LinkedHashMap基本原理和用法&使用实现简单缓存(转)
一. 基本用法
LinkedHashMap是HashMap的子类,但是内部还有一个双向链表维护键值对的顺序,每个键值对既位于哈希表中,也位于双向链表中。LinkedHashMap支持两种顺序插入顺序 、 访问顺序
1:插入顺序:先添加的在前面,后添加的在后面。修改操作不影响顺序
2:访问顺序:所谓访问指的是get/put操作,对一个键执行get/put操作后,其对应的键值对会移动到链表末尾,所以最末尾的是最近访问的,最开始的是最久没有被访问的,这就是访问顺序。
LinkedHashMap 继承了HashMap,实现了Map接口
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>
LinkedHashMap一共提供了五个构造方法:
// 构造方法1,构造一个指定初始容量和负载因子的、按照插入顺序的LinkedList public LinkedHashMap(int initialCapacity, float loadFactor) { super(initialCapacity, loadFactor); accessOrder = false; } // 构造方法2,构造一个指定初始容量的LinkedHashMap,取得键值对的顺序是插入顺序 public LinkedHashMap(int initialCapacity) { super(initialCapacity); accessOrder = false; } // 构造方法3,用默认的初始化容量和负载因子创建一个LinkedHashMap,取得键值对的顺序是插入顺序 public LinkedHashMap() { super(); accessOrder = false; } // 构造方法4,通过传入的map创建一个LinkedHashMap,容量为默认容量(16)和(map.zise()/DEFAULT_LOAD_FACTORY)+1的较大者,装载因子为默认值 public LinkedHashMap(Map<? extends K, ? extends V> m) { super(m); accessOrder = false; } // 构造方法5,根据指定容量、装载因子和键值对保持顺序创建一个LinkedHashMap public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) { super(initialCapacity, loadFactor); this.accessOrder = accessOrder; }
从构造方法中可以看出,默认都采用插入顺序来维持取出键值对的次序。所有构造方法都是通过调用父类的构造方法来创建对象的。
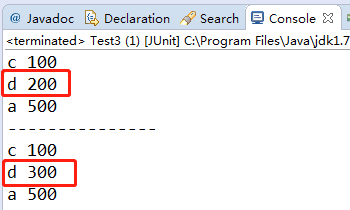
举个例子:键是按照:“c”, “d”,"a"的顺序插入的,修改d不会修改顺序
@Test public void test2(){ Map<String, Integer> seqMap = new LinkedHashMap<>(); seqMap.put("c",100); seqMap.put("d",200); seqMap.put("a",500); for(Entry<String,Integer> entry:seqMap.entrySet()){ System.out.println(entry.getKey()+" "+entry.getValue()); } System.out.println("---------------"); seqMap.put("d",300); for(Entry<String,Integer> entry:seqMap.entrySet()){ System.out.println(entry.getKey()+" "+entry.getValue()); } }
console输出:
按访问顺序:
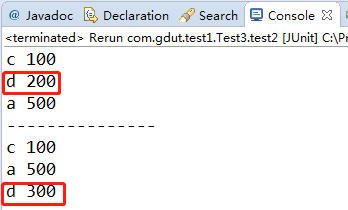
@Test public void test2(){ Map<String, Integer> seqMap = new LinkedHashMap<>(16,0.75f,true); seqMap.put("c",100); seqMap.put("d",200); seqMap.put("a",500); for(Entry<String,Integer> entry:seqMap.entrySet()){ System.out.println(entry.getKey()+" "+entry.getValue()); } System.out.println("---------------"); seqMap.put("d",300); for(Entry<String,Integer> entry:seqMap.entrySet()){ System.out.println(entry.getKey()+" "+entry.getValue()); } }
console输出:
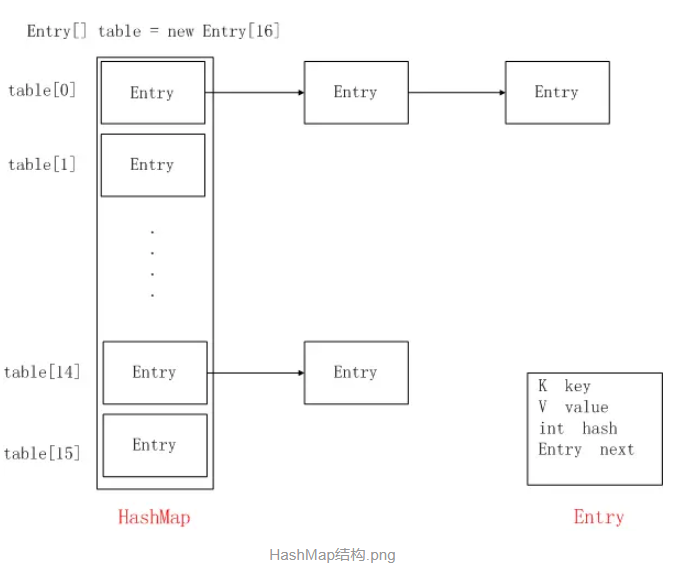
二:HashMap与LinkedHashMap的结构对比
LinkedHashMap其实就是可以看成HashMap的基础上,多了一个双向链表来维持顺序。
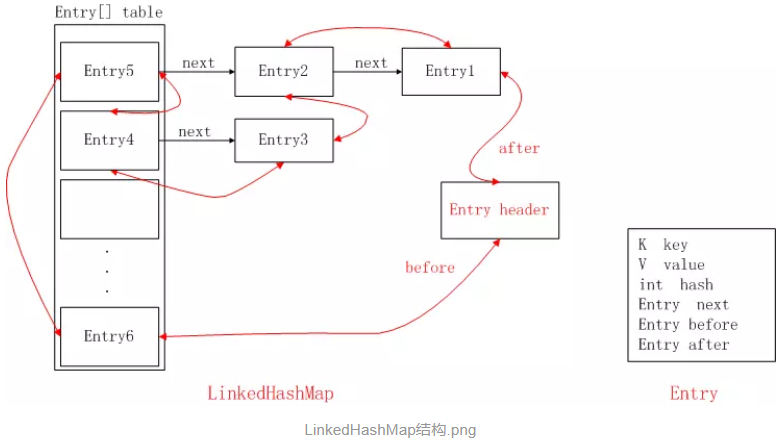
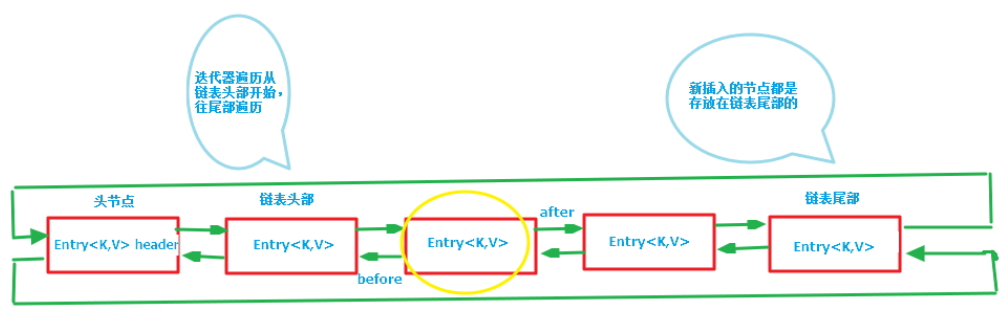
注意该循环双向链表的头部存放的是最久访问的节点或最先插入的节点,尾部为最近访问的或最近插入的节点,迭代器遍历方向是从链表的头部开始到链表尾部结束,在链表尾部有一个空的header节点,该节点不存放key-value内容,为LinkedHashMap类的成员属性,循环双向链表的入口。
三:借用 LinkedHashMap实现最近被使用(LRU)缓存
最近最少使用缓存的回收
为了实现缓存回收,我们需要很容易做到:
- 查询出最近最晚使用的项
- 给最近使用的项做一个标记
链表可以实现这两个操作。检测最近最少使用的项只需要返回链表的尾部。标记一项为最近使用的项只需要从当前位置移除,然后将该项放置到头部。比较困难的事情是怎么快速的在链表中找到该项。
对于使用链表这种方法,put 和 get 都需要遍历链表查找数据是否存在,所以时间复杂度为 O(n)。空间复杂度为 O(1)。
空间换时间
在实际的应用中,当我们要去读取一个数据的时候,会先判断该数据是否存在于缓存器中,如果存在,则返回,如果不存在,则去别的地方查找该数据(例如磁盘),找到后再把该数据存放于缓存器中,再返回。
所以在实际的应用中,put 操作一般伴随着 get 操作,也就是说,get 操作的次数是比较多的,而且命中率也是相对比较高的,进而 put 操作的次数是比较少的,我们我们是可以考虑采用空间换时间的方式来加快我们的 get 的操作的。
例如我们可以用一个额外哈希表(例如HashMap)来存放 key-value,这样的话,我们的 get 操作就可以在 O(1) 的时间内寻找到目标节点,并且把 value 返回了。
然而,大家想一下,用了哈希表之后,get 操作真的能够在 O(1) 时间内完成吗?
用了哈希表之后,虽然我们能够在 O(1) 时间内找到目标元素,可以,我们还需要删除该元素,并且把该元素插入到链表头部啊,删除一个元素,我们是需要定位到这个元素的前驱的,然而定位到这个元素的前驱,是需要 O(n) 时间复杂度的。
最后的结果是,用了哈希表时候,最坏时间复杂度还是 O(1),而空间复杂度也变为了 O(n)。
双向链表+哈希表
我们都已经能够在 O(1) 时间复杂度找到要删除的节点了,之所以还得花 O(n) 时间复杂度才能删除,主要是时间是花在了节点前驱的查找上,为了解决这个问题,其实,我们可以把单链表换成双链表,这样的话,我们就可以很好着解决这个问题了,而且,换成双链表之后,你会发现,它要比单链表的操作简单多了。
所以我们最后的方案是:双链表 + 哈希表,采用这两种数据结构的组合,我们的 get 操作就可以在 O(1) 时间复杂度内完成了。由于 put 操作我们要删除的节点一般是尾部节点,所以我们可以用一个变量 tai 时刻记录尾部节点的位置,这样的话,我们的 put 操作也可以在 O(1) 时间内完成了。
Java已经为我们提供了这种形式的数据结构 LinkedHashMap!它甚至提供可覆盖回收策略的方法(见removeEldestEntry文档)。唯一需要我们注意的事情是,改链表的顺序是插入的顺序,而不是访问的顺序。但是,有一个构造函数提供了一个选项,可以使用访问的顺序
import java.util.LinkedHashMap; import java.util.Map; public LRUCache<K, V> extends LinkedHashMap<K, V> { private int cacheSize; public LRUCache(int cacheSize) { super(16, 0.75, true); this.cacheSize = cacheSize; } //LinkedHashMap有一个removeEldestEntry(Map.Entry eldest)方法,通过覆盖这个方法,加入一定的条件,满足条件返回true。当put进新的值方法返回true时,便移除该map中最老的键和值。 protected boolean removeEldestEntry(Map.Entry<K, V> eldest) { return size() >= cacheSize; } }
注:在LinkedHashMap添加元素后,会调用removeEldestEntry防范,传递的参数时最久没有被访问的键值对,如果方法返回true,这个最久的键值对就会被删除。LinkedHashMap中的实现总返回false,该子类重写后即可实现对容量的控制
自己通过HashMap+双向链表实现LRU缓存算法
import java.util.HashMap; public class LRUCache<K, V> { private int currentCacheSize; // 当前缓存的容量 private int CacheCapcity; // 缓存容量最大值 private HashMap<K,CacheNode> caches; //HashMap private CacheNode first; //链表头 private CacheNode last; //链表尾 public LRUCache(int size) { this.currentCacheSize = 0; this.CacheCapcity = size; caches = new HashMap<K, CacheNode>(size); } public void put(K k,V v){ CacheNode node = caches.get(k); if(node == null) { //缓存中没有该key if(caches.size() >= CacheCapcity) { //缓存容量已经达到最大值了,不能装了 caches.remove(last.key); //删除HashMap中的Node removeLast(); //删除双向链表中的尾结点Node } node = new CacheNode(); node.key = k; } node.value = v; moveToFirst(node); caches.put(k, node); } public Object get(K k){ CacheNode node = caches.get(k); if(node == null) { return null; } moveToFirst(node); return node.value; } public Object remove(K k) { CacheNode node = caches.get(k); if(node != null) { if(node.pre != null){ node.pre.next=node.next; } if(node.next != null){ node.next.pre=node.pre; } if(node == first){ first = node.next; } if(node == last){ last = node.pre; } } return null; } public void clear(){ first = null; last = null; caches.clear(); } private void removeLast(){ if(last != null) { last = last.pre; if(last == null) { first = null; }else { last.next = null; } } } /** * @param node 插入的结点</br> * put数据,将新数据放到链表头部,这样链表头部就是最新的数据,尾部就是最少访问的数据 */ private void moveToFirst(CacheNode node) { if(first == node){ return; } if(node.next != null){ node.next.pre = node.pre; } if(node.pre != null){ node.pre.next = node.next; } if(node == last){ last= last.pre; } if(first == null || last == null){ first = last = node; return; } node.next=first; first.pre = node; first = node; first.pre=null; } @Override public String toString(){ StringBuilder sb = new StringBuilder(); CacheNode node = first; while(node != null){ sb.append(String.format("%s:%s ", node.key,node.value)); node = node.next; } return sb.toString(); } public static void main(String[] args) { LRUCache<Integer,String> lru = new LRUCache<Integer,String>(3); lru.put(1, "a"); // 1:a System.out.println(lru.toString()); lru.put(2, "b"); // 2:b 1:a System.out.println(lru.toString()); lru.put(3, "c"); // 3:c 2:b 1:a System.out.println(lru.toString()); lru.put(4, "d"); // 4:d 3:c 2:b System.out.println(lru.toString()); lru.put(1, "aa"); // 1:aa 4:d 3:c System.out.println(lru.toString()); lru.put(2, "bb"); // 2:bb 1:aa 4:d System.out.println(lru.toString()); lru.put(5, "e"); // 5:e 2:bb 1:aa System.out.println(lru.toString()); lru.get(1); // 1:aa 5:e 2:bb System.out.println(lru.toString()); lru.remove(11); // 1:aa 5:e 2:bb System.out.println(lru.toString()); lru.remove(1); //5:e 2:bb System.out.println(lru.toString()); lru.put(1, "aaa"); //1:aaa 5:e 2:bb System.out.println(lru.toString()); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号