
67
背景介绍
1. 什么是爬虫
爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来。想抓取什么?这个由你来控制它咯。 比如它在抓取一个网页,在这个网中他发现了一条道路,其实就是指向网页的超链接,那么它就可以爬到另一张网上来获取数据。这样,整个连在一起的大网对这之蜘蛛来说触手可及,分分钟爬下来不是事儿。
2. 浏览网页的过程
在用户浏览网页的过程中,我们可能会看到许多好看的图片,比如 http://image.baidu.com/ ,我们会看到几张的图片以及百度搜索框,这个过程其实就是用户输入网址之后,经过 DNS 服务器,找到服务器主机,向服务器发出一个请求,服务器经过解析之后,发送给用户的浏览器 HTML、JS、CSS 等文件,浏览器解析出来,用户便可以看到形形色色的图片了。 因此,用户看到的网页实质是由 HTML 代码构成的,爬虫爬来的便是这些内容,通过分析和过滤这些 HTML 代码,实现对图片、文字等资源的获取。
3.URL 的含义
URL,即统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的 URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
URL 的格式由三部分组成: ①第一部分是协议 (或称为服务方式)。 ②第二部分是存有该资源的主机 IP 地址 (有时也包括端口号)。 ③第三部分是主机资源的具体地址,如目录和文件名等。
爬虫爬取数据时必须要有一个目标的 URL 才可以获取数据,因此,它是爬虫获取数据的基本依据,准确理解它的含义对爬虫学习有很大帮助。
什么是结构化和非结构化的数据,处理方式?
非结构化的数据处理
文本、电话号码、邮箱地址
正则表达式Python正则表达式
HTML文件
正则表达式
XPath
CSS选择器
结构化的数据处理
JSON文件
JSON Path
转化为Python类型进行操作(json类)
XML文件
转化为Python类型(xmltodict)
XPath
CSS选择器
正则表达式
我们先向对方服务器发送一个请求,对方给我们返回数据,通常获取到的数据是html数据或者json数据,先来看看非结构化的html处理,也就是我们发起一个请求,对面直接给我们返回的是页面源码,这里我们有三种方式可以用来处理数据
- 使用正则表达式处理
- 使用xpath处理
- 使用css选择器处理
让我们来试试看
这里我们看一个网站顶点小说(使用这个网站是因为它没有反爬机制)
这里我们的目标是
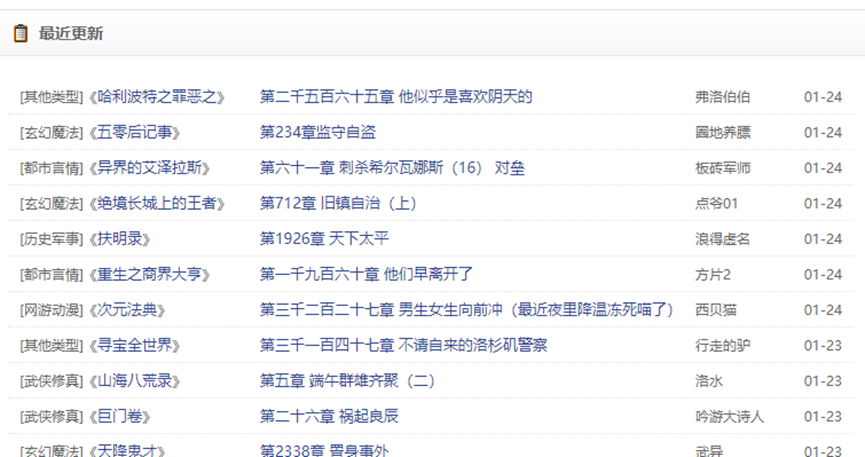
首先是正则,基本规则我们之前应该学过,这里提供一个正则测试网站
https://tool.oschina.net/regex/#
可以方便调试
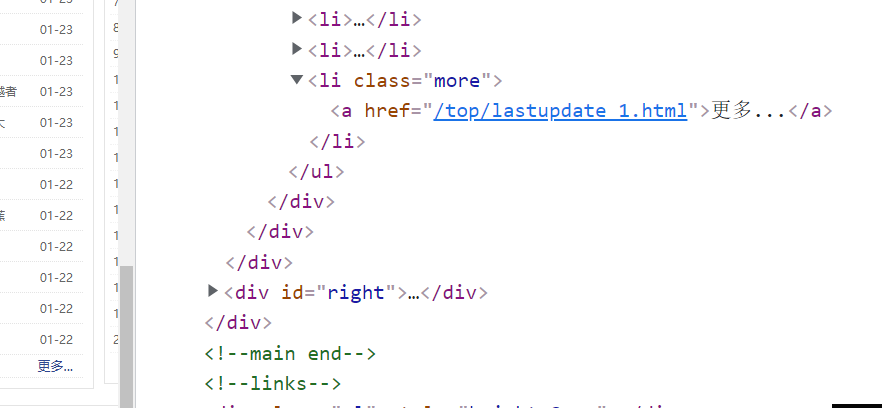
打开F12,选择要获取的数据,然后复制html,如图:
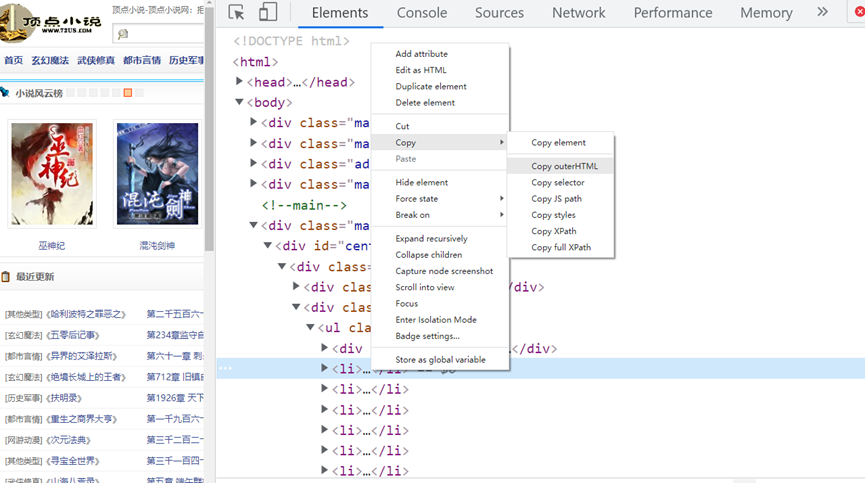
<li><p class="ul1">[其他类型]《<a class="poptext" href="https://www.72us.com/book/26856.html" title="哈利波特之罪恶之书" target="_blank">哈利波特之罪恶之</a>》</p><p class="ul2"><a href="/book/26/26856/17070016.html" target="_blank">第二千五百六十五章 他似乎是喜欢阴天的</a></p><p>弗洛伯伯</p>01-24</li>
这里将需要的部分用()包着,每行不一样的地方都需要修改,你可以用.*?代替它们,不过.*?尽可能少用,因为这会降低正则的匹配效率,这里我们为了方便就先用.*?代替
然后利用正则提取我们想要的部分得到:
import requests from lxml import etree import re from pyquery import PyQuery as pq source = requests.get('https://www.72us.com/').content.decode('gbk') demo = re.compile( '<li><p class="ul1">\[(.*?)\]《<a class="poptext" href="(.*?)" title=".*?" target="_blank">(.*?)</a>》</p><p class="ul2"><a href="(/book/\d+/\d+/\d+\.html)" target="_blank">(.*?)</a></p><p>(.*?)</p>(\d+-\d+)</li>') values = demo.findall(source) print(values)
效果如下

可以看到我们已经成功获取到了数据,之后根据获取到的数据项数循环打印即可,但是我们会发现比较难的问题就是整个过程比较麻烦,正则虽然好用,但是如果错一点点可能提取的结果就天差地别,所以我们这里可以
学习一下xpath
我们这里说的根据xpath获取数据实际就是根据html的标签获取数据
需要先引入包
from lxml import etree
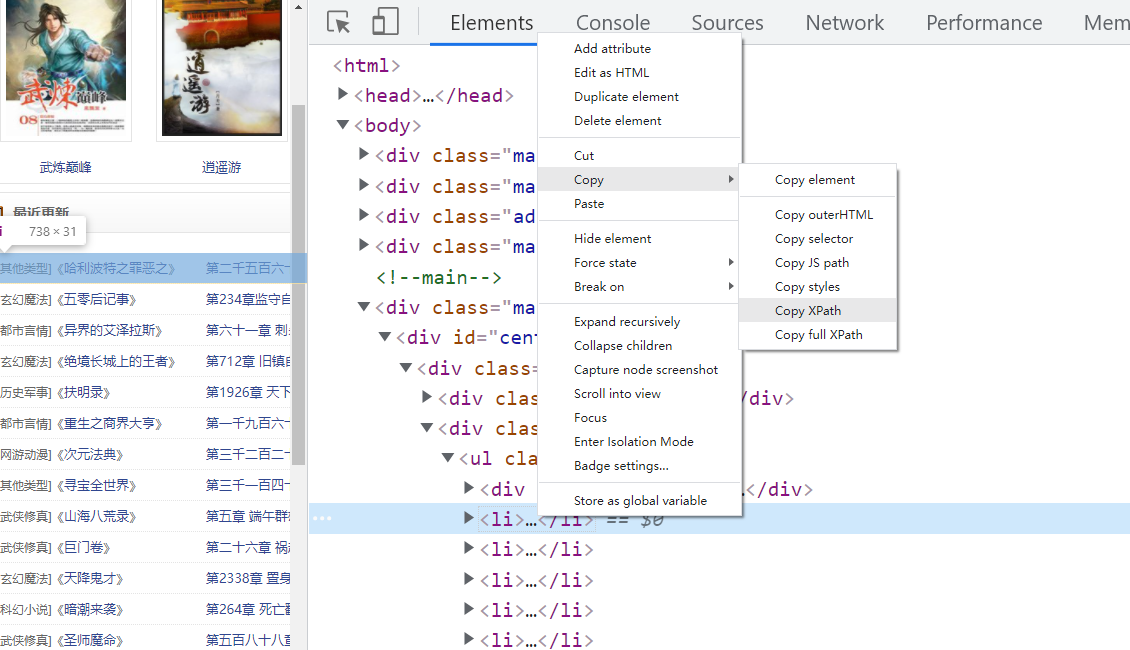
可以这样复制xpath的路径,然后得到
//*[@id="centeri"]/div/div[2]/ul/li[1]
这里//代表这是一个相对路径,前面还有东西,*代表了任意标签,后面的【】则是对前面*的描述,表示要找到一个上面有id="centeri"属性的任意标签,之后是定位到这个标签的div标签下的第二个div标签下的url下的第一个li
我们可以发现我们要的东西都包含在li里,而且是所有li,第一步可以删除li后面的1,这样相当于定位到这个位置所有的li而不是只有第一个,之后遍历,这样可以用遍历出来的元素接着获取需要的元素代码如下:
import requests from lxml import etree source = requests.get('https://www.72us.com/').content.decode('gbk') values = etree.HTML(source).xpath('//*[@id="centeri"]/div/div[2]/ul/li') for i in values: types = i.xpath('p[1]/text()[1]') book = i.xpath('p[1]/a/text()') print(types,book)
这样我们获取书的分类和书名的时候就可以不用再写前面相同的部分了,而是从不同的部分写起
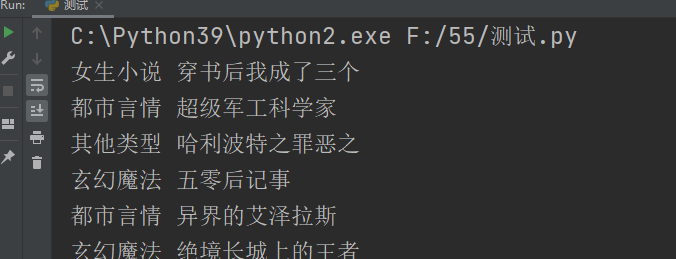
获得
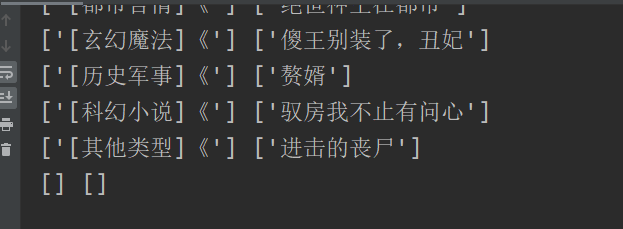
东西是出来了,但是后面有空的,原因就是最后的li是更多,是我们不需要的,直接舍弃就好
另外也需要把分类再处理一下,使用替换和正则都行,代码如下
import requests from lxml import etree import re source = requests.get('https://www.72us.com/').content.decode('gbk') values = etree.HTML(source).xpath('//*[@id="centeri"]/div/div[2]/ul/li') for i in values[:-1]: types = re.compile('\[(.*?)\]《').findall(i.xpath('p[1]/text()[1]')[0])[0] book = i.xpath('p[1]/a/text()')[0] print(types,book)
这里我们只获取了前两项,其他项请大家自己获取
好的上面我们简单使用xpath,接下来我们看下xpath里我们常用的语法
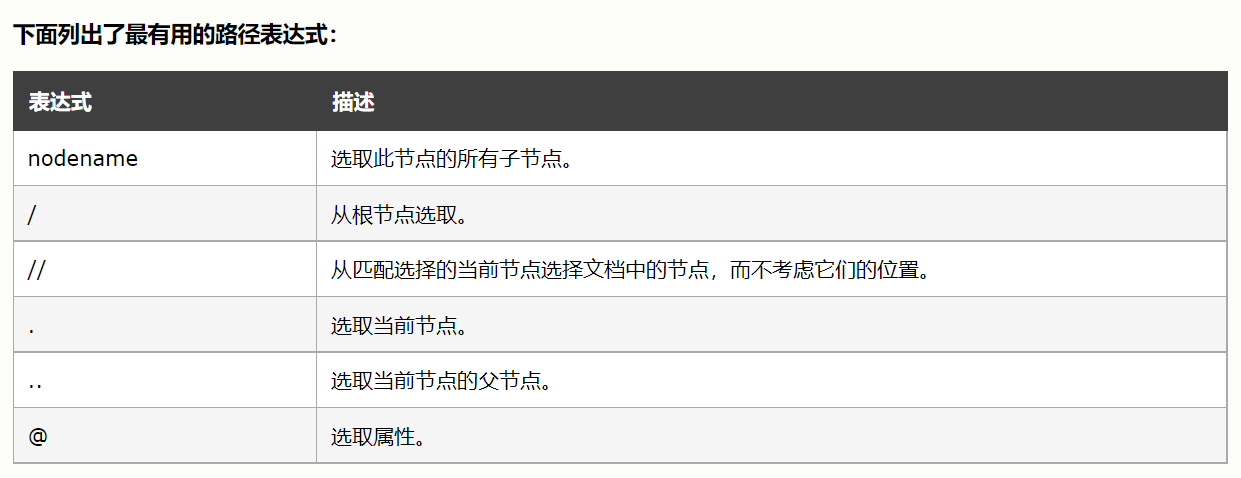

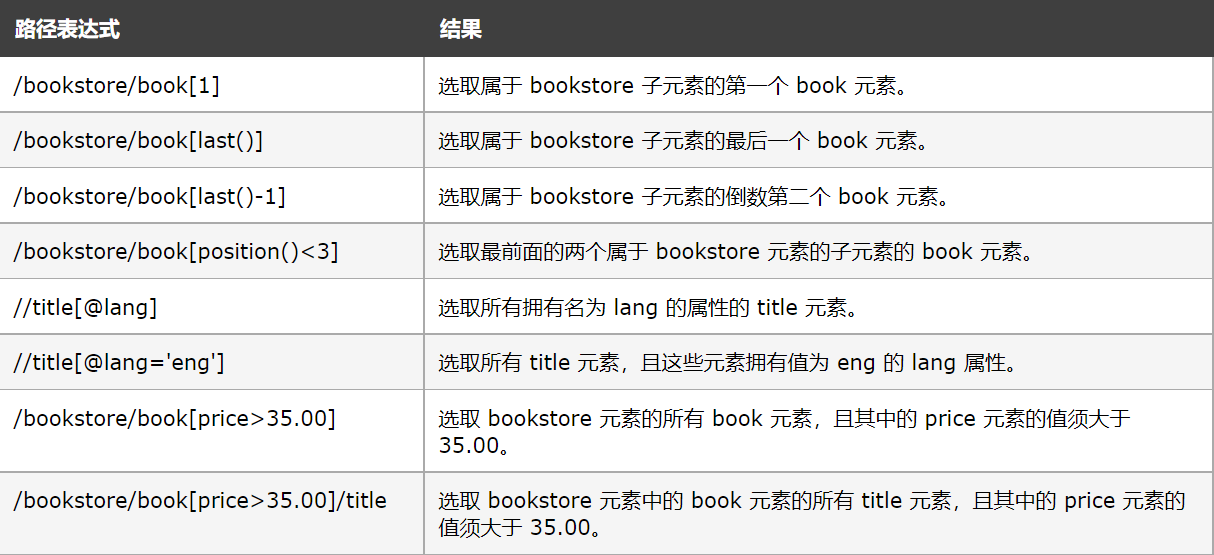

看了上面xpath的介绍,我们应该可以看出xpath的强大了,我们粘贴的xpath实际上是找你当前要定位的元素最近的有id属性的元素开始,如果没有就继续往更外一层找,如果一直没有,那么就会从根目录开始了
就不是一个相对路径了,如果带有id属性的元素离你定位的元素比较远,那么就会导致xpath复制的路径很长,这样只要中间稍微变化那原来定位的xpath路径就会失效,所以我们可以自己来写,比如我们刚才定位li的那个xpath
'//*[@id="centeri"]/div/div[2]/ul/li'
可以改成
'//ul[@class="update"]/li'
values = etree.HTML(source).xpath('//ul[@class="update"]/li')
效果和刚才没有任何变化
关于xpath 还有一些实用的东西
starts-with 顾名思义,匹配一个属性开始位置的关键字
contains 匹配一个属性值中包含的字符串
text() 匹配的是显示文本信息,此处也可以用来做定位用
例如
//input[starts-with(@name,'name1')] 查找name属性中开始位置包含'name1'关键字的页面元素
//input[contains(@name,'na')] 查找name属性中包含na关键字的页面元素
<a href="http://www.baidu.com">百度搜索</a>
xpath写法为 //a[text()='百度搜索']
或者 //a[contains(text(),"百度搜索")]
这么多用法不可能一天用熟,多练习才是关键
那么如何使用css的格式提取数据呢?其实xpath和css差不多,都是通过标签获取数据,两个精通一个就行了,那么我们看看css形式的
1.安装方法
pip install pyquery
2.引用方法
from pyquery import PyQuery as pq
3.简介
pyquery 是类型jquery 的一个专供python使用的html解析的库,使用方法类似bs4。
如果修改一下,代码应该是这样的
import requests from lxml import etree import re from pyquery import PyQuery as pq source = requests.get('https://www.72us.com/').content.decode('gbk') doc = pq(source) li = doc('.update li').items() for i in list(li)[:-1]: demo = re.compile('\[(.*?)\]《(.*?)》').findall(i.find('.ul1').text())[0] types = demo[0] book = demo[1] print(types,book)
这里我们只是简单使用一下,如果想了解更多关于css选择器的用法可以百度
接下来就是全站抓取的思路了
根据导航条知道,不同的分类所对应的url前面的数不同
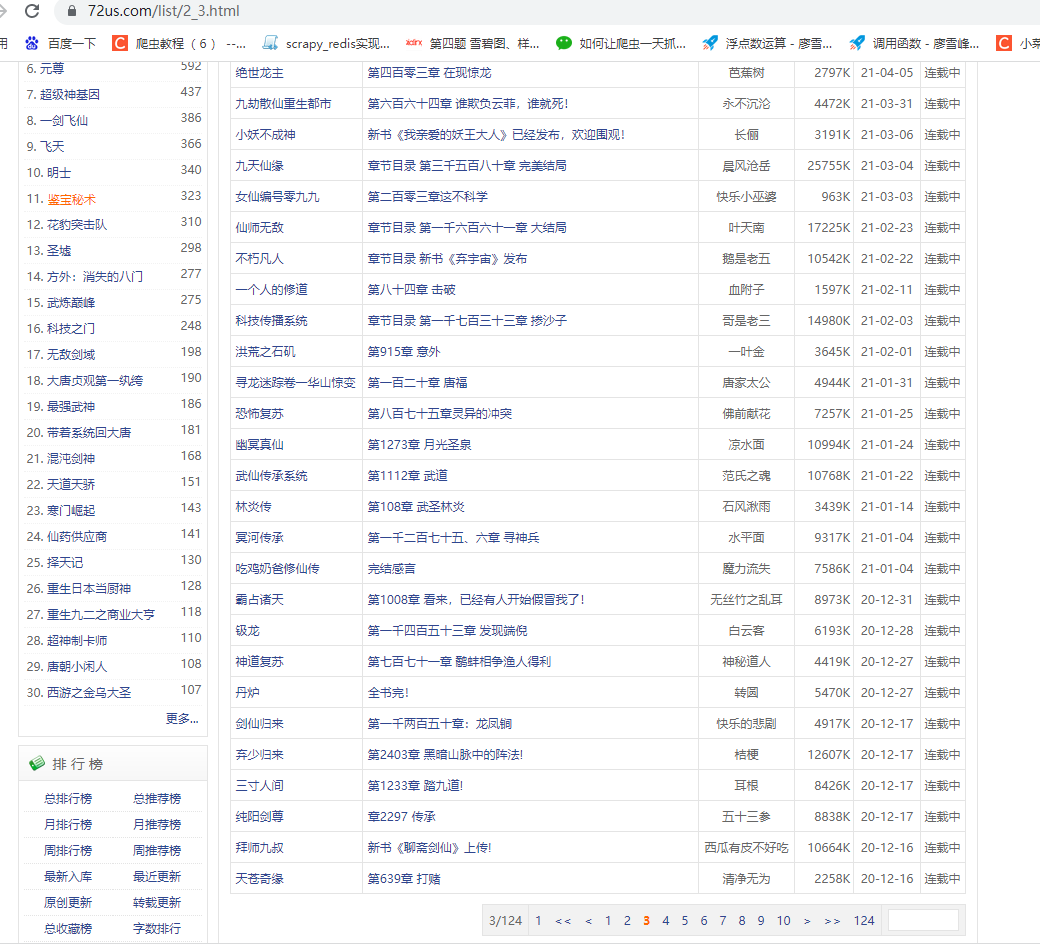
再翻页,发现后面的数对应的是页数,这里页数是3,分类是武侠修真,对应的是前面的数字2
如果能够获取每个分类下的最大页数,那么就可以通过两层循环,遍历出每个分类下的所有页所对应的url
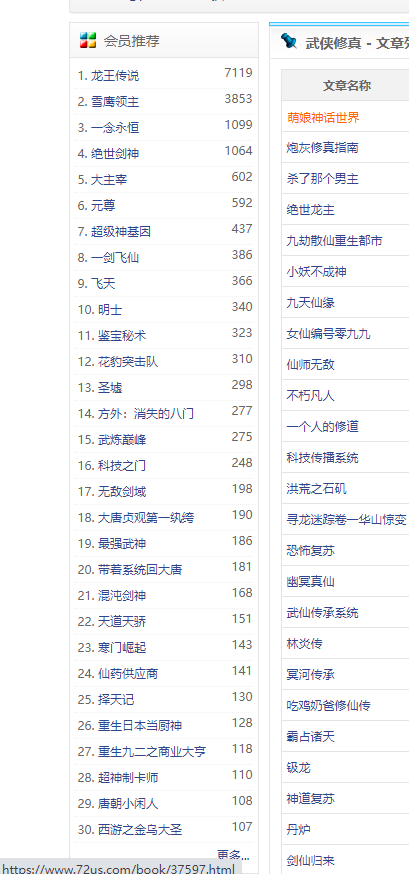
鼠标移动到超链接上,左下角可以看到超链接里有书的ID,这里是37597,如果能获取到书的ID,那么我们就可以进到列表页面,我们查看下章节列表页面:
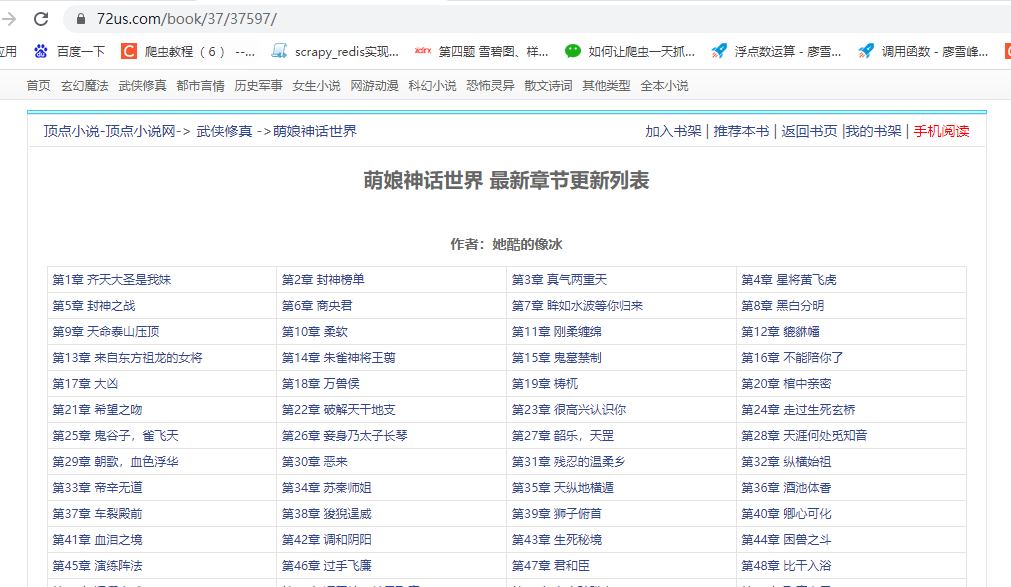
可以看到,章节列表页的链接就是书的id的前2位,加上书的ID,我们只要得到了书的ID就可以拼出章节列表页的链接,然后请求获取到这本书所对应的章节列表页的源码
之后再获取每个章节的链接,那么就可以获取这本书每个章节的名字和内容了,之后入库,这里我们如果要存mysql数据库,那么使用pymysql 批量插入即可

 浙公网安备 33010602011771号
浙公网安备 33010602011771号