限流算法介绍( 转)
在开发高并发系统时,有三把利器用来保护系统:缓存、降级和限流。
服务限流:
流量控制本质上是减小访问量,而服务处理能力不变;而服务降级本质上是降低了部分服务的处理能力,增强另一部分服务处理能力,而访问量不变。
限流算法的应用场景非常广泛,比如通过限流来确保下游配置较差的应用不会被上游应用的大量请求击穿,无论是HTTP请求还是RPC请求,从而使得服务保持稳定。限流也同样可以用于客户端,比如当我们需要从微博上爬取数据时,我们需要在请求中携带token从而通过微博的网关验证。但是微博为了防止服务被单个客户端大量访问,往往会在服务端进行限流,比如可能是一个token一个小时只能发起1000次请求。但是爬虫发出的请求通常远远不止这个量级。所以在客户端进行限流可以确保我们的token不会失效或是查封。
限流算法可以从多种角度分类,比如按照处理方式分为两种,一种是在超出限定流量之后会拒绝多余的访问,另一种是超出限定流量之后,只是报警或者是记录日志,访问仍然正常进行。
以下主要介绍几种常见的服务限流算法和优缺点,以及单机限流和分布式限流。没有哪种算法是最好的或者是最差的,具体要根据实际业务场景决定使用哪种实现方式,本质都是提高功能的性价比,利用尽可能小的开发成本,产生尽可能大的收益。目前比较常见的限流算法有以下几种:
- 固定窗口
- 滑动窗口
- 令牌桶算法
- 漏桶算法
算法介绍
1:固定窗口 (计数器法)
计数器是最简单的限流算法,思路是维护一个单位时间内的计数器 Counter,如判断单位时间已经过去,则将计数器归零。
我们假设有个需求对于某个接口 /query 每分钟最多允许访问 200 次。
- 可以在程序中设置一个变量 count,当过来一个请求我就将这个数 +1,同时记录请求时间。
- 当下一个请求来的时候判断 count 的计数值是否超过设定的频次,以及当前请求的时间和第一次请求时间是否在 1 分钟内。
- 如果在 1 分钟内并且超过设定的频次则证明请求过多,后面的请求就拒绝掉。
- 如果该请求与第一个请求的间隔时间大于 1 分钟,且 count 值还在限流范围内,就重置 count。
但是这种实现会有一个问题,举个例子:
假设我们设定1秒内允许通过的请求阈值是200,如果有用户在时间窗口的最后几毫秒发送了200个请求,紧接着又在下一个时间窗口开始时发送了200个请求,那么这个用户其实在一秒内成功请求了400次,显然超过了阈值但并不会被限流。其实这就是临界值问题,那么临界值问题要怎么解决呢?

代码实例:
import java.util.concurrent.Executors; import java.util.concurrent.ScheduledExecutorService; import java.util.concurrent.TimeUnit; import java.util.concurrent.atomic.AtomicInteger; public class FixedWindowRateLimiter implements RateLimiter, Runnable { private static final int DEFAULT_ALLOWED_VISIT_PER_SECOND = 5; private final int maxVisitPerSecond; private AtomicInteger count; FixedWindowRateLimiter(){ this.maxVisitPerSecond = DEFAULT_ALLOWED_VISIT_PER_SECOND; this.count = new AtomicInteger(); } FixedWindowRateLimiter(int maxVisitPerSecond) { this.maxVisitPerSecond = maxVisitPerSecond; this.count = new AtomicInteger(); } @Override public boolean isOverLimit() { return currentQPS() > maxVisitPerSecond; } @Override public int currentQPS() { return count.get(); } @Override public boolean visit() { count.incrementAndGet(); System.out.print(isOverLimit()); return isOverLimit(); } @Override public void run() { System.out.println(this.currentQPS()); count.set(0); } public static void main(String[] args) { ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor(); FixedWindowRateLimiter rateLimiter = new FixedWindowRateLimiter(); scheduledExecutorService.scheduleAtFixedRate(rateLimiter, 0, 1, TimeUnit.SECONDS); new Thread(new Runnable() { @Override public void run() { while(true) { rateLimiter.visit(); try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } } } }).start(); new Thread(new Runnable() { @Override public void run() { while(true) { rateLimiter.visit(); try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } } } }).start(); } }
其中RateLimiter是一个通用的接口,后面的其它限流算法也会实现该接口:
public interface RateLimiter { boolean isOverLimit(); int currentQPS(); boolean visit(); }
2:滑动窗口
计数器滑动窗口法就是为了解决上述固定窗口计数存在的问题而诞生,学过TCP协议的同学应该对滑动窗口不陌生,其实还是不太一样的,下文我们要说的滑动窗口是基于时间来划分窗口的。而TCP的滑动窗口指的是能够接受的字节数,并且大小是可变的(拥塞控制)
滑动窗口是怎么做的?
前面说了固定窗口存在临界值问题,要解决这种临界值问题,显然只用一个窗口是解决不了问题的。假设我们仍然设定1秒内允许通过的请求是200个,但是在这里我们需要把1秒的时间分成多格,假设分成5格(格数越多,流量过渡越平滑),每格窗口的时间大小是200毫秒,每过200毫秒,就将窗口向前移动一格。为了便于理解,可以看下图
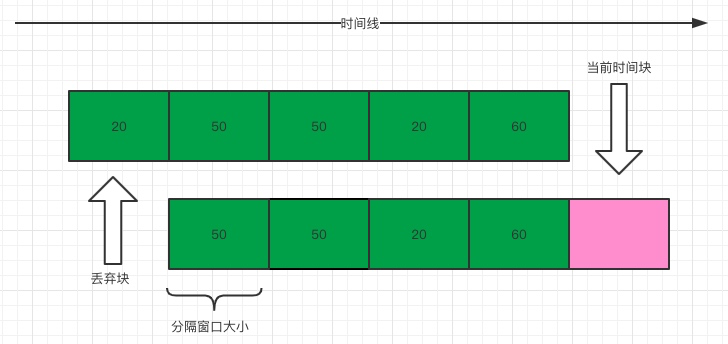
图中将窗口划为5份,每个小窗口中的数字表示在这个窗口中请求数,所以通过观察上图,可知在当前时间快(200毫秒)允许通过的请求数应该是20而不是200(只要超过20就会被限流),因为我们最终统计请求数时是需要把当前窗口的值进行累加,进而得到当前请求数来判断是不是需要进行限流。
那么滑动窗口限流法是完美的吗?
细心观察的我们应该能马上发现问题,滑动窗口限流法其实就是计数器固定窗口算法的一个变种。流量的过渡是否平滑依赖于我们设置的窗口格数也就是统计时间间隔,格数越多,统计越精确,但是具体要分多少格我们也说不上来呀...
代码实现:
public class SlidingWindowRateLimiter implements RateLimiter, Runnable{ private final long maxVisitPerSecond; private static final int DEFAULT_BLOCK = 10; private final int block; private final AtomicLong[] countPerBlock; private AtomicLong count; private volatile int index; public SlidingWindowRateLimiter(int block, long maxVisitPerSecond) { this.block = block; this.maxVisitPerSecond = maxVisitPerSecond; countPerBlock = new AtomicLong[block]; for (int i = 0 ; i< block ; i++) { countPerBlock[i] = new AtomicLong(); } count = new AtomicLong(0); } public SlidingWindowRateLimiter() { this(DEFAULT_BLOCK, DEFAULT_ALLOWED_VISIT_PER_SECOND); } @Override public boolean isOverLimit() { return currentQPS() > maxVisitPerSecond; } @Override public long currentQPS() { return count.get(); } @Override public boolean visit() { countPerBlock[index].incrementAndGet(); count.incrementAndGet(); return isOverLimit(); } @Override public void run() { System.out.println(isOverLimit()); System.out.println(currentQPS()); System.out.println("index:" + index); index = (index + 1) % block; long val = countPerBlock[index].getAndSet(0); count.addAndGet(-val); } public static void main(String[] args) { SlidingWindowRateLimiter slidingWindowRateLimiter = new SlidingWindowRateLimiter(10, 1000); ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor(); scheduledExecutorService.scheduleAtFixedRate(slidingWindowRateLimiter, 100, 100, TimeUnit.MILLISECONDS); new Thread(new Runnable() { @Override public void run() { while (true) { slidingWindowRateLimiter.visit(); try { Thread.sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } } } }).start(); new Thread(new Runnable() { @Override public void run() { while (true) { slidingWindowRateLimiter.visit(); try { Thread.sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } } } }).start(); } }
3:令牌桶算法
令牌桶算法是比较常见的限流算法之一,大概描述如下:
1)、所有的请求在处理之前都需要拿到一个可用的令牌才会被处理;
2)、根据限流大小,设置按照一定的速率往桶里添加令牌;
3)、桶设置最大的放置令牌限制,当桶满时、新添加的令牌就被丢弃或者拒绝;
4)、请求达到后首先要获取令牌桶中的令牌,拿着令牌才可以进行其他的业务逻辑,处理完业务逻辑之后,将令牌直接删除;
5)、令牌桶有最低限额,当桶中的令牌达到最低限额的时候,请求处理完之后将不会删除令牌,以此保证足够的限流;
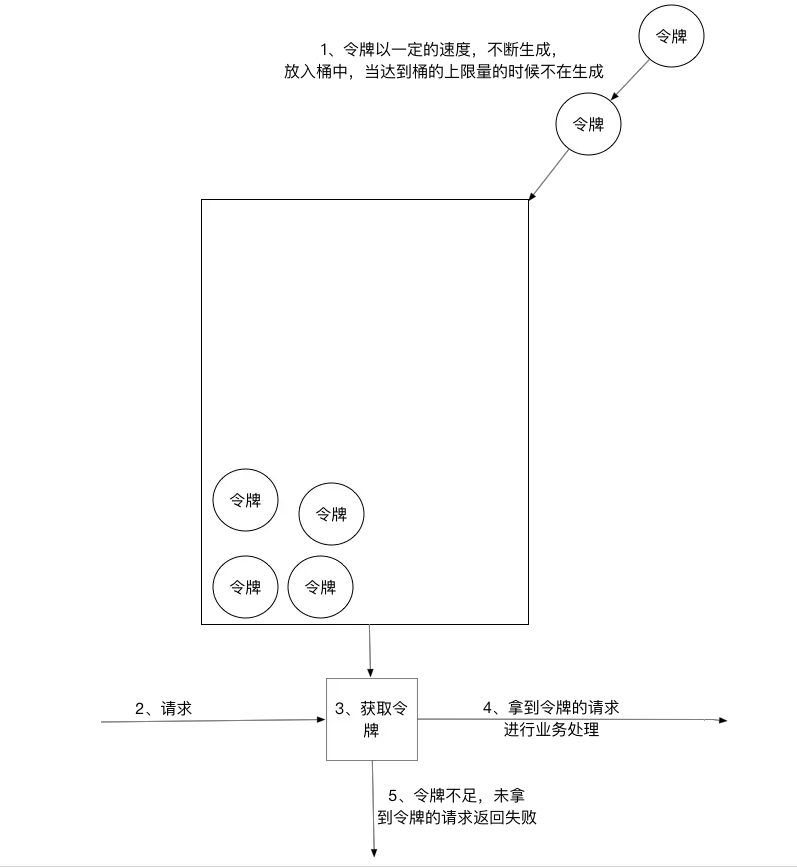
令牌桶算法并不能实际的控制速率。比如,10秒往桶里放入10000个令牌桶,即10秒内只能处理10000个请求,那么qps就是100。但这种模型可以出现1秒内把10000个令牌全部消费完,即qps为10000。所以令牌桶算法实际是限制的平均流速。具体控制的粒度以放令牌的间隔和每次的量来决定。若想要把流速控制的更加稳定,就要缩短间隔时间。
Google Guava中的RateLimter就是利用的令牌桶原理。
4:漏桶算法
漏桶算法其实很简单,可以粗略的认为就是注水漏水过程,往桶中以一定速率流出水,以任意速率流入水,当水超过桶流量则丢弃,因为桶容量是不变的,保证了整体的速率。
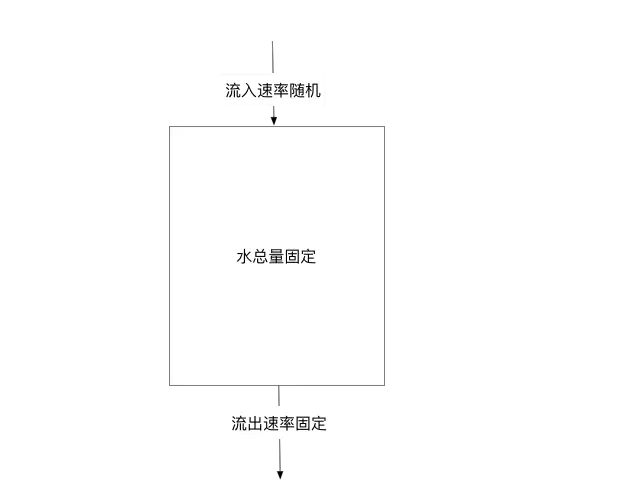
这种模型其实非常类似MQ的思想,利用漏桶削峰填谷,使得Queue的下游具有一个稳定流量。
什么是分布式限流?
首先当我们的服务是以多实例,集群形式存在的情况下才需要分布式限流。由于redis天生能够很好的支持分布式,因此分布式限流的实现redis就成了不二选择。分布式限流是基于单机限流范围的一个扩大,能够从服务集群的整体处理能力上做一个统一的流量管理,也是我们企业中常用的限流方式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号