TCP/IP 协议是如何保证数据可靠性的?
TCP协议传输的特点主要就是面向字节流、传输可靠、面向连接。这篇博客,我们就重点讨论一下TCP协议如何确保传输的可靠性的。
确保传输可靠性的方式
TCP协议保证数据传输可靠性的方式主要有:
1: 校验和
2: 序列号
3: 确认应答
4: 超时重传
5: 连接管理
6: 流量控制
7: 拥塞控制
校验和
计算方式:在数据传输的过程中,将发送的数据段都当做一个16位的整数。将这些整数加起来。并且前面的进位不能丢弃,补在后面,最后取反,得到校验和。
发送方:在发送数据之前计算检验和,并进行校验和的填充。
接收方:收到数据后,对数据以同样的方式进行计算,求出校验和,与发送方的进行比对。

注意:如果接收方比对校验和与发送方不一致,那么数据一定传输有误。但是如果接收方比对校验和与发送方一致,数据不一定传输成功。
确认应答与序列号
序列号:TCP传输时将每个字节的数据都进行了编号,这就是序列号。
确认应答:TCP传输的过程中,每次接收方收到数据后,都会对传输方进行确认应答。也就是发送ACK报文。这个ACK报文当中带有对应的确认序列号,告诉发送方,接收到了哪些数据,下一次的数据从哪里发。
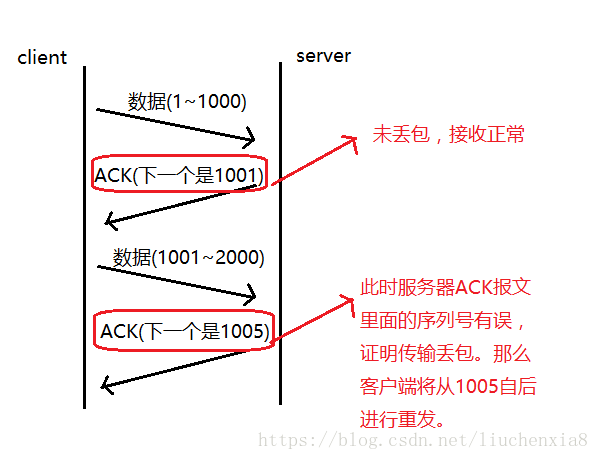
序列号的作用不仅仅是应答的作用,有了序列号能够将接收到的数据根据序列号排序,并且去掉重复序列号的数据。这也是TCP传输可靠性的保证之一。
超时重传
在进行TCP传输时,由于确认应答与序列号机制,也就是说发送方发送一部分数据后,都会等待接收方发送的ACK报文,并解析ACK报文,判断数据是否传输成功。如果发送方发送完数据后,迟迟没有等到接收方的ACK报文,这该怎么办呢?而没有收到ACK报文的原因可能是什么呢?
首先,发送方没有介绍到响应的ACK报文原因可能有两点:
1:数据在传输过程中由于网络原因等直接全体丢包,接收方根本没有接收到。
2:接收方接收到了响应的数据,但是发送的ACK报文响应却由于网络原因丢包了。
TCP在解决这个问题的时候引入了一个新的机制,叫做超时重传机制。简单理解就是发送方在发送完数据后等待一个时间,时间到达没有接收到ACK报文,那么对刚才发送的数据进行重新发送。如果是刚才第一个原因,接收方收到二次重发的数据后,便进行ACK应答。如果是第二个原因,接收方发现接收的数据已存在(判断存在的根据就是序列号,所以上面说序列号还有去除重复数据的作用),那么直接丢弃,仍旧发送ACK应答。
那么发送方发送完毕后等待的时间是多少呢?如果这个等待的时间过长,那么会影响TCP传输的整体效率,如果等待时间过短,又会导致频繁的发送重复的包。如何权衡?
由于TCP传输时保证能够在任何环境下都有一个高性能的通信,因此这个最大超时时间(也就是等待的时间)是动态计算的。
在Linux中(BSD Unix和Windows下也是这样)超时以500ms为一个单位进行控制,每次判定超时重发的超时时间都是500ms的整数倍。重发一次后,仍未响应,那么等待2*500ms的时间后,再次重传。等待4*500ms的时间继续重传。以一个指数的形式增长。累计到一定的重传次数,TCP就认为网络或者对端出现异常,强制关闭连接。
连接管理
连接管理就是三次握手与四次挥手的过程,在前面详细讲过这个过程,这里不再赘述。保证可靠的连接,是保证可靠性的前提。
流量控制
接收端在接收到数据后,对其进行处理。如果发送端的发送速度太快,导致接收端的结束缓冲区很快的填充满了。此时如果发送端仍旧发送数据,那么接下来发送的数据都会丢包,继而导致丢包的一系列连锁反应,超时重传呀什么的。而TCP根据接收端对数据的处理能力,决定发送端的发送速度,这个机制就是流量控制。
在TCP协议的报头信息当中,有一个16位字段的窗口大小。在介绍这个窗口大小时我们知道,窗口大小的内容实际上是接收端接收数据缓冲区的剩余大小。这个数字越大,证明接收端接收缓冲区的剩余空间越大,网络的吞吐量越大。接收端会在确认应答发送ACK报文时,将自己的即时窗口大小填入,并跟随ACK报文一起发送过去。而发送方根据ACK报文里的窗口大小的值的改变进而改变自己的发送速度。如果接收到窗口大小的值为0,那么发送方将停止发送数据。并定期的向接收端发送窗口探测数据段,让接收端把窗口大小告诉发送端。
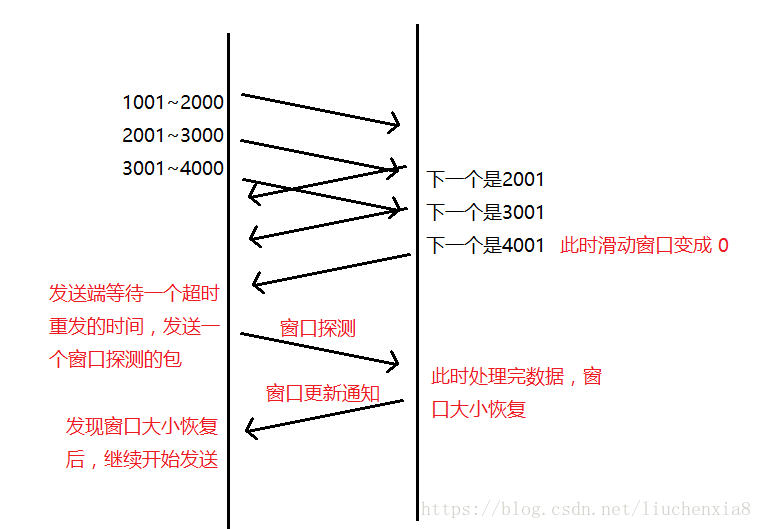
注:16位的窗口大小最大能表示65535个字节(64K),但是TCP的窗口大小最大并不是64K。在TCP首部中40个字节的选项中还包含了一个窗口扩大因子M,实际的窗口大小就是16为窗口字段的值左移M位。每移一位,扩大两倍。
拥塞控制
TCP传输的过程中,发送端开始发送数据的时候,如果刚开始就发送大量的数据,那么就可能造成一些问题。网络可能在开始的时候就很拥堵,如果给网络中在扔出大量数据,那么这个拥堵就会加剧。拥堵的加剧就会产生大量的丢包,就对大量的超时重传,严重影响传输。
所以TCP引入了慢启动的机制,在开始发送数据时,先发送少量的数据探路。探清当前的网络状态如何,再决定多大的速度进行传输。这时候就引入一个叫做拥塞窗口的概念。发送刚开始定义拥塞窗口为 1,每次收到ACK应答,拥塞窗口加 1。在发送数据之前,首先将拥塞窗口与接收端反馈的窗口大小比对,取较小的值作为实际发送的窗口。
拥塞窗口的增长是指数级别的。慢启动的机制只是说明在开始的时候发送的少,发送的慢,但是增长的速度是非常快的。为了控制拥塞窗口的增长,不能使拥塞窗口单纯的加倍,设置一个拥塞窗口的阈值,当拥塞窗口大小超过阈值时,不能再按照指数来增长,而是线性的增长。在慢启动开始的时候,慢启动的阈值等于窗口的最大值,一旦造成网络拥塞,发生超时重传时,慢启动的阈值会为原来的一半(这里的原来指的是发生网络拥塞时拥塞窗口的大小),同时拥塞窗口重置为 1。

拥塞控制是TCP在传输时尽可能快的将数据传输,并且避免拥塞造成的一系列问题。是可靠性的保证,同时也是维护了传输的高效性。
为了计算一份数据报的IP检验和,首先把检验和字段置为0。然后,对首部中每个16bit进行二进制反码求和(整个首部看成是由一串16bit的字组成),结果存在检验和字段中。当收到一份IP数据报后,同样对首部中每个16bit进行二进制反码的求和。由于接受方在计算过程中包含了发送方存在首部中的校验和。因此,如果首部在传输过程中没有发生任何差错,那么接受方计算的结果应该为全1。如果结果不是全1(即检验和错误),那么IP就丢弃收到的数据报。原文是这样的:
To compute the IP checksum for an outgoing datagram, the value of the checksum field is first
set to 0. Then the 16-bit one's complement sum of the header is calculated(i.e,the entire header is considered a sequence of 16-bit words). The 16-bit one's complement of this sum is stored in the checksum field. When an IP datagram is received, the 16-bit one's complement sum of the header is calculated. Since the receiver's calculated checksum contains the checksum stored by the sender, the receiver's checksum is all one bits if nothing in the header
was modified. If the result is not all one bits(a checksum error), IP discards the received datagram. No error message is generated. It is up to the higher layers to somehow detect the missing datagram and retransmit.
在读懂这段话之前,首先要了解究竟什么是Ones' complement。简单的说就是正数为其原码,负数其同绝对值对应正数所有bit取相反值。比如1的one's complement就是0000 0001,-1的one's complement 就是1111 1110 。+0的one's complement所有bit都是0, -0的one's complement所有bit都是1。
下面是一个简单的例子。发送前,假设IP头部20字节消息如下:
12 34 56 78 9A BC DE F0 12 34 00 00 9A BC DE F0 12 34 56 78其中校验和部分被暂时先置为00 00。
把这部分字节流按每两个字节为一单元分割,然后对分割后的所有两字节数进行二进制求和:
0x1234 + 0x5678 + 0x9ABC + 0xDEF0 + 0x1234 + 0x0000 + 0x9ABC +0xDEF0 + 0x1234 + 0x5678
0x0003 + 0xD6E4
最后我们对0xD6E7按位取反,
1101 0110 1110 0111 -> 0010 1001 0001 1000
12 34 56 78 9A BC DE F0 12 34 29 18 9A BC DE F0 12 34 56 78
接收方收到IP头部后,依旧把这部分消息按每两个字节为一单元分割,同样再对分割后的所有二字节数(包括校验和自身所在的字节)进行二进制求和。这个时候计算
0x1234 + 0x5678 + 0x9ABC + 0xDEF0 + 0x1234 + 0x2918 + 0x9ABC +0xDEF0 + 0x1234 + 0x56780x0003 + 0xFFFC

 浙公网安备 33010602011771号
浙公网安备 33010602011771号