线程--守护线程、线程锁、信号量、事件、条件、定时器、队列、池(三)
守护线程

import time
from threading import Thread
def func1():
while True:
print('*'*10)
time.sleep(1)
def func2():
print('in func2')
time.sleep(5)
t = Thread(target=func1,)
t.daemon = True
t.start()
t2 = Thread(target=func2,)
t2.start()
t2.join() #加join后会等待func2结束后在打印
print('主线程')
# 守护进程随着主进程代码的执行结束而结束
# 守护线程会在主线程结束之后等待其他子线程的结束才结束
# 主进程在执行完自己的代码之后不会立即结束 而是等待子进程结束之后 回收子进程的资源
# import time
# from multiprocessing import Process
# def func():
# time.sleep(5)
#
# if __name__ == '__main__':
# Process(target=func).start()
线程锁
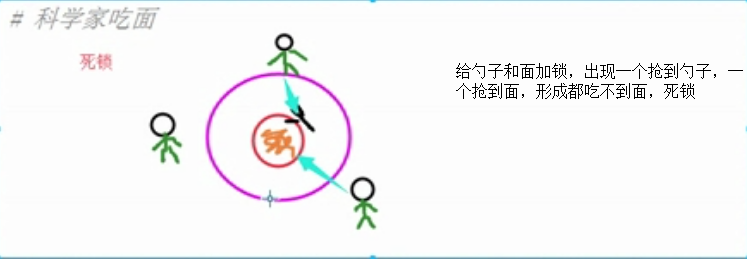
为什么Cpython自带GIL锁还出现死锁,因为是对线程GIL锁,避免不了时间片轮转带来数据不安全
import time
from threading import Lock,Thread
# Lock 互斥锁(只有一个钥匙) 进程 遇到科学吃面用互斥锁例子情况也会出现死锁(只要用到两把以上的锁时会出现死锁)
,也需用递归锁
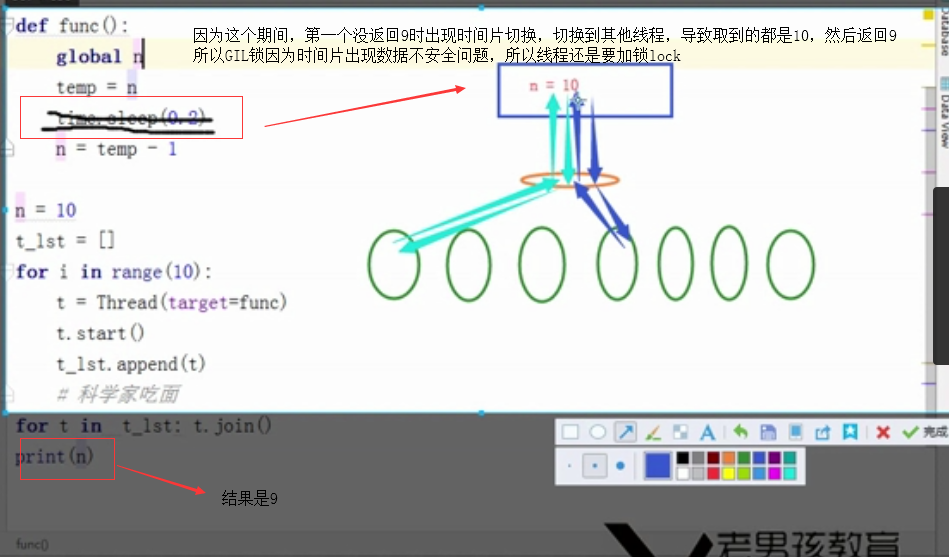
# def func(lock):
# global n
# lock.acquire()
# temp = n
# time.sleep(0.2)
# n = temp - 1
# lock.release()
#
# n = 10
# t_lst = []
# lock = Lock()
# for i in range(10):
# t = Thread(target=func,args=(lock,))
# t.start()
# t_lst.append(t)
# for t in t_lst: t.join()
# print(n)
# 科学家吃面
# noodle_lock = Lock()
# fork_lock = Lock()
# def eat1(name):
# noodle_lock.acquire()
# print('%s拿到面条啦'%name)
# fork_lock.acquire()
# print('%s拿到叉子了'%name)
# print('%s吃面'%name)
# fork_lock.release()
# noodle_lock.release()
#
# def eat2(name):
# fork_lock.acquire()
# print('%s拿到叉子了'%name)
# time.sleep(1)
# noodle_lock.acquire()
# print('%s拿到面条啦'%name)
# print('%s吃面'%name)
# noodle_lock.release()
# fork_lock.release()
#
# Thread(target=eat1,args=('alex',)).start()
# Thread(target=eat2,args=('Egon',)).start()
# Thread(target=eat1,args=('bossjin',)).start()
# Thread(target=eat2,args=('nezha',)).start()
执行上面代码后出现死锁阻塞
![]()
解决死锁问题
![]()
from threading import RLock # 递归锁(一串钥匙,多少根据accquire多少次)
fork_lock = noodle_lock = RLock() # 一个钥匙串上的两把钥匙
def eat1(name):
noodle_lock.acquire() # 一把钥匙
print('%s拿到面条啦'%name)
fork_lock.acquire()
print('%s拿到叉子了'%name)
print('%s吃面'%name)
fork_lock.release()
noodle_lock.release()
def eat2(name):
fork_lock.acquire()
print('%s拿到叉子了'%name)
time.sleep(1)
noodle_lock.acquire()
print('%s拿到面条啦'%name)
print('%s吃面'%name)
noodle_lock.release()
fork_lock.release()
Thread(target=eat1,args=('alex',)).start()
Thread(target=eat2,args=('Egon',)).start()
Thread(target=eat1,args=('bossjin',)).start()
Thread(target=eat2,args=('nezha',)).start()
信号量


import time
from threading import Semaphore,Thread
def func(sem,a,b):
sem.acquire()
time.sleep(1)
print(a+b)
sem.release()
sem = Semaphore(4) 每次打印四个,意思是同一时间只能有4个线程执行
for i in range(10):
t = Thread(target=func,args=(sem,i,i+5))
t.start()
事件
# 事件被创建的时候
# False状态
# wait() 阻塞
# True状态
# wait() 非阻塞
# clear 设置状态为False
# set 设置状态为True
# 数据库 - 文件夹
# 文件夹里有好多excel表格
# 1.能够更方便的对数据进行增删改查
# 2.安全访问的机制
![]()
# 起两个线程
# 第一个线程 : 连接数据库
# 等待一个信号 告诉我我们之间的网络是通的
# 连接数据库
# 第二个线程 : 检测与数据库之间的网络是否连通
# time.sleep(0,2) 2
# 将事件的状态设置为True
import time
import random
from threading import Thread,Event
def connect_db(e):
count = 0
while count < 3:
e.wait(0.5) # 状态为False的时候,我只等待0.5s就结束
if e.is_set() == True:
print('连接数据库')
break
else:
count += 1
print('第%s次连接失败'%count)
else:
raise TimeoutError('数据库连接超时') 自定义的抛异常
def check_web(e):
time.sleep(random.randint(0,3)) #伪代码 模拟连接数据库时间
e.set()
e = Event()
t1 = Thread(target=connect_db,args=(e,))
t2 = Thread(target=check_web,args=(e,))
t1.start()
t2.start()
条件
# 条件
from threading import Condition
# 条件
# 锁
# acquire release
# 一个条件被创建之初 默认有一个False状态
# False状态 会影响wait一直处于等待状态
# notify(int数据类型) 造钥匙, 1、这里使用钥匙不会归还,也就是有几把钥匙就执行几个线程,剩余的线程不会执行
2、如果设置线程数量已经全部执行完毕,再继续造钥匙,已经执行完的线程不再重复执行
3、一次性钥匙
from threading import Thread,Condition
def func(con,i):
con.acquire()
con.wait() # 等钥匙
print('在第%s个循环里'%i)
con.release()
con = Condition()
for i in range(10):
Thread(target=func,args = (con,i)).start()
while True:
num = int(input('>>>'))
con.acquire()
con.notify(num) # 造钥匙
con.release()
定时器
import time
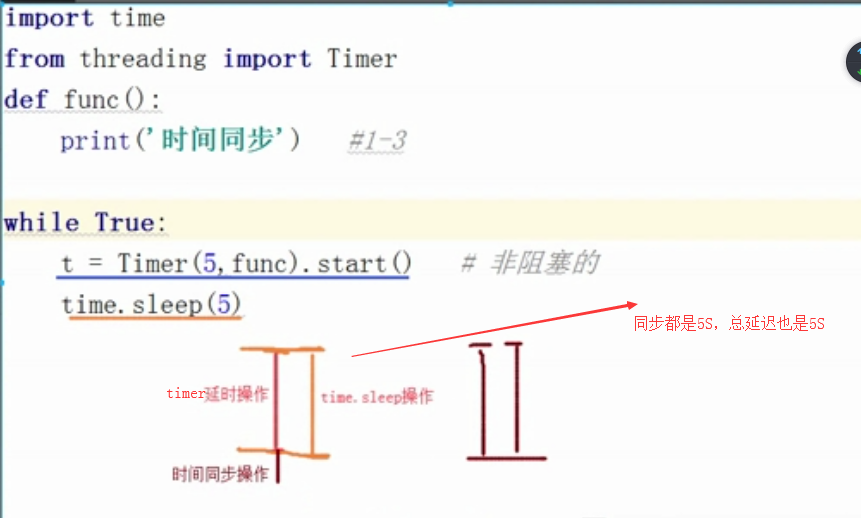
from threading import Timer
def func():
print('时间同步') #1-3
while True:
t = Timer(5,func).start() # 异步非阻塞的,定时开启线程,这里是所以线程睡5S然后同时开启
time.sleep(5) 为了达到每5S执行一个线程,这里设置睡眠5S
![]()
队列
# queue 避免多个线程操作同一数据造成数据不安全,队列其实内部就是封装了很多锁,无需自己再去写加锁代码(数据安全)
import queue
q = queue.Queue() # 队列 先进先出
# q.put() 如果队列有长度,满了还继续放会报错,还会阻塞,直至队列数据有get后
# q.get() 如果队列空了,还继续取会报错,还会阻塞,直至队列有数据
# q.put_nowait() 如果队列有长度,满了还继续放会报错
# q.get_nowait() 如果队列空了,还继续取会报错
这两个就是用来防止q.put()、q.get()阻塞,对于报错进行异常处理就好
# q = queue.LifoQueue() # 栈 先进后出
# q.put(1)
# q.put(2)
# q.put(3)
# print(q.get())
# print(q.get())
q = queue.PriorityQueue() # 优先级队列(自定义),如果优先级一样,那就按值的ASCII码去排
q.put((20,'a'))
q.put((10,'b'))
q.put((30,'c'))
q.put((-5,'d'))
q.put((1,'?'))
print(q.get())
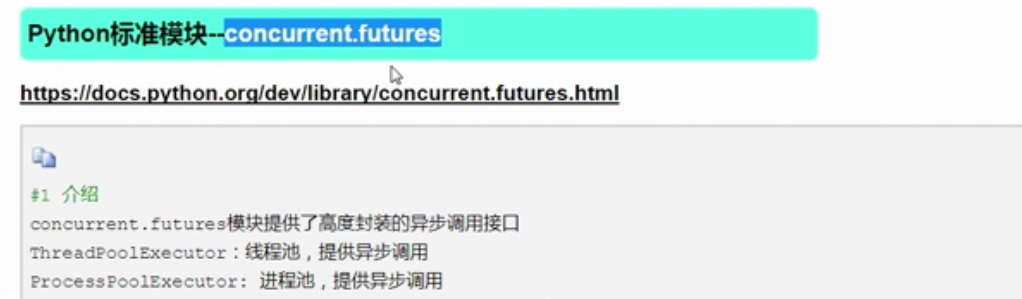
线程池
![]()
![]()
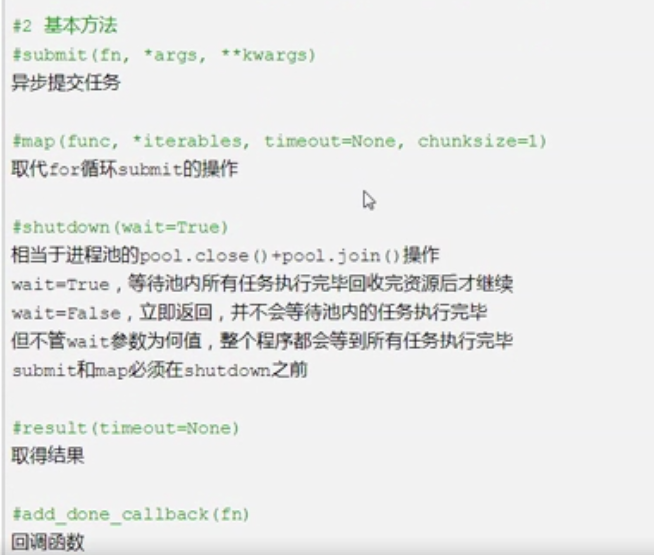
import time
from concurrent.futures import ThreadPoolExecutor #这里如果变成进程池,使用方式demo和线程池一样
def func(n):
time.sleep(2)
print(n)
return n*n
def call_back(m):
print('结果是 %s'%m.result())
# add_done_callback
tpool = ThreadPoolExecutor(max_workers=5) # 默认 不要超过cpu核数*5
for i in range(20):
tpool.submit(func,i).add_done_callback(call_back)
#有爬虫例子使用回调函数的在学习教材中
# 方法一(无返回值)
# tpool.map(func,range(20)) # 拿不到返回值
# 方法二(有返回值)
# t_lst = []
# for i in range(20):
# t = tpool.submit(func,i)异步提交任务
# t_lst.append(t)
# tpool.shutdown() # close+join #这里注释话,就会执行完哪个就打印哪个
# print('主线程')
# for t in t_lst:print('***',t.result()) # 异步取结果(返回值)
#子线程打印的print(n) 不一定按顺序执行的,按照线程的各自的执行情况(时间片轮转情况)
# print('***',t.result())异步获取结果是一定按顺序打印的,因为for i in range(20);t = tpool.submit(func,i) t_lst.append(t)是按i:0-20顺序插入列表的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号