mysql 可重复读
概念
Repeatable Read(可重复读):即:事务A在读到一条数据之后,此时事务B对该数据进行了修改并提交,那么事务A再读该数据,读到的还是原来的内容。
实现原理(MVCC [ 多版本并发控制 ])
InnoDB在每行记录后面保存两个隐藏的列来,分别保存了这个行的创建时间和行的删除时间。这里存储的并不是实际的时间值,而是系统版本号,当数据被修改时,版本号加1
在读取事务开始时,系统会给当前读事务一个版本号,事务会读取版本号<=当前版本号的数据
此时如果其他写事务修改了这条数据,那么这条数据的版本号就会加1,从而比当前读事务的版本号高,读事务自然而然的就读不到更新后的数据了
现在通过实验,对问题进行下分析:
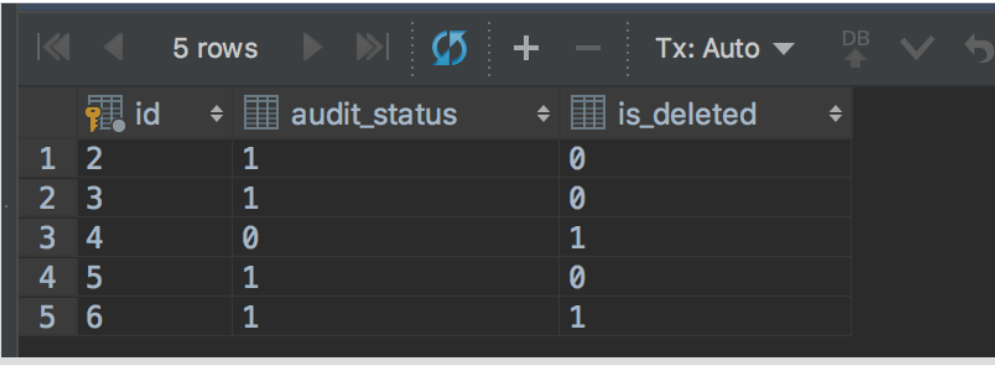
1.在终端A开启事务A,查询一下。
START TRANSACTION; select spt.id,spt.audit_status,spt.is_deleted from stat_point_task spt limit 5;
结果如下:
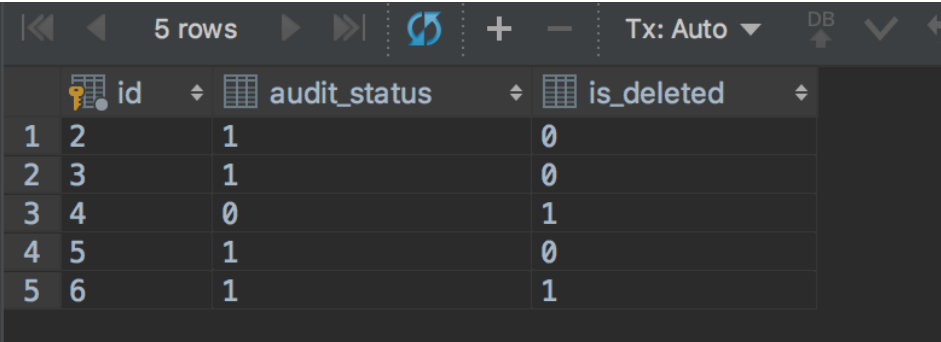
2.在终端B开启事务B,进行同样的查询,可见结果和事务A中的结果是一样的。
START TRANSACTION; select spt.id,spt.audit_status,spt.is_deleted from stat_point_task spt limit 5;
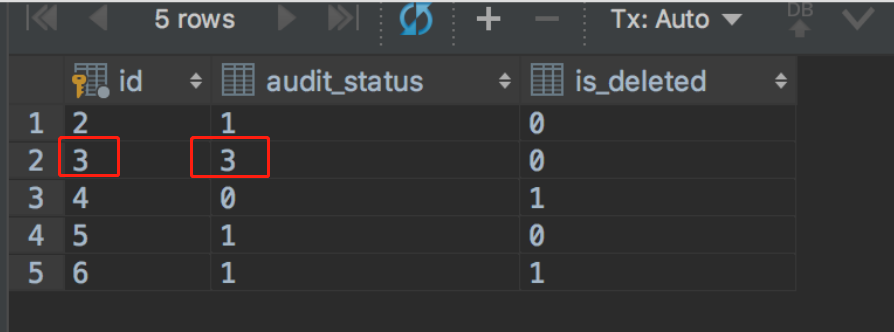
3. 在事务A中,更新一下,将id=3的audit_status更新为3,查询一下,发现更新成功,然后提交事务A;
update stat_point_task set audit_status=3,is_deleted=0 where id=3; select spt.id,spt.audit_status,spt.is_deleted from stat_point_task spt limit 5; commit;
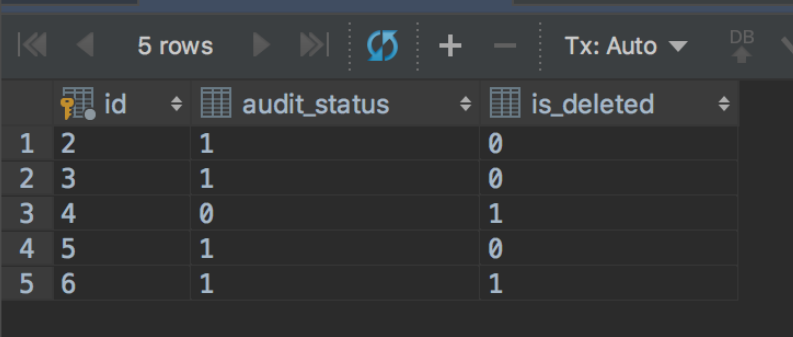
4. 此时,事务A更新了数据,并进行了提交,返回来再看事务B,在事务B中进行查询,发现查询到的还是事务A更新之前的数据。
/*再查询下,因为可重复读,发现查询到的还是事务A更新之前的数据*/ select spt.id,spt.audit_status,spt.is_deleted from stat_point_task spt limit 5;
上面我们对MySQL的默认隔离级别可重复读通过进行实验进行了解释,但是,此时我有一个问题,就是事务B在进行更新的时候,是在事务A更新后的基础上更新,还是A更新前(和B通过查询得到的数据保持一致)的基础上更新,下面通过实验来分析这个问题。
5.在事务B中更新数据,假设A的更新影响到事务B,在事务A的查询结果中id=3的这条数据对应的audit_status为3,在事务B中的这条语句影响的行数应该为0,不会将audit_status设为4。
update stat_point_task set audit_status=4 where id=3 and audit_status=1; select spt.id,spt.audit_status,spt.is_deleted from stat_point_task spt limit 5;
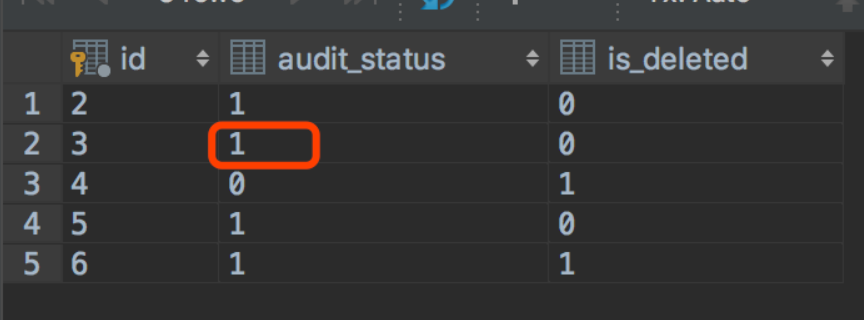
我们通过下面的语句再次验证下 ‘对事务B进行更新时,事务A提交的更新影响到了事务B’ ,此时事务A中提交的更新已经将id=3的audit_status更新为3,虽然因为可重复读,事务B中查询到的id=3的audit_status为1,但是在事务B中进行如下的更新的时候,却更新成功了,成功将audit_status更新为5.
update stat_point_task set audit_status=5 where id=3 and audit_status=3; select spt.id,spt.audit_status,spt.is_deleted from stat_point_task spt limit 5; /*最后记得提交B事务*/ commit;
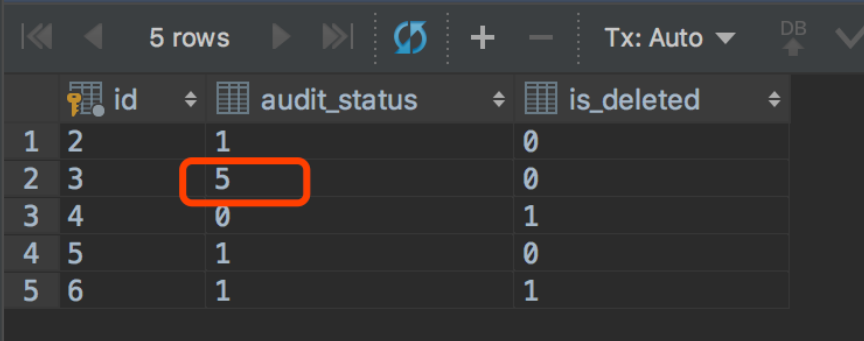
综上:
因为MySQL的可重复读,对事务B进行查询时,事务A提交的更新不会影响到事务B。
但是对事务B进行更新时,事务A提交的更新会影响到事务B。
出处:https://www.cnblogs.com/Allen-win/p/8283102.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号