。这就叫"互斥锁"(Mutual exclusion,缩写 Mutex),防止多个线程同时读写某一块内存区域。

9.还有些房间,可以同时容纳n个人,比如厨房。也就是说,如果人数大于n,多出来的人只能在外面等着。这好比某些内存区域,只能供给固定数目的线程使用。

10.这时的解决方法,就是在门口挂n把钥匙。进去的人就取一把钥匙,出来时再把钥匙挂回原处。后到的人发现钥匙架空了,就知道必须在门口排队等着了。这种做法叫做"信号量"(Semaphore),用来保证多个线程不会互相冲突。
不难看出,mutex是semaphore的一种特殊情况(n=1时)。也就是说,完全可以用后者替代前者。但是,因为mutex较为简单,且效率高,所以在必须保证资源独占的情况下,还是采用这种设计。

11.操作系统的设计,因此可以归结为三点:
(1)以多进程形式,允许多个任务同时运行;
(2)以多线程形式,允许单个任务分成不同的部分运行;
(3)提供协调机制,一方面防止进程之间和线程之间产生冲突,另一方面允许进程之间和线程之间共享资源。

我们这里把性能限制在一个程序运行一个任务, 这个任务是只消耗CPU资源(CPU bound), 所花的时间越小, 说明性能越好. 为了纯粹地说明问题, 我们排除了数据共享问题, 即线程之间不做任何同步动作, 完全隔离.
从理论上说,如果计算机只执行这一个测试程序, 那么单线程要比多线程性能好,因为多线程需要做线程上下文环境的切换; 而当计算机同时运行其他的进程, 假设其他进程里也有多个大量消耗CPU的任务, 那么我们的程序由于是多线程, 抢到CPU时间片的机会增多, 它的性能应该好于单线程.
理论上是这么回事, 但我们知道, 实践与理论是有差距的, 我们的测试不可能在真空环境中. 操作系统的实现有高度的戏剧性, 谁也不能预测实际的测试一定与理论相符, 另外在我们实际的运行环境中,各种情况导致的系统差异很大, 因为我们必须做一些测试.
MSDN上有一篇著名的文章<<Win32 Multithreading Performance>>, 里面讲的东西与我们很相近. 它主要论述的是串行计算和并行计算的性能比较, 我们直接拿它的例子, 进行一些更改, 来测试我们的假设.
首先讨论我们测试的主题与它的不同, 主要有2点: 1, 我们讨论的任务是一个固定的任务, 而它里面讨论的是数个计算量不同的任务, 而计算不同的任务涉及到吞吐量的概念; 2, 我们讨论的是线程数量之间的比较(分别测试不同数量的线程), 而它只有单线程与多线程的比较.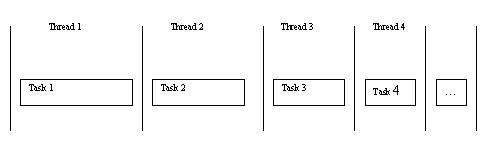
图1: 多个不同的任务并行处理
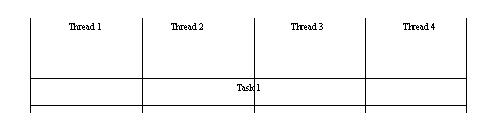
图2: 一个固定的任务并行处理
测试程序介绍
一个任务在这里简化为一个持续占用CPU的计算, 为了测试的准确性, 中间不可以有任何的I/O操作, 例如:
for (int iCounter=0; iCounter<iLoopCount; iCounter++);
给定的任务量iDelay,单位是毫秒, 有一段模拟的代码, 从而把一秒的时间转换为循环数iLoopCount.里面所用的两个API是QueryPerformanceFrequency和QueryPerformanceCounter.
void CThreadlibtestView::OnFixTask() { if(!m_iNumberOfThreads) { MessageBeep(-1); return; }; for (int iLoop=0;iLoop<m_iNumberOfThreads;iLoop++) { m_iNumbers[iLoop]=(int)&m_tbConc[iLoop]; m_tbConc[iLoop].iId=iLoop; if(iLoop==0) m_tbConc[iLoop].iDelay=m_iDelay/m_iNumberOfThreads+m_iDelay%m_iNumberOfThreads; else m_tbConc[iLoop].iDelay=m_iDelay/m_iNumberOfThreads; m_tbConc[iLoop].tbOutputTarget=this; m_tbConc[iLoop].iStartOrder=0; m_tbConc[iLoop].iEndOrder=0; m_tbConc[iLoop].iTouchCount=0; }; }
另外我们指定特定的任务量和线程数量:
int iTaskSize[]={100,500,1000,2000,4000}; int iThreadSize[]={2,5,10,15,20};
单线程时候我们调用OnSerial(), 多线程时调用OnConcurrent(), 线程数量分别取iThreadSize里的值.
测试次数仍然保持10次, 取平均值, 整个测试我们分别运行两次, 第一次在负载很轻的计算机上运行, 第二次在同样的计算机上加载一个大负载的进程, 此进程里有十个线程, 每个线程都是基于CPU的密集计算, 程序如下:
DWORD WINAPI ThreadFunc(LPVOID lpParam) { DWORD busyTime=10; while(true) { DWORD startTime=GetTickCount(); for(;GetTickCount()-startTime<=busyTime;) ; Sleep(1); } return 0; }
特别要注意的是, 两次计算不能各启动一个进程, 必须在一个进程中, 因为在程序开始,我们会算出1秒对应循环数, 而每次启动程序这个数字是不同的, 为了更有意义的比较,我们要求这个数字一定相同.
测试环境: CPU Intel Pentium M 1.7 G; 1047472KB RAM, Windows 2000 professional SP4.
一秒的循环数:146278208
测试结果

图3: 在负载轻的系统上测试结果

图4: 在负载重的系统上测试结果
结论和建议
根据测试结果,我们可以得出一些结论(针对单核CPU):
在负载轻的系统上, 多线程不适合处理基于CPU的任务,而在负载重的系统上,多线程可以帮助提高性能.
这是一个模糊和慎重的结论, 因为测试结果里的一些现象我也给不出合适的理由, 应该属于操作系统”戏剧化”和”不确定性”的表现吧(操作系统会对某些线程动态提高优先级,但本例中的线程优先级保持不变.), 例如在负载轻的机器上, 20个线程和2个线程运行时间差异不大; 在负载重的机器上, 2个线程运行时间比单线程还长, 而当线程数量增加到5时, 性能才有显著的提高.
所以我的建议是,在单核CPU机器上,处理CPU密集的任务时, 不推荐使用多线程, 除非你对目标机器非常的了解和确定,并经过严格的测试. 当然, 涉及到其他I/O操作的任务, 比如等待用户按键, 读取文件, 网络通讯等, 多线程才是正当其选的解决方案.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号