redis 工具包
java通过jedis操作redis(从JedisPool到JedisCluster)
redis作为一个缓存数据库,在绝大多数java项目开发中是必须使用的,在web项目中,直接配合spring-redis,各种配置都直接在spring配置文件中做了,一般都是使用redis连接池。在非web项目中,通常也是使用的redis连接池。
根据redis的机器数量和集群方式,又分为以下三种方式:普通单机版的redis,多机器的分片集群,多机器的cluster集群方式(redis3版本以上)。
对于单机版的redis使用简单示例如下:
import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; import redis.clients.jedis.JedisPoolConfig; public class JedisPoolUtil { private static JedisPool jedisPool; public static JedisPool getJedisPool(){ if(jedisPool == null){ JedisPoolConfig config = new JedisPoolConfig(); config.setMaxIdle(200); config.setMaxIdle(50); config.setMaxWaitMillis(1000 * 100); config.setTestOnBorrow(false); jedisPool = new JedisPool(config, "192.168.42.128",6379); } return jedisPool; } public static String get(String key){ String value = null; JedisPool pool = null; Jedis jedis = null; try{ pool = getJedisPool(); jedis = pool.getResource(); value = jedis.get(key); }catch(Exception e){ e.printStackTrace(); } return value; } public static void set(String key,String value){ JedisPool pool = null; Jedis jedis = null; try{ pool = getJedisPool(); jedis = pool.getResource(); value = jedis.set(key,value); }catch(Exception e){ e.printStackTrace(); } } public static void main(String[] args) { set("name", "xx-jedis"); String name = get("name"); System.out.println(name); } }
这是一个最简单的demo,实际项目中,会配置redis host,port等信息,也会根据redis支持的方法和jedis的api,完善更多的方法,如delete,expire,sadd,lpush等等。
当项目增大,需要缓存的数据量增大,我们会考虑做分布式集群,集群的数量可以根据业务需求扩展。数据存储会均匀分布在各个分片上。这里给出一个示例:
import java.util.ArrayList; import java.util.List; import redis.clients.jedis.JedisPoolConfig; import redis.clients.jedis.JedisShardInfo; import redis.clients.jedis.ShardedJedis; import redis.clients.jedis.ShardedJedisPool; public class ShardedPoolUtil { private static ShardedJedisPool jedisPool; public static ShardedJedisPool getJedisPool(){ if(jedisPool == null){ JedisPoolConfig config = new JedisPoolConfig(); config.setMaxTotal(200); config.setMaxIdle(50); config.setMaxWaitMillis(1000*100); config.setTestOnBorrow(false); List<JedisShardInfo> shareInfos = new ArrayList<JedisShardInfo>(); shareInfos.add(new JedisShardInfo("192.168.42.128", 6379)); shareInfos.add(new JedisShardInfo("192.168.42.128", 6380)); jedisPool = new ShardedJedisPool(config, shareInfos); } return jedisPool; } public static void set(String key,String value){ ShardedJedisPool pool = null; ShardedJedis jedis = null; try{ pool = getJedisPool(); jedis = pool.getResource(); jedis.set(key, value); }catch(Exception e){ e.printStackTrace(); } } public static String get(String key){ String value = null; ShardedJedisPool pool = null; ShardedJedis jedis = null; try{ pool = getJedisPool(); jedis = pool.getResource(); value = jedis.get(key); } catch (Exception e) { e.printStackTrace(); } return value; } public static void main(String[] args) { String age = "30"; String address = "beijing"; set("age", age); set("address", address); System.out.println(get("age")); System.out.println(get("address")); } }
相对单机版的redis,sharding分布式集群方式:配置ShardedJedisPool多了设置多个redis服务器信息。 数据分布在哪个机器上,是有算法的,这里支持MD5和MURMUR两种散列函数的方式,默认采用的是MURMUR哈希方法。
这第二种方法,虽然是分布式的,数据分布在不同的机器上,但是并没有采用集群的方式,因为支持redis集群的是3.0版本及以上,目前redis集群方式,数据是以槽的方式分布的,因为需要保证一个master对应至少一个slave节点,所以节点数会比sharding分布式节点多。
redis-cluster这种情况下,java调用的方式会发生一些变化,但是还是相似的思路。
import java.util.HashSet; import java.util.Set; import redis.clients.jedis.HostAndPort; import redis.clients.jedis.JedisCluster; import redis.clients.jedis.JedisPoolConfig; public class ClusterPoolUtil { private static JedisCluster jedisCluster; private static String hostAndPorts = "192.168.42.128:6379||192.168.42.128:6380||" + "192.168.42.128:6381||192.168.42.128:6382||" + "192.168.42.128:6383||192.168.42.128:6384"; public static JedisCluster getJedisCluster(){ if(jedisCluster==null){ int timeOut = 10000; Set<HostAndPort> nodes = new HashSet<HostAndPort>(); JedisPoolConfig poolConfig = new JedisPoolConfig(); poolConfig.setMaxTotal(200); poolConfig.setMaxIdle(50); poolConfig.setMaxWaitMillis(1000 * 100); poolConfig.setTestOnBorrow(false); String[] hosts = hostAndPorts.split("\\|\\|"); for(String hostport:hosts){ String[] ipport = hostport.split(":"); String ip = ipport[0]; int port = Integer.parseInt(ipport[1]); nodes.add(new HostAndPort(ip, port)); } jedisCluster = new JedisCluster(nodes,timeOut, poolConfig); } return jedisCluster; } public static void set(String key,String value){ JedisCluster jedisCluster = getJedisCluster(); jedisCluster.set(key, value); } public static String get(String key){ String value = null; JedisCluster jedisCluster = getJedisCluster(); value = jedisCluster.get(key); return value; } public static void main(String[] args) { set("name-1", "value-1"); set("name-2", "value-2"); set("name-3", "value-3"); System.out.println(get("name-1")); System.out.println(get("name-2")); System.out.println(get("name-3")); } }
redis-cluster集群安装好了之后,做好slot分配,就可以开始使用redis存储和查找了。redis-cluster是redis3开始支持的,他与sharding分片方式不同的是,数据是按照slot槽(16384个slot)分布的,slot的划分不是固定的,可以人为指定。这里使用了六个节点,分为三组,所以slot划分为3组槽(5461,5461,5460),分别如下:
{ 0=192.168.42.128:6382, 5460=192.168.42.128:6382, 5461=192.168.42.128:6380, 10922=192.168.42.128:6380, 10923=192.168.42.128:6384, 16383=192.168.42.128:6384 }
第一组是0-5460,第二组是5461-10922,第三组是10993-16383,从分组中可以看出,6380,6382,6384端口的节点都是master节点,这可以在redis-cluster集群中查看:

存储的key分布在哪个槽上,可以通过如下方法获取:
public static int getSlot(String key){ return JedisClusterCRC16.getSlot(key); }
按照这种方法计算name-1,name-2,name-3的slot槽分别是:10801,6738,2675。按照之前的slot分布,可以得到name-1,name-2均落在6380上,name-3则落在6382上,我们可以在redis-cluster集群上通过命令来查找key,验证了这个结果: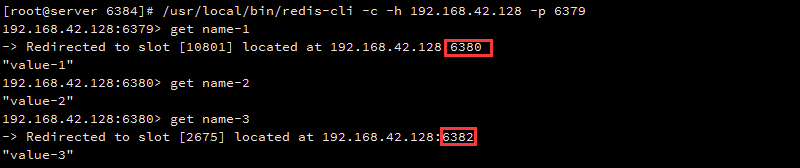

 浙公网安备 33010602011771号
浙公网安备 33010602011771号