大批量数据高效插入数据库表
对于一些数据量较大的系统,数据库面临的问题除了查询效率低下,还有就是数据入库时间长。特别像报表系统,每天花费在数据导入上的时间可能会长达几个小时或十几个小时之久。因此,优化数据库插入性能是很有意义的。
经过对MySQL InnoDB的一些性能测试,发现一些可以提高insert效率的方法,供大家参考参考。
1、一条SQL语句插入多条数据
常用的插入语句如:
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('0', 'userid_0', 'content_0', 0);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('1', 'userid_1', 'content_1', 1);
修改成:
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('0', 'userid_0', 'content_0', 0), ('1', 'userid_1', 'content_1', 1);
修改后的插入操作能够提高程序的插入效率。这里第二种SQL执行效率高的主要原因是: (1)通过合并SQL语句,同时也能减少SQL语句解析的次数,减少了数据库连接的I/O开销,一般会把多条数据插入放在一条SQL语句中一次执行; (2)合并后日志量(MySQL的binlog和innodb的事务让日志)减少了,降低日志刷盘的数据量和频率,从而提高效率。
这里提供一些测试对比数据,分别是进行单条数据的导入与转化成一条SQL语句进行导入,分别测试1百、1千、1万条数据记录。
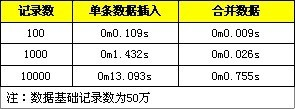
批量插入的确是比一条条插入效率高的多
批量插入如果数据量太大可能出现下面的情况:
MySQL报错:Packets larger than max_allowed_packet are not allowed (通过修改max_allowed_packet的值来解决,show VARIABLES like '%max_allowed_packet%';)
2、在事务中进行插入处理。
把插入修改成:
START TRANSACTION;
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('0', 'userid_0', 'content_0', 0);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('1', 'userid_1', 'content_1', 1);
...
COMMIT;
使用事务可以提高数据的插入效率,这是因为进行一个INSERT操作时,MySQL内部会建立一个事务,在事务内才进行真正插入处理操作。通过使用事务可以减少创建事务的消耗,所有插入都在执行后才进行提交操作。
这里也提供了测试对比,分别是不使用事务与使用事务在记录数为1百、1千、1万的情况。
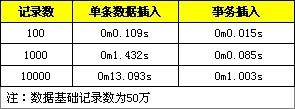
3、数据有序插入
数据有序的插入是指插入记录在主键上是有序排列,例如datetime是记录的主键:
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('1', 'userid_1', 'content_1', 1);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('0', 'userid_0', 'content_0', 0);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('2', 'userid_2', 'content_2',2);
修改成:
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('0', 'userid_0', 'content_0', 0);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('1', 'userid_1', 'content_1', 1);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('2', 'userid_2', 'content_2',2);
由于数据库插入时,需要维护索引数据,无序的记录会增大维护索引的成本。我们可以参照InnoDB使用的B+tree索引,如果每次插入记录都在索引的最后面,索引的定位效率很高,并且对索引调整较小;如果插入的记录在索引中间,需要B+tree进行分裂合并等处理,会消耗比较多计算资源,并且插入记录的索引定位效率会下降,数据量较大时会有频繁的磁盘操作。
下面提供随机数据与顺序数据的性能对比,分别是记录为1百、1千、1万、10万、100万。
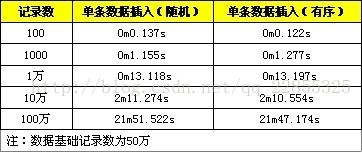
从测试结果来看,该优化方法的性能有所提高,但是提高并不是很明显。
4、性能综合测试
这里提供了同时使用上面三种方法进行INSERT效率优化的测试。
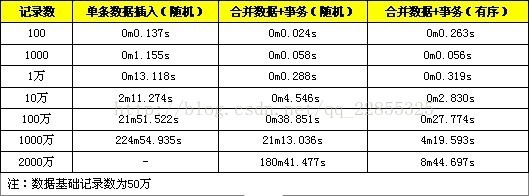
从测试结果可以看到,合并数据+事务的方法在较小数据量时,性能提高是很明显的,数据量较大时(1千万以上),性能会急剧下降,这是由于此时数据量超过了innodb_buffer的容量,每次定位索引涉及较多的磁盘读写操作,性能下降较快。而使用合并数据+事务+有序数据的方式在数据量达到千万级以上表现依旧是良好,在数据量较大时,有序数据索引定位较为方便,不需要频繁对磁盘进行读写操作,所以可以维持较高的性能。
注意事项:
-
SQL语句是有长度限制,在进行数据合并在同一SQL中务必不能超过SQL长度限制,通过max_allowed_packet配置可以修改,默认是1M,测试时修改为8M。 -
事务需要控制大小,事务太大可能会影响执行的效率。MySQL有innodb_log_buffer_size配置项,超过这个值会把innodb的数据刷到磁盘中,这时,效率会有所下降。所以比较好的做法是,在数据达到这个这个值前进行事务提交。
数据批量操作
批量执行更新sql语句的优缺点分析:
情况一:mysql 默认是autocommit=on也就是默认开启自动提交事务。这种情况下,一条sql就会开启一个事务,这时候同时执行一万条update,就会导致实际开启一万个事务,然后挨个执行,挨个开启,挨个提交。
缺点:同时锁住数据较少,但是数据库资源占用严重,对外提供操作性能急剧下降。
情况二:当autocommit=off时,同时执行一万条update,那么只会开启一个事务,等到所有都update后,一并commit。
缺点:同时锁住数据较多,外面的select进不来,大量连接等待获取行锁,同样影响数据库对外服务能力。
最终优化方案:
建议,把autocommit设置off,然后执行update的时候,手动分批commit,分批条数限制100,或者200,比如一万条update,按照每100条 就commit一次,10000个update总共需要100个事务,每次锁住100条数据。性能将会得到很大提升。
当然,选择多少条手动commit,这个需要根据各自业务实际情况而定。
/**
* 对数据库进行批量插入数据操作
* 执行次数100万
*/
public void insertBatch() {
//思路:将100万条数据分成n等份,1等份为1000条数据
//如何实现?
//1、必须将Connection接口的自动提交方式改为手动
//2、利用Statement接口中的如下三个方法:addBatch、clearBath、executeBatch
try {
conn = DriverManager.getConnection(url, username, password);
conn.setAutoCommit(false);
stmt = conn.createStatement();
for (int i = 0; i < 1000000; i++) {
String sql = "insert into batch values ('"+i+"', '第"+i+"条数据')";
//利用addBatch方法将SQL语句加入到stmt对象中
stmt.addBatch(sql);
if (i % 1000 == 0 && i != 0) {
//利用executeBatch方法执行1000条SQL语句
stmt.executeBatch();
stmt.clearBatch();
conn.commit();
}
}
stmt.executeBatch();
stmt.clearBatch();
conn.commit();
close(); //关闭资源
} catch (SQLException e) {
e.printStackTrace();
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号