阻塞I/O、非阻塞I/O和I/O多路复用、怎样理解阻塞非阻塞与同步异步的区别?
“阻塞”与"非阻塞"与"同步"与“异步"不能简单的从字面理解,提供一个从分布式系统角度的回答。
1.同步与异步
同步和异步关注的是消息通信机制 (synchronous communication/ asynchronous communication)
所谓同步,就是在发出一个*调用*时,在没有得到结果之前,该*调用*就不返回。但是一旦调用返回,就得到返回值了。
换句话说,就是由*调用者*主动等待这个*调用*的结果。
而异步则是相反,*调用*在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在*调用*发出后,*被调用者*通过状态、通知来通知调用者,或通过回调函数处理这个调用。
典型的异步编程模型比如Node.js
举个通俗的例子:
你打电话问书店老板有没有《分布式系统》这本书,如果是同步通信机制,书店老板会说,你稍等,”我查一下",然后开始查啊查,等查好了(可能是5秒,也可能是一天)告诉你结果(返回结果)。
而异步通信机制,书店老板直接告诉你我查一下啊,查好了打电话给你,然后直接挂电话了(不返回结果)。然后查好了,他会主动打电话给你。在这里老板通过“回电”这种方式来回调。
2. 阻塞与非阻塞
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.
阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
还是上面的例子,
你打电话问书店老板有没有《分布式系统》这本书,你如果是阻塞式调用,你会一直把自己“挂起”,直到得到这本书有没有的结果,如果是非阻塞式调用,你不管老板有没有告诉你,你自己先一边去玩了, 当然你也要偶尔过几分钟check一下老板有没有返回结果。
在这里阻塞与非阻塞与是否同步异步无关。跟老板通过什么方式回答你结果无关。
阻塞与非阻塞指的的是当不能进行读写(网卡满时的写/网卡空的时候的读)的时候,I/O操作立即返回还是阻塞;
同步异步指的是,当数据已经ready的时候,读写操作是同步读还是异步读,阶段不同而已。
阻塞I/O、非阻塞I/O和I/O多路复用
一、阻塞I/O
首先,要从你常用的IO操作谈起,比如read和write,通常IO操作都是阻塞I/O的,也就是说当你调用read时,如果没有数据收到,那么线程或者进程就会被挂起,直到收到数据。阻塞的意思,就是一直等着。阻塞I/O就是等着数据过来,进行读写操作。应用的函数进行调用,但是内核一直没有返回,就一直等着。应用的函数长时间处于等待结果的状态,我们就称为阻塞I/O。每个应用都得等着,每个应用都在等着,浪费啊!很像现实中的情况。大家都不干活,等着数据过来,过来工作一下,没有的话继续等着。
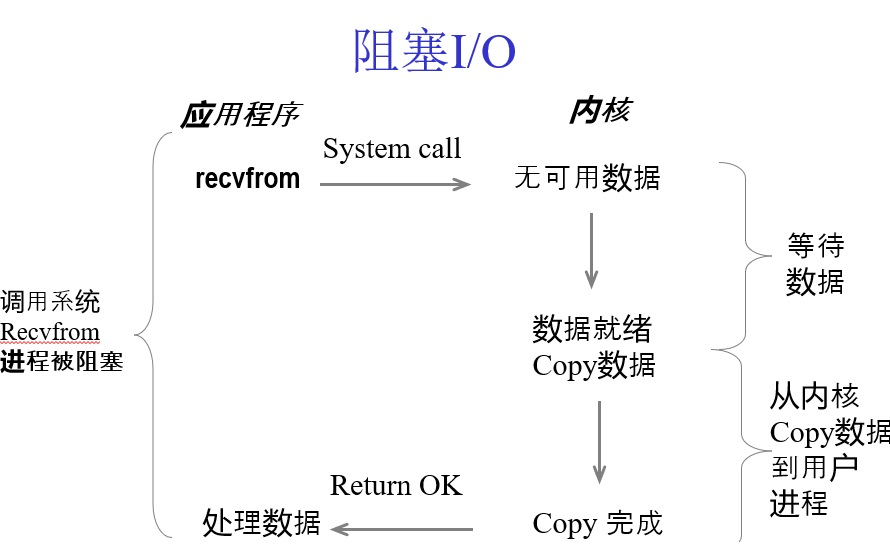
二、非阻塞I/O
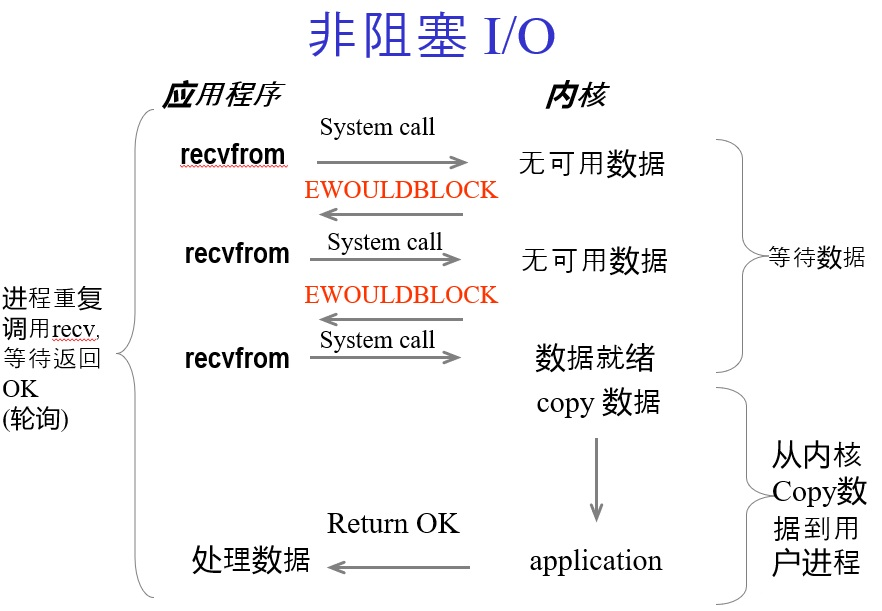
三、I/O多路复用
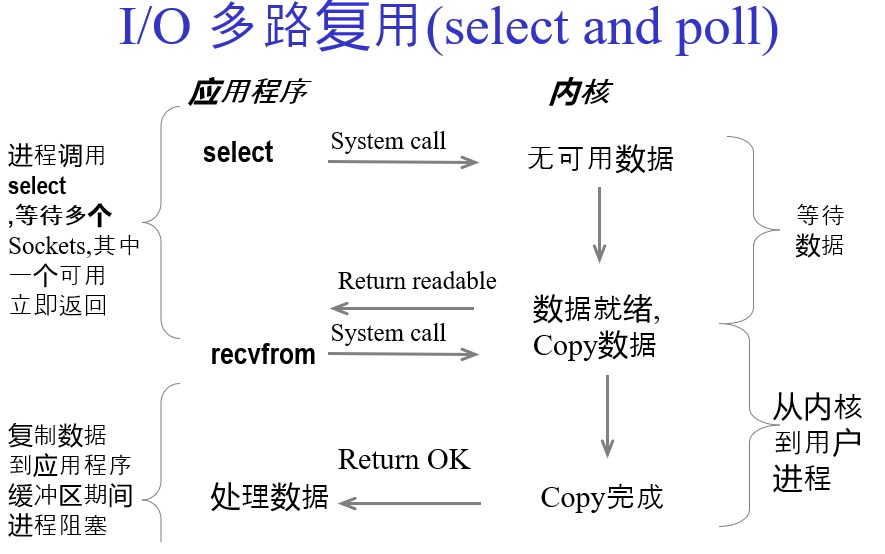
Redis,Nginx,Netty为什么这么香?
Redis,Nginx,Netty,Node.js 为什么这么香?这些技术都是伴随 Linux 内核迭代中提供了高效处理网络请求的系统调用而出现的。今天我们从操作系统层面理解 Linux 下的网络 IO 模型!
I/O( INPUT/OUTPUT),包括文件 I/O、网络 I/O。计算机世界里的速度鄙视:
-
内存读数据:纳秒级别。
-
千兆网卡读数据:微妙级别。1 微秒= 1000 纳秒,网卡比内存慢了千倍。
-
磁盘读数据:毫秒级别。1 毫秒=10 万纳秒 ,硬盘比内存慢了 10 万倍。
-
CPU 一个时钟周期 1 纳秒上下,内存算是比较接近 CPU 的,其他都等不起。
CPU 处理数据的速度远大于 I/O 准备数据的速度 。任何编程语言都会遇到这种 CPU 处理速度和 I/O 速度不匹配的问题!
在网络编程中如何进行网络 I/O 优化?怎么高效地利用 CPU 进行网络数据处理?
相关概念
从操作系统层面怎么理解网络 I/O 呢?计算机的世界有一套自己定义的概念。
如果不明白这些概念,就无法真正明白技术的设计思路和本质。所以在我看来,这些概念是了解技术和计算机世界的基础。
同步与异步,阻塞与非阻塞
理解网络 I/O 避不开的话题:同步与异步,阻塞与非阻塞。
拿山治烧水举例来说,(山治的行为好比用户程序,烧水好比内核提供的系统调用),这两组概念翻译成大白话可以这么理解:
-
同步/异步关注的是水烧开之后需不需要我来处理。
-
阻塞/非阻塞关注的是在水烧开的这段时间是不是干了其他事。
同步阻塞:点火后,傻等,不等到水开坚决不干任何事(阻塞),水开了关火(同步)。

同步非阻塞:点火后,去看电视(非阻塞),时不时看水开了没有,水开后关火(同步)。
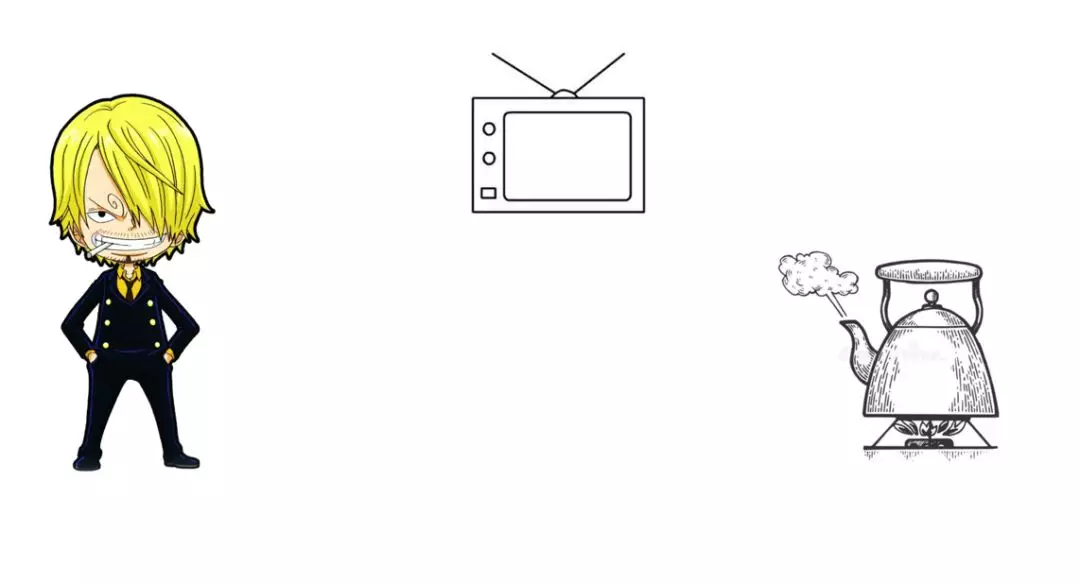
异步阻塞:按下开关后,傻等水开(阻塞),水开后自动断电(异步)。

网络编程中不存在的模型。
异步非阻塞:按下开关后,该干嘛干嘛 (非阻塞),水开后自动断电(异步)。
内核空间 、用户空间
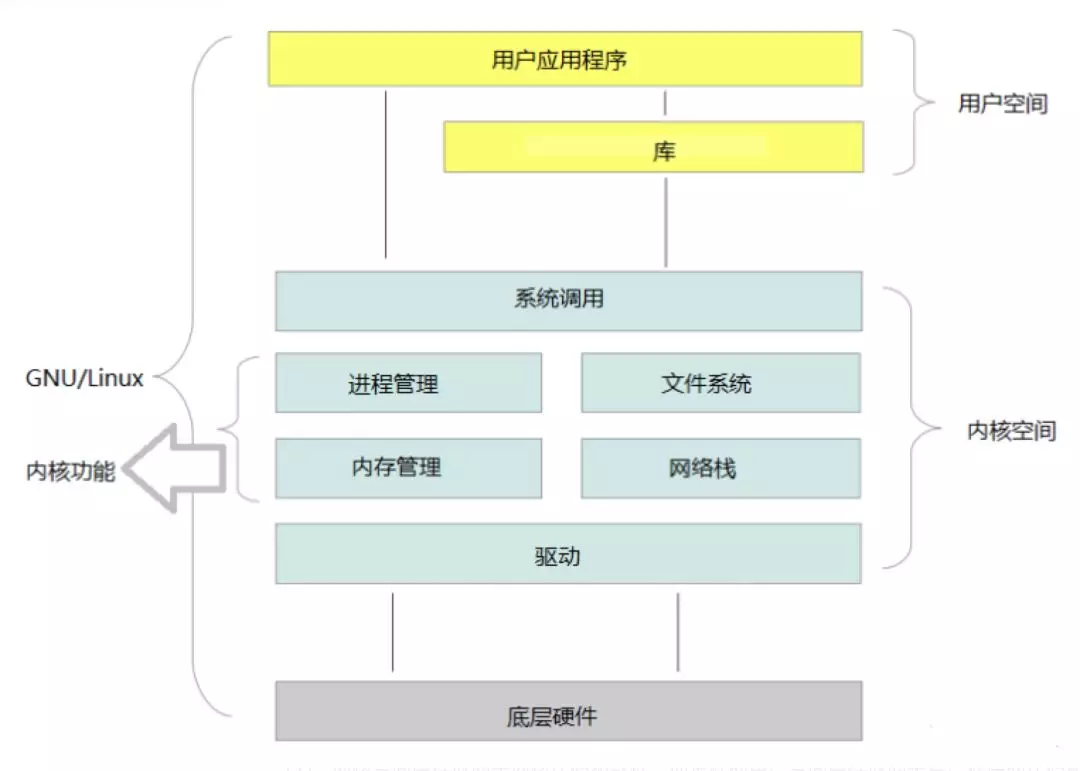
内核空间 、用户空间如上图:
-
内核负责网络和文件数据的读写。
- 用户程序通过系统调用获得网络和文件的数据。

内核态、用户态如上图:
-
程序为读写数据不得不发生系统调用。
-
通过系统调用接口,线程从用户态切换到内核态,内核读写数据后,再切换回来。
- 进程或线程的不同空间状态。

线程的切换如上图,用户态和内核态的切换耗时,费资源(内存、CPU)。
优化建议:
-
更少的切换。
-
共享空间。
套接字:Socket

套接字作用如下:
-
有了套接字,才可以进行网络编程。
-
应用程序通过系统调用 socket(),建立连接,接收和发送数据(I/O)。
-
Socket 支持了非阻塞,应用程序才能非阻塞调用,支持了异步,应用程序才能异步调用。
文件描述符:FD 句柄

![]()

网络编程都需要知道 FD???FD 是个什么鬼???Linux:万物都是文件,FD 就是文件的引用。
像不像 Java 中万物都是对象?程序中操作的是对象的引用。Java 中创建对象的个数有内存的限制,同样 FD 的个数也是有限制的。

Linux 在处理文件和网络连接时,都需要打开和关闭 FD。
每个进程都会有默认的 FD:
-
0 标准输入 stdin
-
1 标准输出 stdout
-
2 错误输出 stderr
服务端处理网络请求的过程

服务端处理网络请求的过程如上图:
-
连接建立后。
-
等待数据准备好(CPU 闲置)。
-
将数据从内核拷贝到进程中(CPU 闲置)。
怎么优化呢?对于一次 I/O 访问(以 read 举例),数据会先被拷贝到操作系统内核的缓冲区,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。
所以说,当一个 read 操作发生时,它会经历两个阶段:
-
等待数据准备 (Waiting for the data to be ready)。
-
将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)。
正是因为这两个阶段,Linux 系统升级迭代中出现了下面三种网络模式的解决方案。
I/O 模型
阻塞 I/O:Blocking I/O
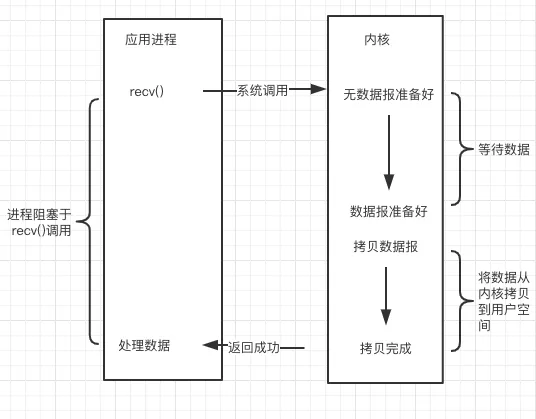
简介:最原始的网络 I/O 模型。进程会一直阻塞,直到数据拷贝完成。
缺点:高并发时,服务端与客户端对等连接。
线程多带来的问题:
-
CPU 资源浪费,上下文切换。
- 内存成本几何上升,JVM 一个线程的成本约 1MB。
public static void main(String[] args) throws IOException { ServerSocket ss = new ServerSocket(); ss.bind(new InetSocketAddress(Constant.HOST, Constant.PORT)); int idx =0; while (true) { final Socket socket = ss.accept();//阻塞方法 new Thread(() -> { handle(socket); },"线程["+idx+"]" ).start(); } } static void handle(Socket socket) { byte[] bytes = new byte[1024]; try { String serverMsg = " server sss[ 线程:"+ Thread.currentThread().getName() +"]"; socket.getOutputStream().write(serverMsg.getBytes());//阻塞方法 socket.getOutputStream().flush(); } catch (Exception e) { e.printStackTrace(); } }
非阻塞 I/O:Non Blocking IO
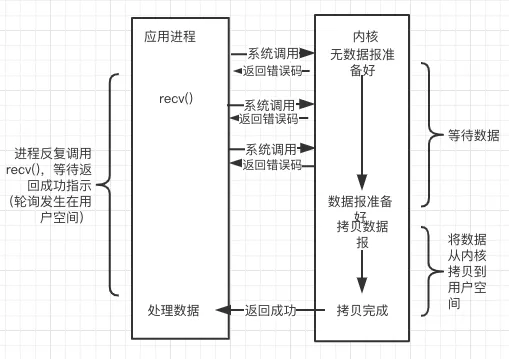
简介:进程反复系统调用,并马上返回结果。
缺点:当进程有 1000fds,代表用户进程轮询发生系统调用 1000 次 kernel,来回的用户态和内核态的切换,成本几何上升。
public static void main(String[] args) throws IOException { ServerSocketChannel ss = ServerSocketChannel.open(); ss.bind(new InetSocketAddress(Constant.HOST, Constant.PORT)); System.out.println(" NIO server started ... "); ss.configureBlocking(false); int idx =0; while (true) { final SocketChannel socket = ss.accept();//阻塞方法 new Thread(() -> { handle(socket); },"线程["+idx+"]" ).start(); } } static void handle(SocketChannel socket) { try { socket.configureBlocking(false); ByteBuffer byteBuffer = ByteBuffer.allocate(1024); socket.read(byteBuffer); byteBuffer.flip(); System.out.println("请求:" + new String(byteBuffer.array())); String resp = "服务器响应"; byteBuffer.get(resp.getBytes()); socket.write(byteBuffer); } catch (IOException e) { e.printStackTrace(); } }
I/O 多路复用:IO multiplexing
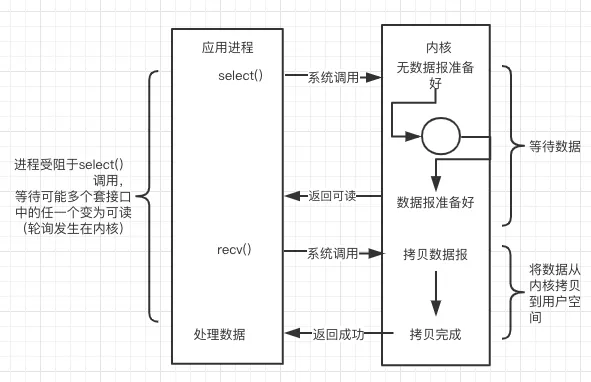
简介:单个线程就可以同时处理多个网络连接。内核负责轮询所有 Socket,当某个 Socket 有数据到达了,就通知用户进程。
多路复用在 Linux 内核代码迭代过程中依次支持了三种调用,即 Select、Poll、Epoll 三种多路复用的网络 I/O 模型。下文将画图结合 Java 代码解释。
①I/O 多路复用:Select
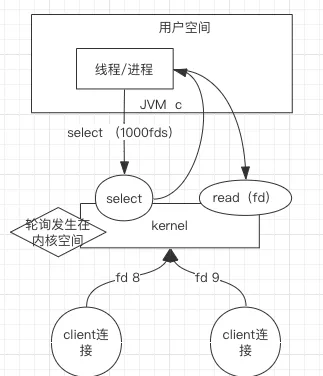
简介:有连接请求抵达了再检查处理。
缺点如下:
-
句柄上限:默认打开的 FD 有限制,1024 个。
-
重复初始化:每次调用 select(),需要把 FD 集合从用户态拷贝到内核态,内核进行遍历。
-
逐个排查所有 FD 状态效率不高。
服务端的 Select 就像一块布满插口的插排,Client 端的连接连上其中一个插口,建立了一个通道,然后再在通道依次注册读写事件。
一个就绪、读或写事件处理时一定记得删除,要不下次还能处理。
public static void main(String[] args) throws IOException { ServerSocketChannel ssc = ServerSocketChannel.open();//管道型ServerSocket ssc.socket().bind(new InetSocketAddress(Constant.HOST, Constant.PORT)); ssc.configureBlocking(false);//设置非阻塞 System.out.println(" NIO single server started, listening on :" + ssc.getLocalAddress()); Selector selector = Selector.open(); ssc.register(selector, SelectionKey.OP_ACCEPT);//在建立好的管道上,注册关心的事件 就绪 while(true) { selector.select(); Set<SelectionKey> keys = selector.selectedKeys(); Iterator<SelectionKey> it = keys.iterator(); while(it.hasNext()) { SelectionKey key = it.next(); it.remove();//处理的事件,必须删除 handle(key); } } } private static void handle(SelectionKey key) throws IOException { if(key.isAcceptable()) { ServerSocketChannel ssc = (ServerSocketChannel) key.channel(); SocketChannel sc = ssc.accept(); sc.configureBlocking(false);//设置非阻塞 sc.register(key.selector(), SelectionKey.OP_READ );//在建立好的管道上,注册关心的事件 可读 } else if (key.isReadable()) { //flip SocketChannel sc = null; sc = (SocketChannel)key.channel(); ByteBuffer buffer = ByteBuffer.allocate(512); buffer.clear(); int len = sc.read(buffer); if(len != -1) { System.out.println("[" +Thread.currentThread().getName()+"] recv :"+ new String(buffer.array(), 0, len)); } ByteBuffer bufferToWrite = ByteBuffer.wrap("HelloClient".getBytes()); sc.write(bufferToWrite); } }
②I/O 多路复用:Poll

简介:设计新的数据结构(链表)提供使用效率。
Poll 和 Select 相比在本质上变化不大,只是 Poll 没有了 Select 方式的最大文件描述符数量的限制。
缺点:逐个排查所有 FD 状态效率不高。
③I/O 多路复用:Epoll
简介:没有 FD 个数限制,用户态拷贝到内核态只需要一次,使用事件通知机制来触发。
通过 epoll_ctl 注册 FD,一旦 FD 就绪就会通过 Callback 回调机制来激活对应 FD,进行相关的 I/O 操作。
缺点如下:
-
跨平台,Linux 支持最好。
-
底层实现复杂。
- 同步。
public static void main(String[] args) throws Exception { final AsynchronousServerSocketChannel serverChannel = AsynchronousServerSocketChannel.open() .bind(new InetSocketAddress(Constant.HOST, Constant.PORT)); serverChannel.accept(null, new CompletionHandler<AsynchronousSocketChannel, Object>() { @Override public void completed(final AsynchronousSocketChannel client, Object attachment) { serverChannel.accept(null, this); ByteBuffer buffer = ByteBuffer.allocate(1024); client.read(buffer, buffer, new CompletionHandler<Integer, ByteBuffer>() { @Override public void completed(Integer result, ByteBuffer attachment) { attachment.flip(); client.write(ByteBuffer.wrap("HelloClient".getBytes()));//业务逻辑 } @Override public void failed(Throwable exc, ByteBuffer attachment) { System.out.println(exc.getMessage());//失败处理 } }); } @Override public void failed(Throwable exc, Object attachment) { exc.printStackTrace();//失败处理 } }); while (true) { //不while true main方法一瞬间结束 } }
当然上面的缺点相比较它的优点都可以忽略。JDK 提供了异步方式实现,但在实际的 Linux 环境中底层还是 Epoll,只不过多了一层循环,不算真正的异步非阻塞。
而且就像上图中代码调用,处理网络连接的代码和业务代码解耦得不够好。
Netty 提供了简洁、解耦、结构清晰的 API。
public static void main(String[] args) { new NettyServer().serverStart(); System.out.println("Netty server started !"); } public void serverStart() { EventLoopGroup bossGroup = new NioEventLoopGroup(); EventLoopGroup workerGroup = new NioEventLoopGroup(); ServerBootstrap b = new ServerBootstrap(); b.group(bossGroup, workerGroup) .channel(NioServerSocketChannel.class) .childHandler(new ChannelInitializer<SocketChannel>() { @Override protected void initChannel(SocketChannel ch) throws Exception { ch.pipeline().addLast(new Handler()); } }); try { ChannelFuture f = b.localAddress(Constant.HOST, Constant.PORT).bind().sync(); f.channel().closeFuture().sync(); } catch (InterruptedException e) { e.printStackTrace(); } finally { workerGroup.shutdownGracefully(); bossGroup.shutdownGracefully(); } } } class Handler extends ChannelInboundHandlerAdapter { @Override public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { ByteBuf buf = (ByteBuf) msg; ctx.writeAndFlush(msg); ctx.close(); } @Override public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception { cause.printStackTrace(); ctx.close(); } }
bossGroup 处理网络请求的大管家(们),网络连接就绪时,交给 workGroup 干活的工人(们)。
总结
回顾上文总结如下:
-
同步/异步,连接建立后,用户程序读写时,如果最终还是需要用户程序来调用系统 read() 来读数据,那就是同步的,反之是异步。Windows 实现了真正的异步,内核代码甚为复杂,但对用户程序来说是透明的。
-
阻塞/非阻塞,连接建立后,用户程序在等待可读可写时,是不是可以干别的事儿。如果可以就是非阻塞,反之阻塞。大多数操作系统都支持的。
Redis,Nginx,Netty,Node.js 为什么这么香?这些技术都是伴随 Linux 内核迭代中提供了高效处理网络请求的系统调用而出现的。
了解计算机底层的知识才能更深刻地理解 I/O,知其然,更要知其所以然。与君共勉!
相关文章:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号