分布式均匀算法--hash性一致算法--hash slot(转)
目录
1、redis cluster介绍
2、最老土的hash算法和弊端(大量缓存重建)
3、一致性hash算法(自动缓存迁移)+虚拟节点(自动负载均衡)
不用遍历 --》 hash算法: 缓存位置= hash(key)%n
新增/减少 节点 --》缓存位置失效--》hash环
hash环 节点少--》数据倾斜--》添加虚拟节点
4、redis cluster的hash slot算法
分布式寻址算法
- hash 算法(大量缓存重建)
- 一致性 hash 算法(自动缓存迁移)+ 虚拟节点(自动负载均衡)
- redis cluster 的 hash slot 算法
1、redis cluster介绍
redis cluster
(1)自动将数据进行分片,每个master上放一部分数据
(2)提供内置的高可用支持,部分master不可用时,还是可以继续工作的
在redis cluster架构下,每个redis要放开两个端口号,比如一个是6379,另外一个就是加10000的端口号,比如16379
16379端口号是用来进行节点间通信的,也就是cluster bus的东西,集群总线。cluster bus的通信,用来进行故障检测,配置更新,故障转移授权
cluster bus用了另外一种二进制的协议,主要用于节点间进行高效的数据交换,占用更少的网络带宽和处理时间
2、最老土的hash算法(弊端:大量缓存重建)
来了一个 key,首先计算 hash 值,然后对节点数取模。然后打在不同的 master 节点上。一旦某一个 master 节点宕机,所有请求过来,都会基于最新的剩余 master 节点数去取模,尝试去取数据。这会导致大部分的请求过来,全部无法拿到有效的缓存,导致大量的流量涌入数据库。

3、一致性hash算法(自动缓存迁移)+虚拟节点(自动负载均衡)
做成一个圆环,解决命中率问题。
一致性 hash 算法将整个 hash 值空间组织成一个虚拟的圆环,整个空间按顺时针方向组织,下一步将各个 master 节点(使用服务器的 ip 或主机名)进行 hash。这样就能确定每个节点在其哈希环上的位置。
来了一个 key,首先计算 hash 值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,遇到的第一个 master 节点就是 key 所在位置。
在一致性哈希算法中,如果一个节点挂了,受影响的数据仅仅是此节点到环空间前一个节点(沿着逆时针方向行走遇到的第一个节点)之间的数据,其它不受影响。增加一个节点也同理。
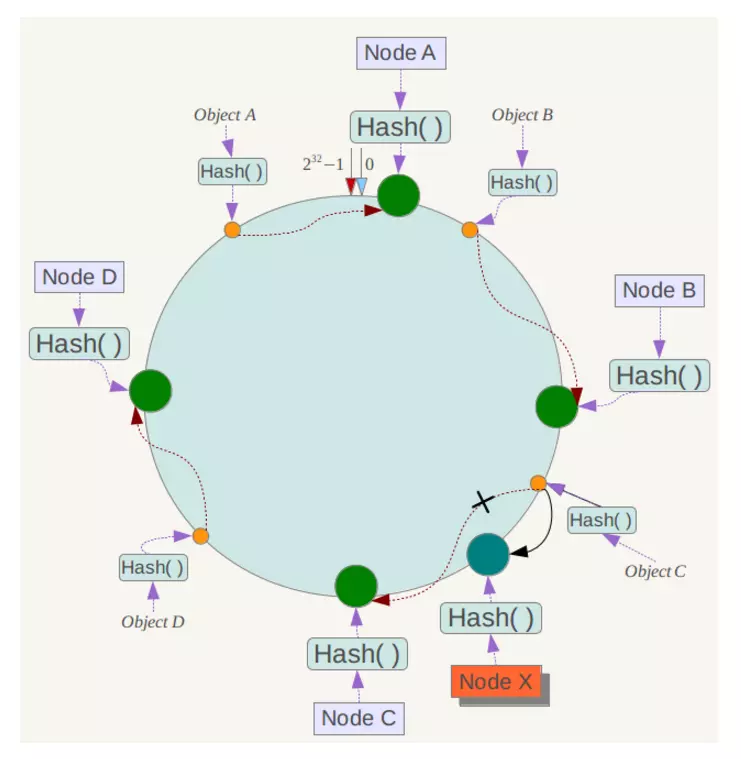
然而,一致性哈希算法在节点太少时,容易因为节点分布不均匀而造成缓存热点的问题。为了解决这种热点问题,一致性 hash 算法引入了虚拟节点机制,即对每一个节点计算多个 hash,每个计算结果位置都放置一个虚拟节点。这样就实现了数据的均匀分布,负载均衡。一致性hash算法更详细的请看这篇:一致性Hash算法
一致性hash算法(redis集群就是这个原理):
1、我们把全量的缓存空间当做一个环形存储结构。环形空间总共分成2^32个缓存区,在Redis中则是把缓存key分配到16384个slot。

2、每一个缓存key都可以通过Hash算法转化为一个32位的二进制数,也就对应着环形空间的某一个缓存区。我们把所有的缓存key映射到环形空间的不同位置。

3、我们的每一个缓存节点(Shard)也遵循同样的Hash算法,比如利用IP做Hash,映射到环形空间当中。
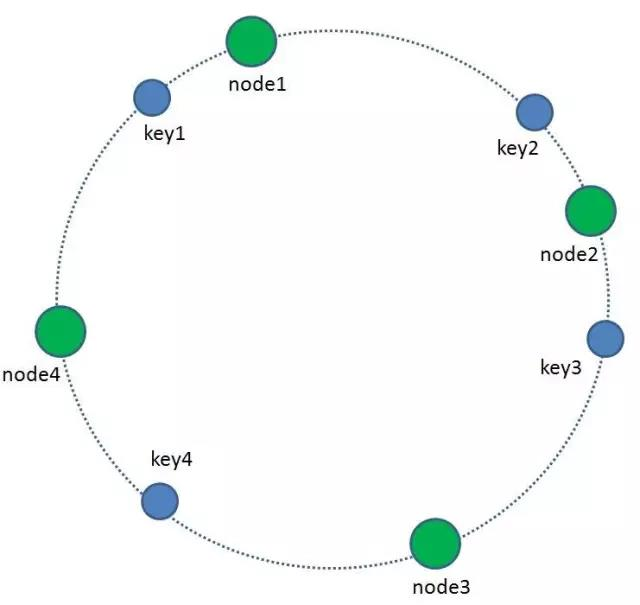
4、如何让key和节点对应起来呢?很简单,每一个key的顺时针方向最近节点,就是key所归属的存储节点。所以图中key1存储于node1,key2,key3存储于node2,key4存储于node3。
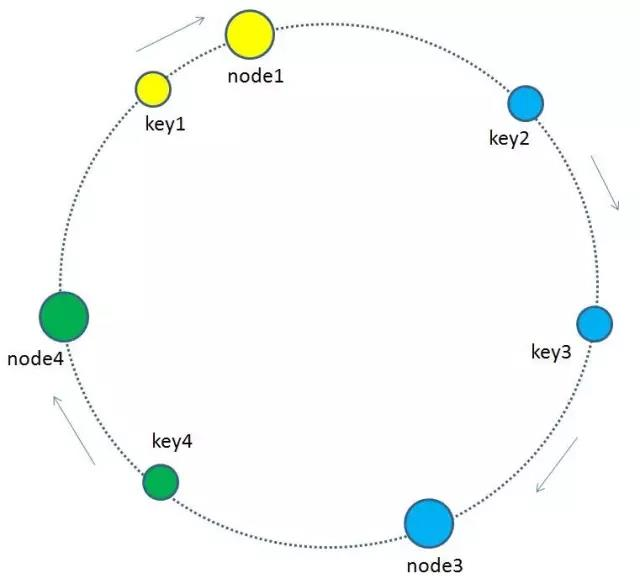
增加节点时:
当缓存集群的节点有所增加的时候,整个环形空间的映射仍然会保持一致性哈希的顺时针规则,所以有一小部分key的归属会受到影响。

有哪些key会受到影响呢? 图中加入了新节点node4,处于node1和node2之间,按照顺时针规则,从node1到node4之间的缓存不再归属于node2,而是归属于新节点node4。因此受影响的key只有key2。(我理解计算同一个key的hash值不变,但是挂载到不同的节点中,原节点的数据还存在,因此存在数据的冗余, 但是实际在测试时这个想法是错的. 因为在新增加节点的时候, 重新分配slot槽点时, 会将原来槽点中保存的数据会移动到新的节点中, 原来槽点中的数据也已经不存在, 因此不存在数据的冗余.)
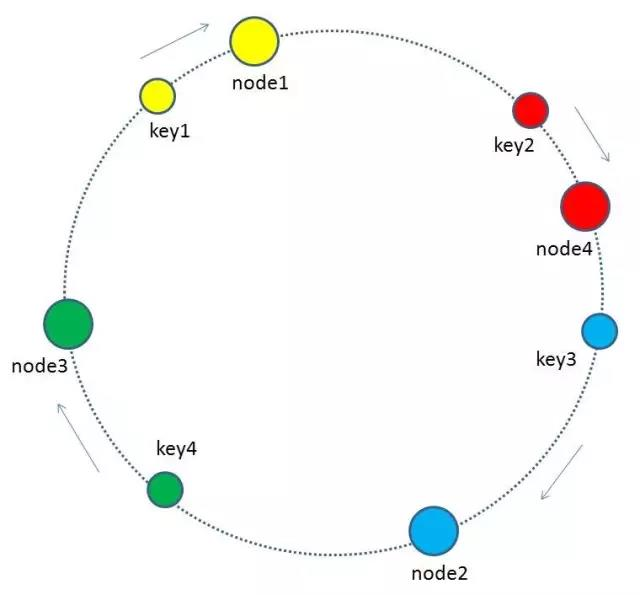
最终把key2的缓存数据从node2迁移到node4,就形成了新的符合一致性哈希规则的缓存结构。
删除节点
当缓存集群的节点需要删除的时候(比如节点挂掉),整个环形空间的映射同样会保持一致性哈希的顺时针规则,同样有一小部分key的归属会受到影响。

有哪些key会受到影响呢?图中删除了原节点node3,按照顺时针规则,原本node3所拥有的缓存数据就需要“托付”给node3的顺时针后继节点node1。因此受影响的key只有key4。

最终把key4的缓存数据从node3迁移到node1,就形成了新的符合一致性哈希规则的缓存结构.
由于node3已经挂掉,原来在node3上的节点缓存的数据不是直接从node3迁移过去,而是在再次查询时去查询顺时针的后续的后继节点,因缓存没有命中而刷新缓存,重新挂载到新的节点中.
5、每个缓存节点都按照iphash到环形空间,可能出现分布不均的情况,因此为了优化引入了虚拟节点.基于原来的物理节点映射出N个子节点,最后全部映射到环形空间.
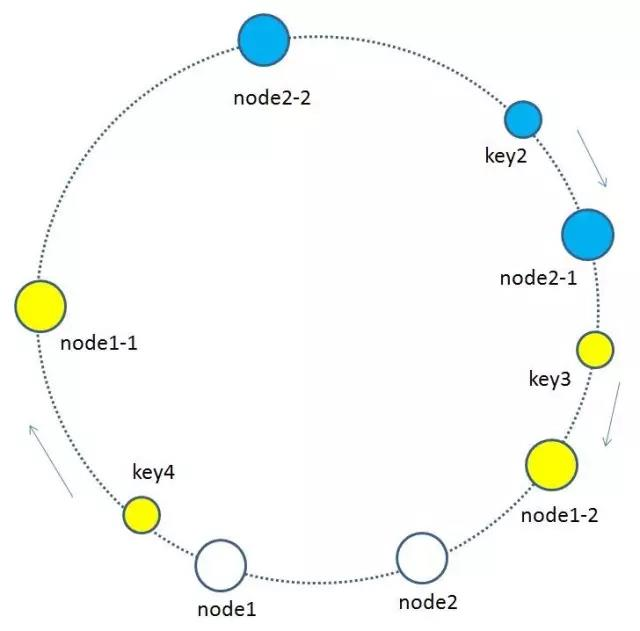
如上图所示,假如node1的ip是192.168.1.109,那么原node1节点在环形空间的位置就是hash(“192.168.1.109”)。
我们基于node1构建两个虚拟节点,node1-1 和 node1-2,虚拟节点在环形空间的位置可以利用(IP+后缀)计算,例如:
hash(“192.168.1.109#1”),hash(“192.168.1.109#2”)
此时,环形空间中不再有物理节点node1,node2,只有虚拟节点node1-1,node1-2,node2-1,node2-2。由于虚拟节点数量较多,缓存key与虚拟节点的映射关系也变得相对均衡了。
4、redis cluster的hash slot算法
redis cluster 有固定的 16384 个 hash slot,对每个 key 计算 CRC16 值,然后对 16384 取模,可以获取 key 对应的 hash slot。每个节点负责维护一部分槽以及槽所映射的键值数据。
redis cluster 中每个 master 都会持有部分 slot,比如有 3 个 master,那么可能每个 master 持有 5000 多个 hash slot。hash slot 让 node 的增加和移除很简单,增加一个 master,就将其他 master 的 hash slot 移动部分过去,减少一个 master,就将它的 hash slot 移动到其他 master 上去。移动 hash slot 的成本是非常低的。客户端的 api,可以对指定的数据,让他们走同一个 hash slot,通过 hash tag 来实现。

举个例子
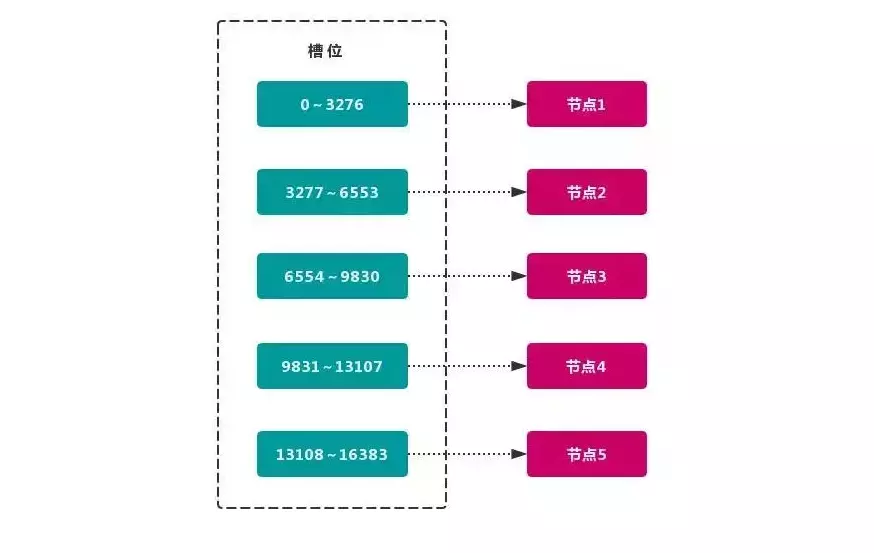
如上图
当前集群有 5 个节点,每个节点平均大约负责 3276 个槽。由于采用高质量的哈希算法,每个槽所映射的数据通常比较均匀,将数据平均划分到 5 个节点进行数据分区。Redis Cluster 就是采用虚拟槽分区。
节点1: 包含 0 到 3276 号哈希槽。
节点2:包含 3277 到 6553 号哈希槽。
节点3:包含 6554 到 9830 号哈希槽。
节点4:包含 9831 到 13107 号哈希槽。
节点5:包含 13108 到 16383 号哈希槽。
所以hash slot的好处是可以像磁盘分区一样自由分配槽位,在配置文件里可以指定,也可以让redis自己选择分配,结果均匀。
这种结构很容易添加或者删除节点。如果增加一个节点 6,就需要从节点 1 ~ 5 获得部分槽分配到节点 6 上。如果想移除节点 1,需要将节点 1 中的槽移到节点 2 ~ 5 上,然后将没有任何槽的节点 1 从集群中移除即可。
由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态.
缓存的key hash结果是和slot绑定的,而不是和服务器节点绑定,所以节点的更替只需要迁移slot即可平滑过渡。
出处链接:
https://www.jianshu.com/p/fe7b7800473e
https://www.jianshu.com/p/90b3de6288c6

 浙公网安备 33010602011771号
浙公网安备 33010602011771号