线程以及线程模块中的其他方法(一)
![]()

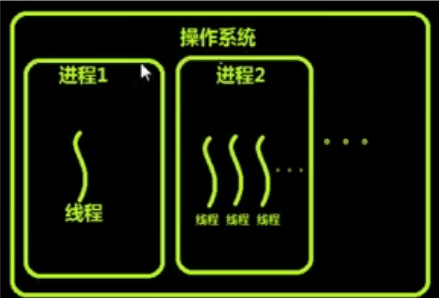
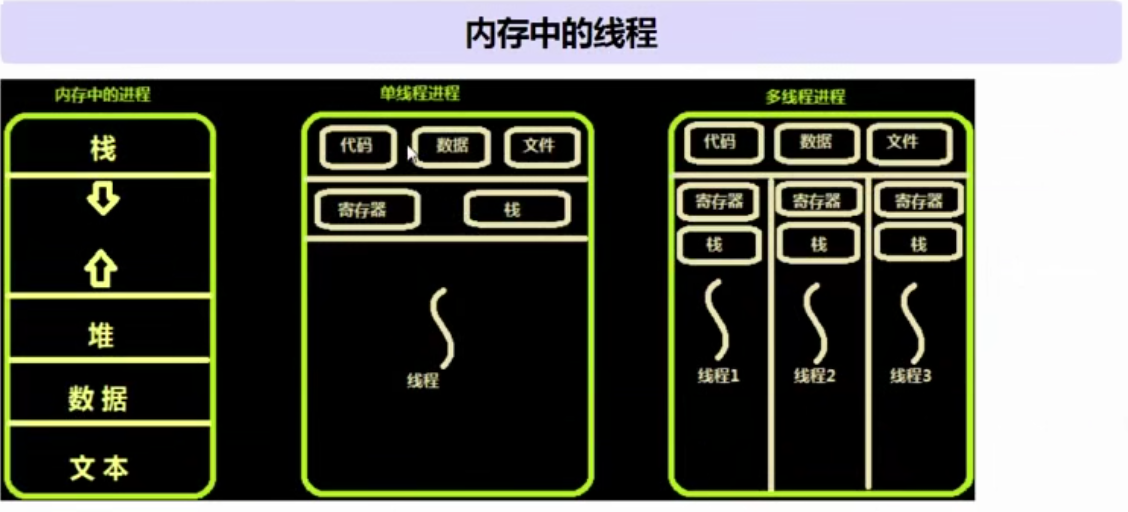
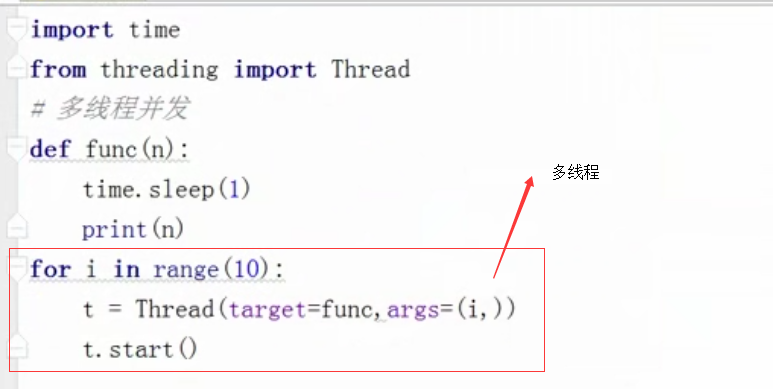
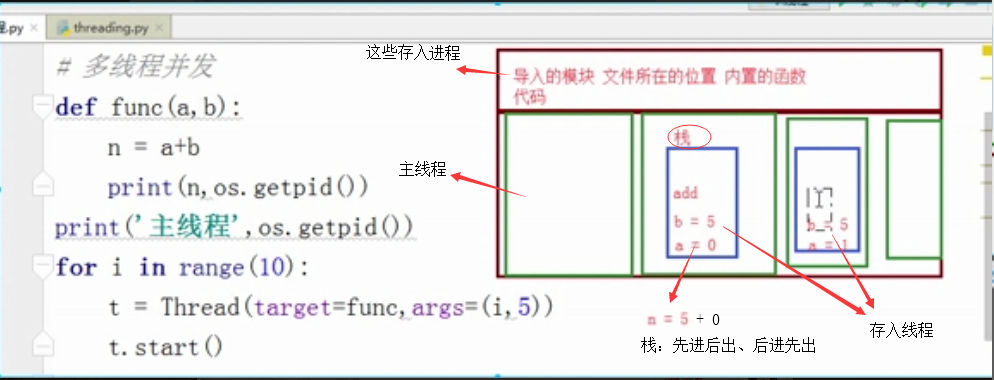
线程就栈寄存那些东西,占用内存小
内存数据的共享问题
import os
import time
from threading import Thread
# 多线程并发
# def func(a,b):
# global g
# g = 0
# print(g,os.getpid())
#
# g = 100
# t_lst = []
# for i in range(10):
# t = Thread(target=func,args=(i,5))
# t.start()
# t_lst.append(t)
# for t in t_lst : t.join()
# print(g)
![]()
# class MyTread(Thread):
# def __init__(self,arg): #重写_init_方法
# super().__init__()
# self.arg = arg
# def run(self): #必须定义run
# time.sleep(1)
# print(self.arg)
#
# t = MyTread(10)
# t.start()
# 进程 是 最小的 内存分配单位
# 线程 是 操作系统调度的最小单位
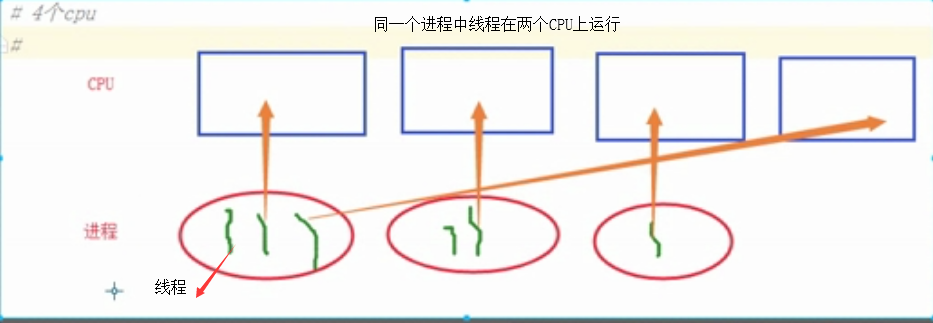
# 线程直接被CPU执行,进程内至少含有一个线程,也可以开启多个线程
# 开启一个线程所需要的时间要远远小于开启一个进程
# 多个线程内部有自己的数据栈,数据不共享
# 全局变量在多个线程之间是共享的
![]()
![]()
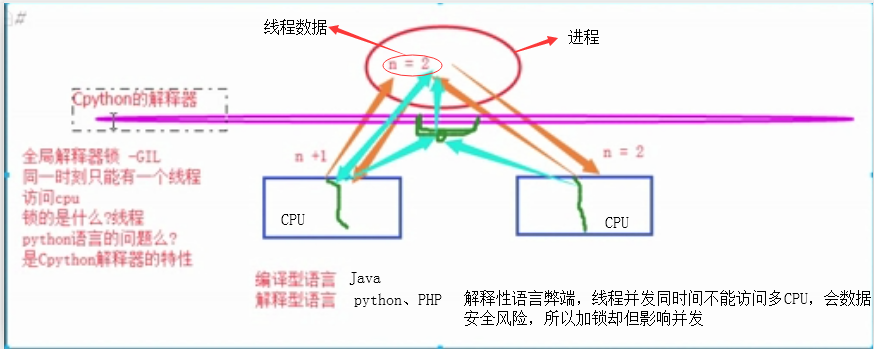
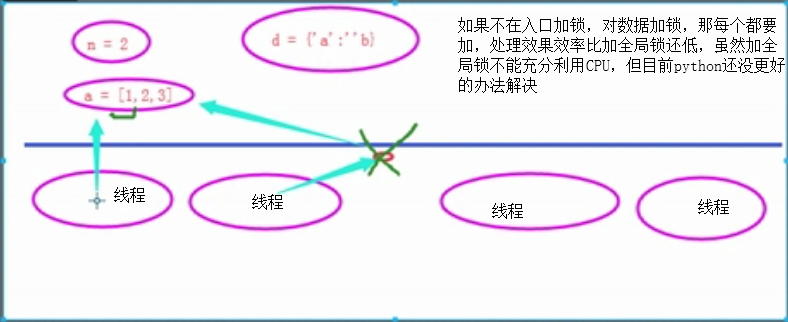
上图中间横杆是访问线程数据入口加全局锁
![]()
![]()
# GIL锁(即全局解释器锁)
# 在Cpython解释器下的python程序 在同一时刻 多个线程中只能有一个线程被CPU执行
# 高CPU : 计算类 --- 高CPU利用率 (建议用多进程,不用用多线程)
# 高IO : 爬取网页 200个网页(多线程)
# qq聊天 send recv
# 处理日志文件 读文件
# 处理web请求
# 读数据库 写数据库
import time
from threading import Thread
from multiprocessing import Process
def func(n):
n + 1
if __name__ == '__main__':
start = time.time()
t_lst = []
for i in range(100):
t = Thread(target=func,args=(i,)) # 多线程
t.start()
t_lst.append(t)
for t in t_lst:t.join()
t1 = time.time() - start
start = time.time()
t_lst = []
for i in range(100):
t = Process(target=func, args=(i,)) # 多进程(进程之间切换消耗时间较长,对于高IO的并发建议用多线程)
t.start()
t_lst.append(t)
for t in t_lst: t.join()
t2 = time.time() - start
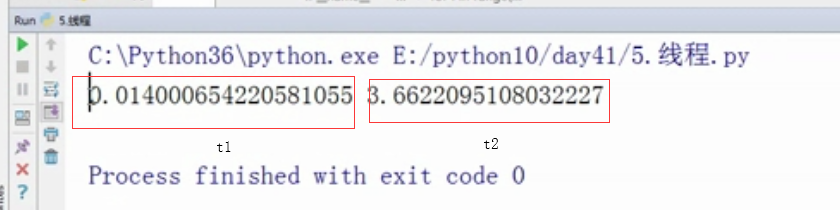
print(t1,t2)
![]()
线程模块中的其他方法

import time
import threading
def wahaha(n):
time.sleep(0.5)
print(n,threading.current_thread(),threading.get_ident()) #线程名和ID
for i in range(10): # 10个子线程
threading.Thread(target=wahaha,args=(i,)).start()
print(threading.active_count()) # 打印结果是11 , 10个子线程+1个主线程 (查看当前线程数)
print(threading.current_thread()) #主线程 1个
print(threading.enumerate()) # 显示11个线程,以列表打印

 浙公网安备 33010602011771号
浙公网安备 33010602011771号