python学习笔记
在线python:https://c.runoob.com/compile/9
版本类型:python3
文字部分加入了自己的理解(#^.^#)
a = 6 print(a) b = '多么美妙的世界' print(b) a=b print(a,b)

name = input('你叫什么名字') print('我将称呼你:' + name)


a = 1 b = 2 print(a + b) print(b * 3) print(b + a * 2)

/是精确除 //取整除(对结果直接去掉小数部分)
print(3 / 2) print(3 // 2) print(3. // 2.)

a = '我爱' b = '中国' print(a + b) print(a*3 + b)

a = '中国' a_len = len(a) b = 'a的长度是' print(b + str(a_len))

a = '10' b = 10 c = str(len(a) + b) a = len(a * b) b = a + b
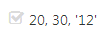
def main(): print('世界,你好') if __name__ == '__main__': main()

相同的行缩进在同一层次,def是定义函数关键字,错误缩进会被告知语法错误syntax error,不用\t制表位而用四空格
def max_pow(a, b): if a > b: pow_ab = a ** b return pow_ab pow_ba = b ** a return pow_ba
def yinhe(a): print('='+a+'=') def main(): print('牛郎') yinhe('||') print('织女') if __name__ == '__main__': main()

java使用驼峰命名,而python使用下划线命名法
def do_qingan(my_line): print('跪') print('拜' * 3) print(my_line) def main(): my_line = '万岁' do_qingan(my_line) if __name__ == '__main__': main()

import sys help(len) print(dir(sys)) help(sys.exit) help('中国'.split) print(dir(list))
python注释
单行 # This is the first line # of the comment. Here is the second line. # And here is the third one 多行 ''' 不希望被执行的代码块 '''
多行读入
a,b,c=(int(x) for x in input().split(' ')) ans=a+b+c print(ans)
一个字符串可以多行写,每行后面加斜杠
str[]从0开始
a = '这个字符串很友好\ 因为它总是每行不会很长 \ 你看起来一点都不会觉得累'
加上r后转义字符失效,r全拼row
a = '我是\n tom' b = r'我是\nTom' print(a) print(b) print(a.lower()) print(b.upper())

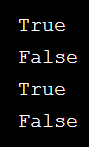
s = 'HelloabcdWord' print(s.isalpha()) print(s.isdigit()) print(s.startswith('Hello')) print(s.endswith('World'))
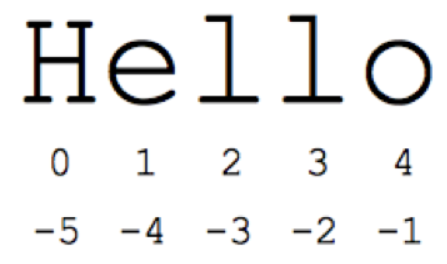
a[0]=a[-5]
1开始的4个
3开始
到-2结束(去掉后面2个)
tower = '金木水火土风雨' print(tower[1:4]) print(tower[3:]) print(tower[:-2])

else可有可无
空字符串''为假
'a' in list 也可以得到真假
and or not
if a > 0: c = a elif a == 0: c = -1 else: c = -a
weather = '下雨天' bag = '包里空空的' if weather.find('雨')!=-1: bag=bag.replace('空空的','有雨伞') print(bag)
![]()
{}里如果无数字则按顺序给
%g是浮点数
name = '王母娘娘' age = 9000 height = 1.73 print(name + '是一位' + str(age) + '岁的老奶奶,她身高' + str(height) + '米') print('{0}是一位{1}岁的老奶奶,她身高{2}米'.format(name,age,height)) print('%s是一位%d岁的老奶奶,她身高%g米' %(name,age,height))

python可以直接写if 2<a<13:
list=[100,23,45] print(list[0]) print(list[1]) print(list[2]) print(len(list))
![]()
hello = ['hi', 'hello'] world = ['earth', 'field', 'universe'] hello.append('你好') print(hello) hello.extend(world) print(hello)
![]()
index找到第一个hi的位置
hello = ['hi', 'hello'] hello.insert(0,'你好') print(hello) print(hello.index('hi'))
![]()
hello = ['你好', 'hi', 'hello'] hello.remove('你好') print(hello) hello.pop(0) print(hello)
![]()
manager = '托塔天王,太白金星,卷帘大将' manager_list = manager.split(',') print(manager_list) new_manager = ' '.join(manager_list) print(new_manager)
![]()

gardens = [7204, 3640, 1200, 1240, 71800, 3200, 604] total = 0 for num in gardens: total+=num print(total) print(sum(gardens))
![]()
0到99每个数,100个数
1到9每个数
1,3,5,7,9
10,8,6,4,2
for num in range(100): range(1,10) range(1,10,2) rang(10,1,-2)
first = 0 second = 1 # 请在下一行写代码 while first<100: print(first) first, second = second, first + second print('一切都完成啦')
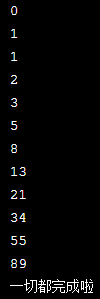
x=numbers.sort() 会sort,x为None
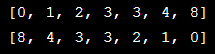
numbers = [1, 4, 2, 3, 8, 3, 0] numbers.sort() print(numbers)
![]()
numbers = [1, 4, 2, 3, 8, 3, 0] print(sorted(numbers)) print(sorted(numbers,reverse=True))
lexicographical order字典序
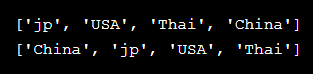
如果长度一样,则按照本来的顺序输出
def china_first(item): if item == 'China': return 0 else: return len(item) country = ['jp', 'China', 'USA', 'Thai'] print(sorted(country,key=len)) print(sorted(country,key=china_first))


元组(tuple)是一个固定大小的一组元素
创建元组,值用逗号分隔并放在圆括号内,空元组是简单括号,[ ]、len()、for...in可以使用与元组
一个元素的元组 tuple=('hi',),需要加逗号
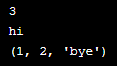
tuple = (1, 2, 'hi') print(len(tuple)) print(tuple[2]) tuple=(1,2,'bye') print(tuple)
def plus_one(tuple): return tuple[0] + 1, tuple[1] + 1, tuple[2] + 1 t = (1, 4, -1) (x,y,z)=plus_one(t) print(x) print(y,z)

键值对 key-value-pair
键名:键值,称作字典
dict = {'key1': 100, 'key2': 112, ... }
#定义
print(dict['key1'])
#执行
dict['key1'] = 999
#修改
常见键名:字符串、数值、元组
键值:可以是任何类型的数值
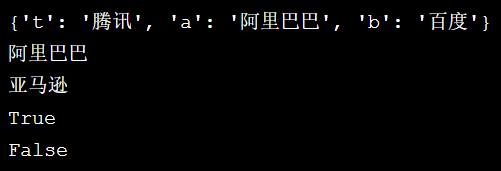
bat = {} bat['b'] = '百度' bat['a'] = '阿里巴巴' bat['t'] = '腾讯' print(bat) print(bat['a']) bat['a']='亚马逊' print(bat['a']) print('b' in bat) print('x' in bat)
bat = {'a': '阿里巴巴', 'b': '百度', 't': '腾讯'}
print(bat.keys())
print(bat.values())
print(bat.items())
print(list(bat.keys()))
print(list(bat.values()))
print(list(bat.items()))

bat = {'a': '阿里巴巴', 'b': '百度', 't': '腾讯'}
for value in bat.values():
print(value)
for key in bat:
print(key)
for k,v in bat.items():
print(k,'>',v)

↑随机输出
boss = {} boss['name'] = 'robin' boss['age'] = 45 boss['height'] = 1.78 print('The boss named %(name)s is %(age)d-year-old and %(height)g tall.'%boss)
![]()
num = 6 list = ['a', 'b', 'c', 'd'] dict = {'a': 1, 'b': 2, 'c': 3} del list[0] del list[-2:] print(list) del dict['b'] print(dict) del num print(num)

↑print(dict)是随机顺序
a.item是键值+键名
d.%(lily)d
e. int和str不能连接
文件操作符file descriptor
文件名filename
fd = open('filename', 'r') fd = open('filename', 'rw')
关闭fd.close()
r读取,w写入,a向后添加
读入文件每一行(仅对文件读取有效,对二进制读取并不能用)
按行读取,不会受内存限制
# 按行输出整个文件 f = open('filename', 'rU') for line in f: # 访问文件每一行 print(line, end = ' ') # 打印每一行,end = ' '可以确保不添加换行
fd.readline()
fd.read()
fd.write(字符串)
python中有一些已经写好的功能性的"包",称为模组module
codecs模组提供了读取一个非英文的文件所需要的unicode读取支持
import引入,打开文件时标记所需要使用的编码字符集,只可以用fd.write()写出
import codecs fd = codecs.open('foo.txt', 'rU', 'utf-8')
n=int(input()) l=list(map(int, input().split())) target=int(input()) for i in range(n): for j in range(i+1,n): if l[i]+l[j]==target: print(i+1,j+1)
s=input() list=[0,0,0,0] for i in range(len(s)): if s[i].isalpha(): list[0]+=1 elif s[i].isdigit(): list[1]+=1 elif s[i]==' ': list[2]+=1 else: list[3]+=1 print(list[0],list[1],list[2],list[3])
正则表达式regular expression
用于匹配文本形式的强大逻辑表达式,re模组提供。
由普通字符和元字符组成,普通字符包括大小写的字母和数字,元字符有特殊含义
不会被作为普通字符来处理的元字符:
.^$*+?{[]\|()
.会匹配除了换行以外的任何字符 \w等价于[a-zA-Z0-9_]会匹配单一字母、数字或下划线 \W会匹配任何非字母、数字和下划线的单一字符 \b会匹配“单一字母、数字或下划线字符”和“任何非字母、数字和下划线的单一字符”之间的边界 \s等价于[\n\r\t\f],会匹配一个空白字符(包括空格、换行、返回、制表符、表格) \S则匹配所有非空白字符 \t\n\r依次用于匹配制表符、换行符、返回符 \d等价于[0-9]用于匹配十进制表示的数字 ^作为开始标记,$作为结束标记,分别用于标记一个字符串开始和结束的位置 \用于字符转义,比如\.表示对一个真实点字符的匹配,\\表示对一个真实反斜杠字符的匹配 如果不确定是否需要转义,可以都加斜杠
import re str = 'A cute word:cat!!' match=re.search(r'word:\w\w\w',str) if match: print('found',match.group())
r表示不需要被转移处理
![]()
import re print(re.search(r'..g','piiig').group()) print(re.search(r'\d\d\d','p123g').group()) print(re.search(r'\w\w\w','@@abcd!!').group())
![]()
import re print(re.search(r'pi+','piig').group()) print(re.search(r'pi*','pg').group())
![]()
python 一切皆对象:数字、字符串、元组、列表、字典、函数、方法、类、模块
一个类会有一系列属性和一系列方法,属性可以看做类内定义的一个或者几个变量,方法相当于类内定义的一系列函数(比如列表的append函数)
类的定义
class Journalist: """ Take this as an example """ def __init__(self,name): self.name=name def get_name(self): return self.name def speed(self,speed): d={} d[self.name]=speed return d
函数
def max_pow(a, b): if a > b: pow_ab = a ** b return pow_ab pow_ba = b ** a return pow_ba
a**b为a的b次方
python对命名的要求:
变量:变量名全都小写,由下划线连接各个单词,如color、the_elder等,不能与python的保留字冲突
文件名:小写,可使用下划线
函数名:小写,可以使用下划线,也可以使用首字母大写的方式,比如myFunc,除了第一个单词首字母小写之外,剩下的单词首字母大写
函数参数:同变量
函数可以嵌套,只要定义了就可以调用,跟位置无关(这里好像跟全国二级考的python不一样...),函数可以一次返回多个值,但是只能return一次
def fun2: fun1() def fun1: pass
def fun1: fun1()
def func(): """ func() help """ pass
给函数写文档,说明函数用途
在交互式命令行中,我们可以直接使用func.__doc__查看函数的文档
可以给函数定义额外属性
func.attr = 10 print(func.attr) # 输出 10
内置函数dir,可以查看对象有哪些属性和方法
无法判断函数有多少个参数:*args
def app(ls,*args): for item in args: ls.append(item) def swap(a,b): temp=a a=b b=temp ls = [] app(ls, 1, 2) print(ls) ls2 = [] app(ls2, 1, 2, 3) print(ls2) a=1 b=2 swap(a,b) print(a,b)
ls作为列表,是可变参数
c++/c,没有垃圾回收机制,由程序员自己管理内存
交换a,b
a, b = b, a

# 在这里输入代码 def fac(n): if n==0: return 1 else: return n*fac(n-1) print('Enter a positive integer:') n = int(input()) y = fac(n) print(y)
头递归
def factorial(int n): if n == 1: return 1 else: return factorial(n - 1) * n
尾递归
def factorial(n,product): if n == 0: return product product = product * n return factorial(n - 1, product)
用空格分开
lst = ['j','i','s','u','a','n'] for i in lst: print(i, end = ' ')
迭代器的遍历
lst_iter = iter(lst) print(lst_iter.__next__()) # 输出 j print(lst_iter.__next__()) # 输出 i ...
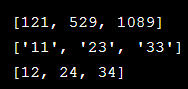
def func_seq(func,ls): return [func(i) for i in ls] def sqrt(num): return num**2 def to_str(num): return str(num) def plus(num): return num+1 ls = [11, 23, 33] print(func_seq(sqrt,ls)) print(func_seq(to_str,ls)) print(func_seq(plus,ls))
特殊函数:lamba,map,reduce
lamba不能超过一个表达式
lambda arg1, args, ... argN: expressions_with_args #定义
sqrt= lambda x : x ** 2 print(sqrt(2)) func = lambda x, y : x + y # 返回 x + y 的值
map,函数+可迭代对象,可以多参迭代
map(function, iterable, ...)
ls = [11,22,33] plus = lambda x : x + 1 print(map(plus, ls)) # <map object at 0x000001BF7F46C6A0> >>> list(map(plus, ls01)) [2, 2, 3, 4]
>>> def abc(a, b, c): ... return a * 10000 + b * 100 + c ... >>> list1 = [11, 22, 33] >>> list2 = [44, 55, 66] >>> list3 = [77, 88, 99] >>> list(map(abc, list1, list2, list3)) [114477, 225588, 336699]
function可以是None
>>> list1 = [11, 22, 33] >>> list2 = [44, 55, 66] >>> list3 = [77, 88, 99] >>> list(map(None, list1, list2, list3)) [(11, 44, 77), (22, 55, 88), (33, 66, 99)]
reduce函数,有两个参数,函数f和list,f中必须有两个参数
reduce()对list中的每个元素反复调用函数f,并返回最终结果值
def f(a, b): return a + b

def hanoi(n,begin,tmp,end): if n==1: prt(begin,end) else: hanoi(n-1,begin,end,tmp) prt(begin,end) hanoi(n-1,tmp,begin,end) def prt(begin,end): print(begin+'-->'+end) n=int(input()) hanoi(n,'A','B','C')
汉诺塔
还差正则表达式和类的部分,有错请指出(*^▽^*)
...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号