oracle之使用Oracle Developer对SQL进行简单调优(二)
使用Oracle Developer对SQL进行简单调优
Oracle Developer是Oracle提供的免费数据库连接工具,行内数据中心生产操作间默认使用该工具执行SQL,如遇到现场需要对生产SQL进行优化查询的需要熟悉Oracle Developer的基本使用,本文结合Oracle Developer工具展示如何查看SQL,如果进行基本优化。
一、 Oracle Developer 和 Oracle 命令
1. Oracle Developer
SQL解释
Oracle Developer工具里面的“解释”功能只针对当前的sql进行了一个预估的资源消耗以及执行路径,参考数据是系统里存在的表统计信息。结果显示与实际执行可能存在差异,且表的详细信息,在其它功能下显示更为详细。
SQL优化指导
Oracle Developer工具里面的sql优化指导功能,对要优化分析的sql进行了真实的执行,该功能展示的结果,包含了部分解释功能的结果,也就是根据表里面的统计信息预估的执行计划;它一般还包含优化建议;另外还展示了该sql的实际执行计划和并行执行时的sql性能结果。
SQL跟踪
Oracle Developer工具里面的sql跟踪功能,对要优化分析的sql进行了实际的执行,详细的展示了执行过程中对 索引 CPU 缓存IO和块的改变情况,也列出了执行过程中涉及的数据量和资源消耗;此功能包含了sql解释中的表统计信息。
2. Oracle命令
autotrace
Oracle命令 autotrace是分析sql的真实执行计划,查看sql执行效率的一个比较简单又方便的工具。它实际上是对sql实际执行过程信息的一个收集和信息统计。
set autotrace on开启autotrace,后面执行sql语句会自动显示sql执行结果和跟踪信息。
set auto traceonly; 仅显示跟踪信息。
set auto on explain; 仅显示跟踪的explain信息。
set auto on statistics 仅显示跟踪的统计信息。
set autotrace off关闭跟踪。
explain plan for
Oracle命令explain查看执行计划时oracle没有真实执行sql语句。所以生成的执行计划未必是真实的,而且还必须借助plan_table才能看到详细信息,具体使用方式如下:
explain plan for + select * from table where ...
select * from TABLE(DBMS_XPLAN.DISPLAY);
二、 表扫的SQL
1. 解释计划
在查询界面选中一条sql,按F10,或者右键点击解释选项,出现该sql的解释计划:
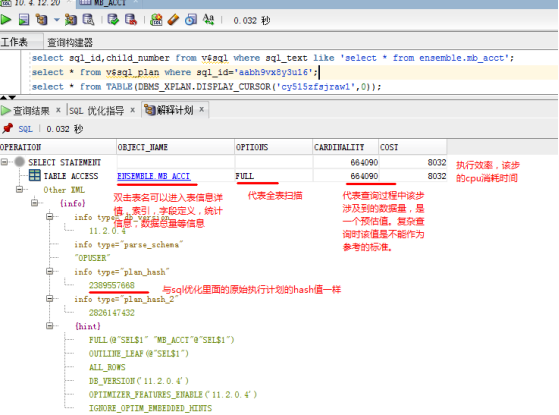
此处显示Oracle估算后给出的解释计划:
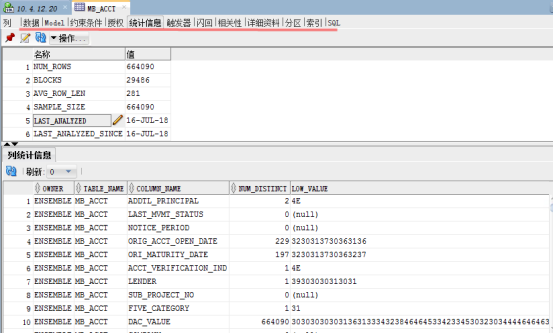
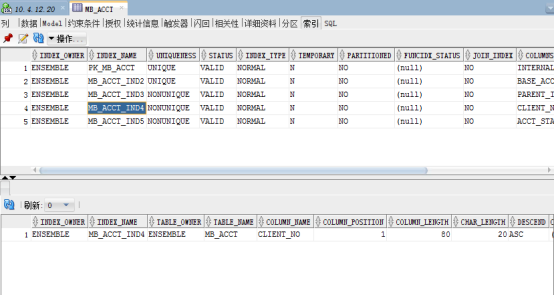
双击表名打开表的详细统计信息,此部分提供了表的数据,约束条件,字段定义类型,索引,分区等详细信息。
注意:预估的解释计划和实际的执行计划可能不相同,预估的解释计划是oracle根据最新的统计信息产生的执行计划,实际sql执行时oracle会根据当时系统的负载情况(可能不是最新的统计信息),涉及的数据量,是否有绑定变量,有没有物理读等信息,通过优化器进行的执行策略选择。所以采用dbms_xplan.display_cursor(sql_id,child_number,format)函数查看实际的sql执行计划;通过查看预估的执行计划确定统计信息的新旧。
2. SQL优化指导
选中sql点击右键,选中优化指导,出现执行计划信息
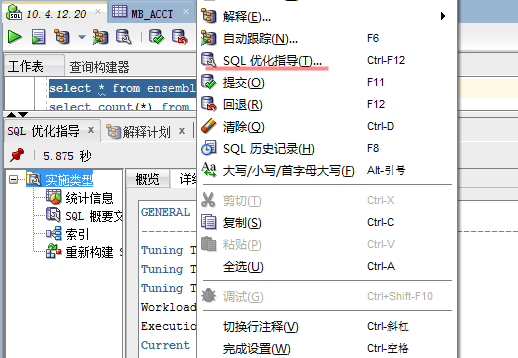
优化指导内容解析,基本信息区域:
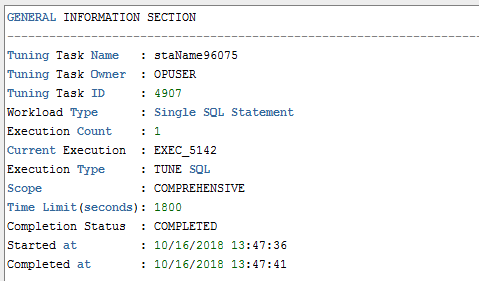
优化建议区域:当Oracle分析执行的SQL后发现有更优的解释计划时会在优化建议区给出提示:
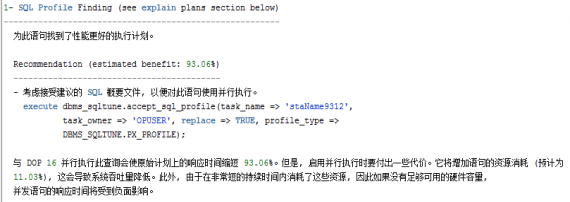

解释计划区域,hash值与解释计划里面的一样,该部分显示包括了解释计划的信息:

推荐的sql优化修改,该信息可以作为参考,本示例种给出的优化方案是开启sql的并行:
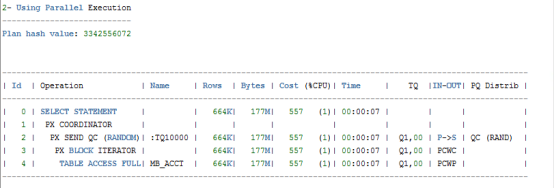
PX COORDINATOR 并行执行协调者,属于并行执行的第一步,负责并行语句的初始化,且将并行操作分解,按照一定策略将分解后的子任务下发给并行服务会话。
PX SEND QC(RANDOM) 并行服务进程通过表队列将数据随机发给协调者
PX BLOCK ITERATOR 并行颗粒度,block iterator把表分割成多个块,每个块由涉及的并行服务进程中的一个去处理。它常和TABLE ACCESS FULL成对出现,意味着全表扫描。
TABLE ACCESS FULL 全表扫描
3. 真实的执行计划
使用autotrace(注意,autotrace traceonly后的sql会被真实执行,如果不想执行请用explain plan for)查询sql实际执行计划与解释计划结果一致:
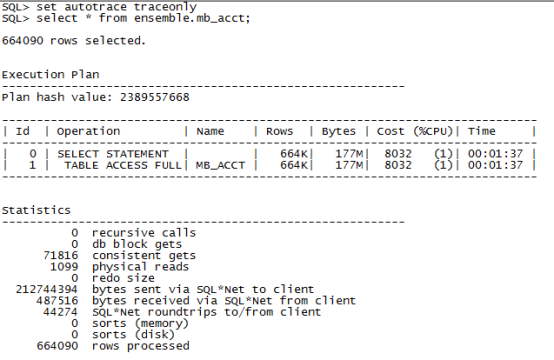
Recursive calls :执行该条语句时,对其他sql语句的调用次数,这种调用包含对该用户下的sql或者是系统的sql。
db block gets:Number of times a CURRENT block was requested. (non consistent gets)非一致性读,当前SQL执行时点获取的块数,从数据缓冲区中读取。
consistent gets:Number of times a consistent read was requested for a block.一致性读,为了保证数据一致性,在数据缓冲区包括回滚段中读取的数据块。
physical reads:物理读,从磁盘上读取的数据块。
逻辑读指的是从数据缓冲区(内存)中读到的数据块,由于从内存读取,因此相对于从磁盘读取要快的多。
逻辑读 = db block gets+ consistent gets
查询命中率需要的数据:select name,value from v$sysstat where name in ('db block gets','consistent gets','physical reads');
命中率=1-(physical reads/(db block gets+ consistent gets))
Redo size:执行DML语句产生的重做日志大小
Sorts(memory,disk)在内存或者磁盘中的排序的数量。
注意:以上信息我们关注的主要是物理读和命中率,物理读过多说明从磁盘获取的数据就多,可能存在全表扫描,使得数据库的性能下降。命中率过低意味1、物理读过多;2、数据缓冲区设置过小,此时需要确认缓冲区合理大小,该值一般在90%以上。
三、 走索引的SQL
1. 解释计划
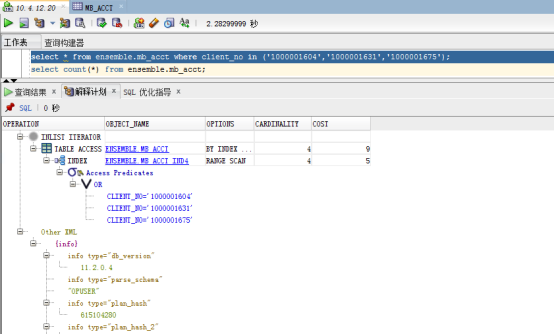
sql解释计划不建议在优化中使用,显示信息量不足。
2. SQL优化指导
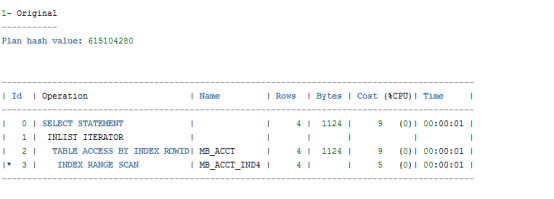
因为此时走索引,实际的执行计划和预估的解释情况一致,所以没有显示执行计划
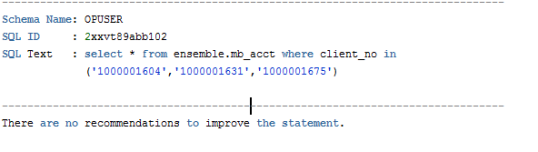
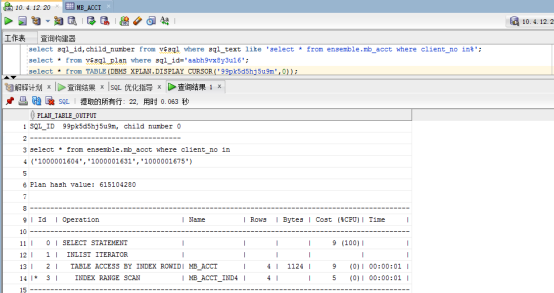
3. 真实的执行计划
使用dbms_xplan.display_cursor(sql_id,child_number,format)函数查询结果与执行结果一致。
四、 核心系统SQL示例
数据库表上没有索引进行如下查询:
select logId, bxid, txid, logIndex, content as contentByte, status from ensemble.dtp_submitlog where bxid='4AF600F207DF4D07BF45AF7008CFF18B' and status='done' order by logIndex;
1. SQL优化指导
Sql优化给出2条建议,第1条建议走索引:
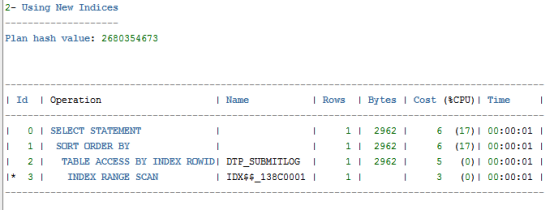
第2条建议开启并行查询:
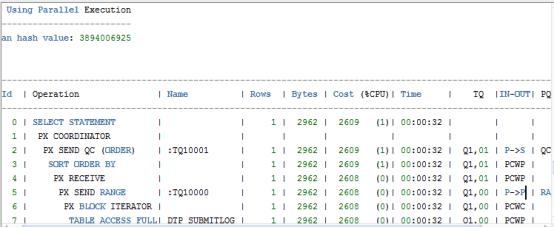
2. 真实的执行计划
使用“自动跟踪”查看真实的执行计划:
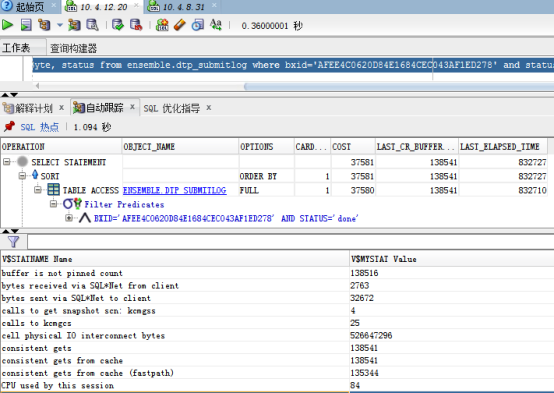
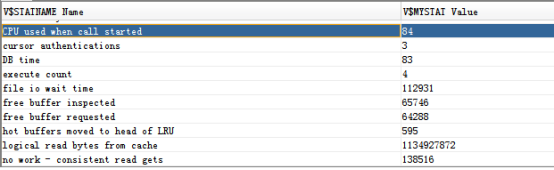
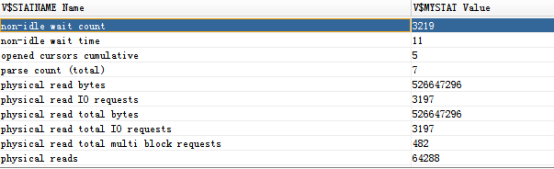
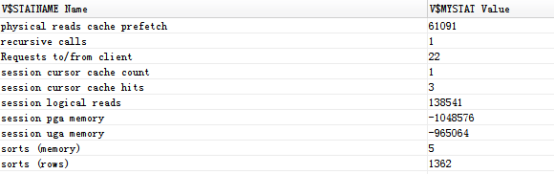
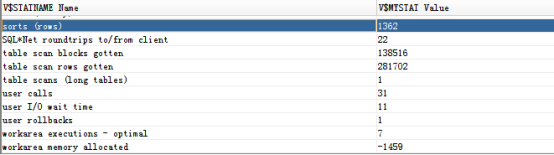
使用dbms.display_cursor也可以查看真实的执行计划:
select sql_id,child_number from v$sql where sql_text like '%from ensemble.dtp_submitlog where bxid=%';
select * from TABLE(DBMS_XPLAN.DISPLAY_CURSOR(sql_id,0));
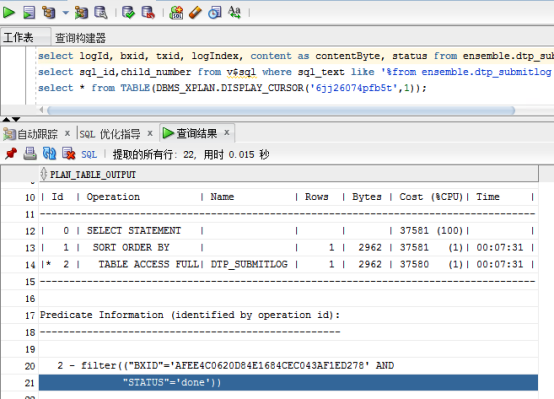
SQL优化给出走索引效率更高,开启并行查询走的也是全表扫描,一般不推荐。
经查询该表上没有适合的索引:
在bxid和status上创建组合索引之后再次执行结果如下:
3. 优化后的执行计划
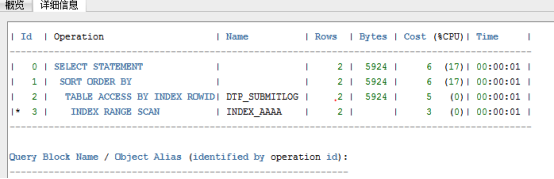
自动跟踪结果如下:
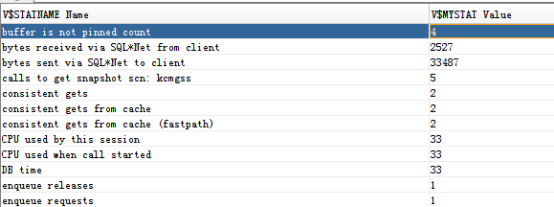
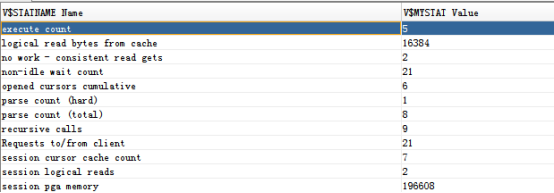
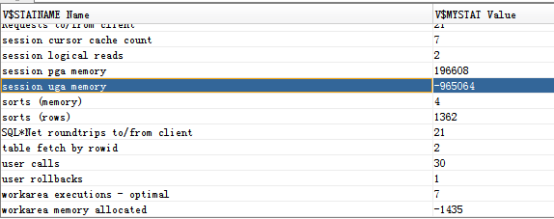
查询结果:
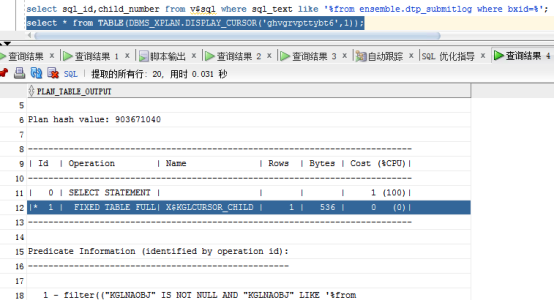
SQL优化该模块已经没有创建索引的优化建议了,执行过程也显示走了索引。
五、 嵌套循环(nested loops)
1. 连接访问次数
大部分表连接走的都是嵌套循环,但如果两个表的结果集比较接近,又没有合适的索引,则可能走哈希索引,本章节以测试表为例,通过hint强制嵌套查询:
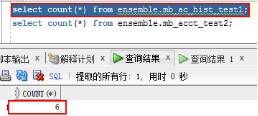
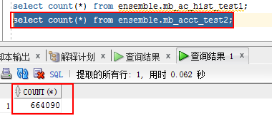
新建测试表mb_ac_hist_test1,mb_acct_test2,数据从mb_acct和mb_tran_hist表中复制,表内数据量如下:
通过hint:/*+leading(a) use_nl(b)*/ 强制指定两个表之间的连接走嵌套循环,为了查看更详细的执行计划,需要通过sqlplus / as sysdba登录,并在SQL前执行statistics_level = all,SQL后执行SELECT * FROM table(dbms_xplan.display_cursor(NULL,NULL,'runstats_last')):
select /*+leading(a) use_nl(b)*/* from ensemble.mb_ac_hist_test1 a,ensemble.mb_acct_test2 b where a.internal_key=b.internal_key;
执行计划如下:
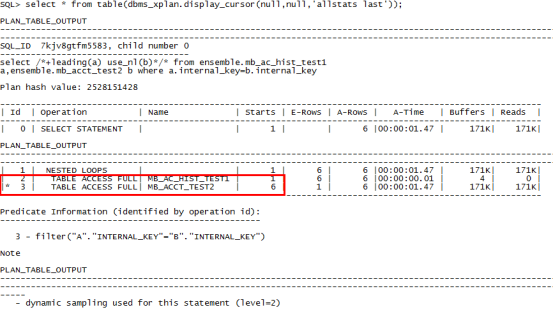
第1行表示连接方式为NESTED LOOPS,第2、3行属于同一缩进,同一缩进下执行操作由上到下,第1个表mb_ac_hist_test1(leading(a))是全表扫描(TABLE ACCESS FULL),是驱动表,第2个表mb_acct_test2(use_nl(b))也是全表扫描(TABLE ACCESS FULL),是被驱动表。
Starts表示表被访问了几次,是主要关注的指标。E-Row表示估算的行数,A-Rows表示实际返回的行数,如果两者差别较大则说明执行计划有问题,需要更新统计值,A-Time表示实际执行时长,Buffers表示逻辑读,Reads表示物理读。
2. 表连接的驱动顺序
驱动表和被驱动表的选择会对SQL效率有很大影响,示例:
select /*+leading(a) use_nl(b)*/* from ensemble.mb_ac_hist_test1 a,ensemble.mb_acct_test2 b where a.internal_key=b.internal_key;
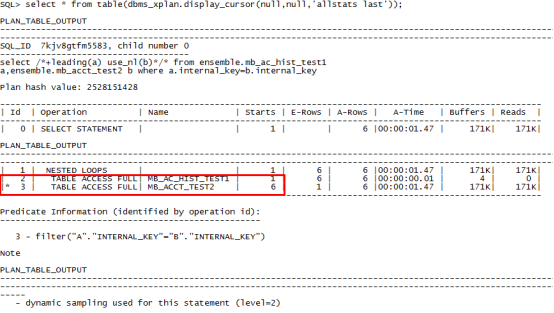
将驱动表和被驱动表进行颠倒:
select /*+leading(b) use_nl(a)*/* from ensemble.mb_ac_hist_test1 a,ensemble.mb_acct_test2 b where a.internal_key=b.internal_key;

小结:驱动表的先后顺序影响sql执行的性能,当mb_acct_test2(66万多数据)表属于驱动表时,访问被驱动表次数就是66万多次,消耗时间3.65s。当mb_ac_test1(6条数据)为驱动表时,时间消耗是0.01s。对比两次访问同一个表的时间相差巨大,因此在优化过程中,使用嵌套循环时,我们应该遵循尽量减少被驱动表的访问次数,结果集小的表做驱动表,结果集大的表做被驱动表,从而提升sql的性能。
3. 嵌套循环的使用场景
l 限制条件字段创建索引
操作步骤:
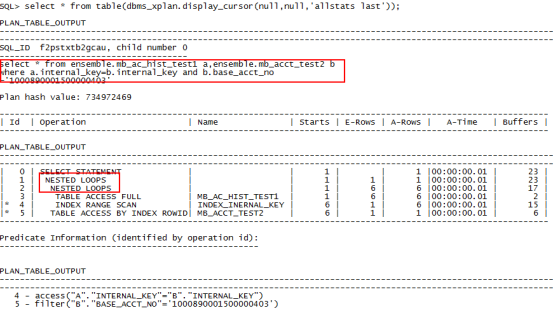
1、select /*+leading(a) use_nl(b)*/* from ensemble.mb_ac_hist_test1 a,ensemble.mb_acct_test2 b where a.internal_key=b.internal_key and b.base_acct_no ='1000890001500000403';
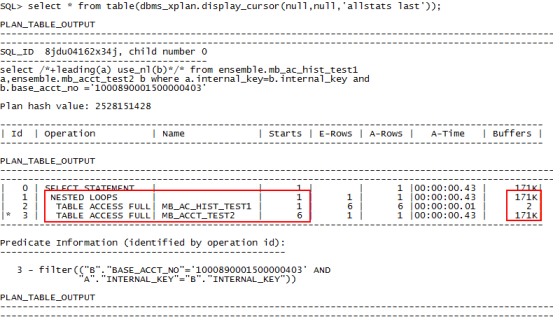
2、create index index_mb_ac_hist_test1 on ensemble.mb_ac_hist_test1(base_acct_no);//在驱动表上创建索引
3、select /*+leading(a) use_nl(b)*/* from ensemble.mb_ac_hist_test1 a,ensemble.mb_acct_test2 b where a.internal_key=b.internal_key and b.base_acct_no ='1000890001500000403';//限制条件在被驱动表上,查询走全表扫描。
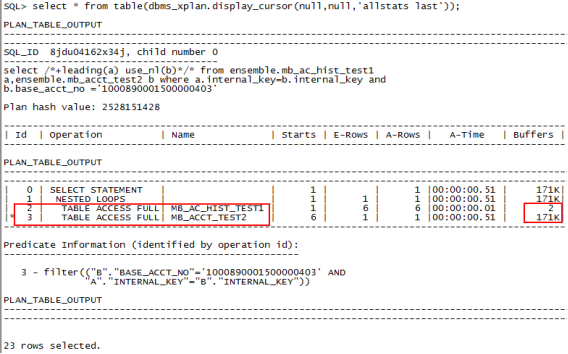
4、select /*+leading(a) use_nl(b)*/* from ensemble.mb_ac_hist_test1 a,ensemble.mb_acct_test2 b where a.internal_key=b.internal_key and a.base_acct_no ='1000890001500000403';//限制条件在驱动表上,查询走索引
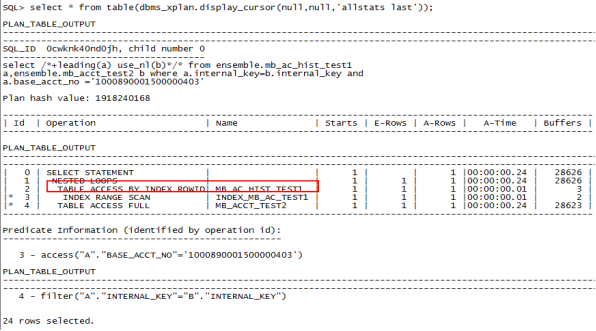
5、create index index_acct_test2 on ensemble.mb_acct_test2(base_acct_no);//在被驱动表上创建索引
6、select /*+leading(a) use_nl(b)*/* from ensemble.mb_ac_hist_test1 a,ensemble.mb_acct_test2 b where a.internal_key=b.internal_key and a.base_acct_no='1000890001500000403';// 限制条件在被驱动表上,查询走全表扫描
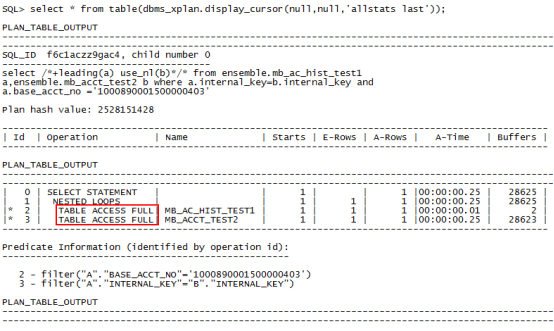
7、select /*+leading(a) use_nl(b)*/* from ensemble.mb_ac_hist_test1 a,ensemble.mb_acct_test2 b where a.internal_key=b.internal_key and b.base_acct_no ='1000890001500000403';//限制条件在被驱动表上,查询走索引

从以上结果来看,索引创建的位置与限制条件所在的表相关,与驱动表和被驱动表无关。在限制条件的表上创建索引之后,性能才有了明显的提升,不管是执行时间还是buffer的使用,资源使用明显降低。
l 连接条件创建索引
嵌套循环驱动表和被驱动表的连接条件上添加索引会有效提高查询效率,但索引建立在驱动表上还是被驱动表上会提高效率,示例如下:
select /*+leading(a) use_nl(b)*/* from ensemble.mb_ac_hist_test1 a,ensemble.mb_acct_test2 b where a.internal_key=b.internal_key and b.base_acct_no ='1000890001500000403';
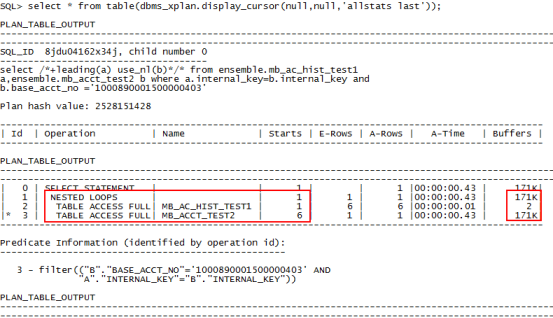
在被驱动表上建立索引:
create index index_inernal_key on ensemble.mb_acct_test2(INTERNAL_KEY);
重新执行sql语句,执行计划如下:
select /*+leading(a) use_nl(b)*/* from ensemble.mb_ac_hist_test1 a,ensemble.mb_acct_test2 b where a.internal_key=b.internal_key and b.base_acct_no ='1000890001500000403';
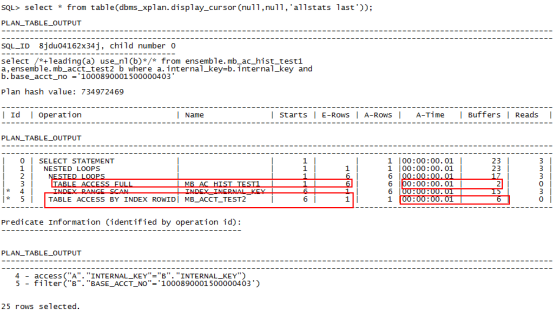
嵌套查询中使用了被驱动表的索引,有效降低了表的访问和扫描。
在驱动表的上建立索引:
create index index_inernal_key on ensemble.mb_ac_hist_test1(INTERNAL_KEY);
select /*+leading(a) use_nl(b)*/* from ensemble.mb_ac_hist_test1 a,ensemble.mb_acct_test2 b where a.internal_key=b.internal_key and b.base_acct_no ='1000890001500000403';
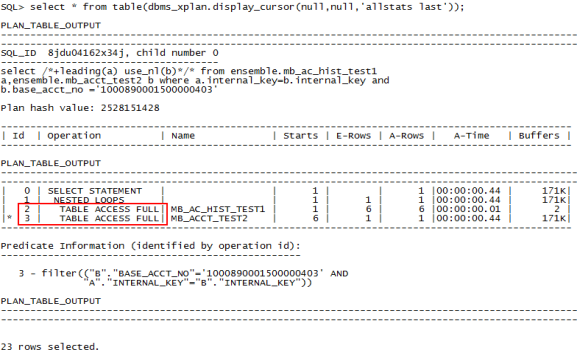
嵌套查询中依然是全表扫描,驱动表上建立的索引没有起到作用。
从建立索引前后的执行结果来看,在被驱动表的连接条件上创建索引之后,性能有明显提升,因为Oracle先从驱动表里获取符合条件的记录,然后根据连接字段,从被驱动表的连接字段上连接查询,显然被驱动表连接字段上有索引会大大提升性能。而驱动表的连接字段上新建索引对性能提升没有明显效果。
增加索引之后不用hint强制选择loop循环,系统依然会选择使用loop循环:
l 左连接
一般左连接在业务sql中也比较常见,在走嵌套循环的情况下和内连接基本一样:
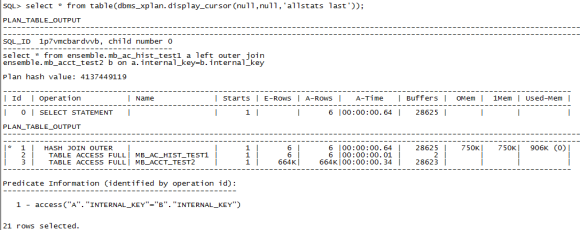
没有索引的时候执行sql:
select * from ensemble.mb_ac_hist_test1 a left outer join ensemble.mb_acct_test2 b on a.internal_key=b.internal_key;
在从表的连接字段上新增索引:
create index index_inernal_key on ensemble.mb_ac_hist_test1(INTERNAL_KEY);
重新执行sql:
select * from ensemble.mb_ac_hist_test1 a left outer join ensemble.mb_acct_test2 b on a.internal_key=b.internal_key;
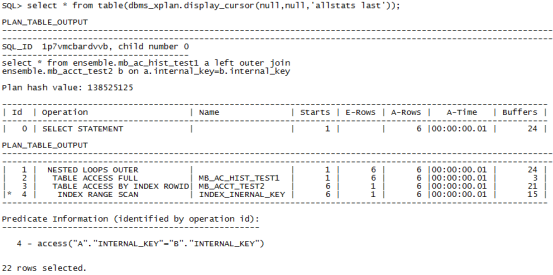
从选择连接方式来看:建立索引前后来看左连接在走全表扫描的情况下选择hash方式连接,建立索引之后选择循环连接。
4. 嵌套循环小结
v 嵌套循环首先关注驱动顺序,驱动表的返回结果集应该尽量少,驱动表的限制条件字段上新建索引会有效提高驱动表的性能,被驱动表在连接字段上新建索引会有效提高被驱动表的性能。
v 嵌套循环对连接条件没有限制,<>、>、<、like都可以处理。不等值查询系统默认走嵌套循环。
六、 总结
如果使用Oracle Developer工具做优化,建议不要使用SQL解释;直接使用SQL自动跟踪、SQL优化和执行dbms语句结合使用。SQL自动跟踪直接体现了实际的执行计划,SQL优化提供了优化建议,dbms的系统存储过程提供了更丰富的查询。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号