《Streaming Systems》第二章: 数据处理中的 What, Where, When, How
 《Streaming Systems》第二章译文,通过对 What,Where,When,How 这 4 个问题的回答,逐步揭开流处理过程的全貌。
《Streaming Systems》第二章译文,通过对 What,Where,When,How 这 4 个问题的回答,逐步揭开流处理过程的全貌。
本章中,我们将通过对 What,Where,When,How 这 4 个问题的回答,逐步揭开流处理过程的全貌。
-
What:计算什么结果?
也就是我们进行数据处理的目的,答案是转换(transformations),例如求和、训练机器学习模型,都是转换。是批处理和流处理都需要面对的问题。 -
Where:在哪里计算结果?
答案是窗口(windowing)。是批处理和流处理都需要面对的问题。 -
When:何时计算结果?
答案是触发器 + 水位线(triggers + watermarks)。这是一个只有流处理需要面对的问题,批处理不需要考虑此问题的原因是:批处理计算结果的时间是确定的 —— 数据集输入结束的时候。 -
How:如何修正结果?
答案是累积(accumulation)。批处理不需要考虑这个问题,批处理只有在数据输入结束时才输出计算结果,只输出一次结果因此不存在修正问题。流处理则不同,输入数据是无界的,随着数据不断输入,实时结果不断被更新,新的结果如何修正之前的结果是必须要考虑的。
批处理基础: What and Where
What: Transformations
第一个问题:计算什么结果?答案是 转换(Transformations)。转换的概念很宽泛,求和运算是一种转换,训练机器学习模型也是一种转换。为了便于下文描述,我们引入一个样例数据集。数据集记录了某次手游比赛战队中每个成员的得分情况。
数据集中各字段含义如下:
- Name:队员名
- Team:战队名
- Score:得分
- EventTime:得分记录的事件时间,即产生得分记录的时间
- ProcTime:得分记录的处理时间,即得分记录流入管道进行计算的时间
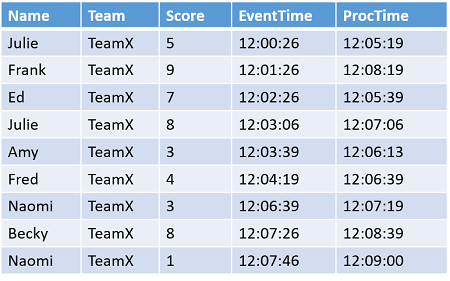
以 EventTime 为横坐标,ProcTime 为纵坐标,将样例数据集中的 9 条记录标注在平面直角坐标系中,如下图所示:
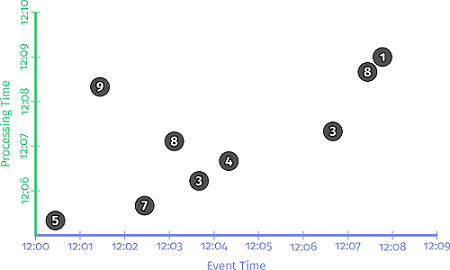
比赛是以战队为单位进行的,为了计算哪个战队胜出,需要统计战队中所有队员的得分的和。完整的处理逻辑是:读入原始数据;将原始数据解析成为格式化数据便于后续计算;以 Team 为主键,对 Score 做求和操作。示例代码如下:
// 读入原始数据 PCollection<String> raw = IO.read(...); // 将原始数据解析成为格式化数据 PCollection<KV<Team, Integer>> input = raw.apply(new ParseFn()); // 对每个主键 Team, 对 score 做求和操作 PCollection<KV<Team, Integer>> scores = input.apply(Sum.integersPerKey());
这段逻辑在样例数据集上的执行过程如下图所示。图中,X 轴是 EventTime,Y 轴是 Processing Time。黑色实线自下而上推进,表示随着时间的推移数据依次流入系统中进行计算。Pipeline 每捕获一条记录,就将其累加到当前结果中,作为当前 Processing time 时间点上的中间结果,用白色数字表示,处理时间 12:06 中间结果是 12,12:08 中间结果是 30,当扫描完整个数据集之后,输出最终结果 48。
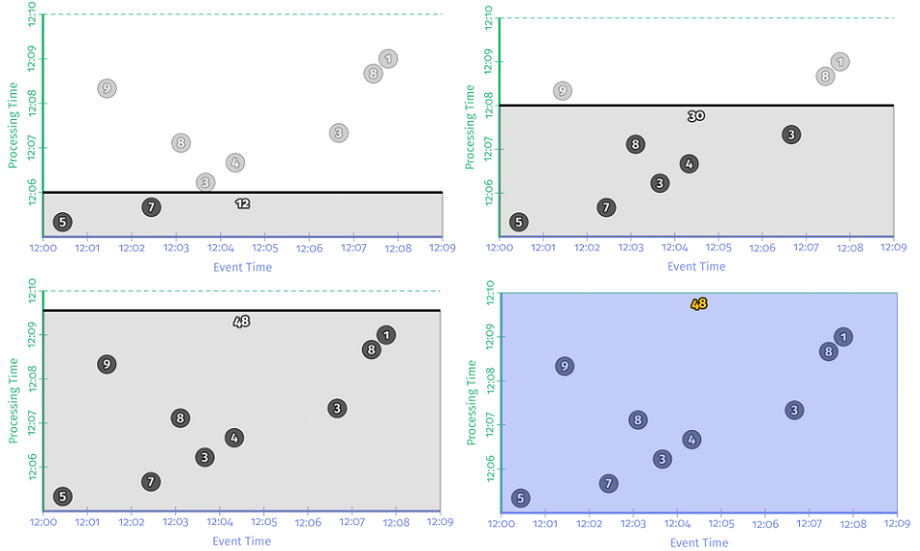
这就是整个经典批处理的处理过程。由于数据是有界的,因此在 Processing time 上处理完所有数据后,就能得到正确结果。但是如果数据集是无界数据的话,这样处理就有问题,因为理论上来说,无界数据集的输入永远不会停止。
Where: Windowing
处理无界数据的有效办法还是 窗口,这也是第二个问题 “在哪里计算结果?” 的答案——窗口。
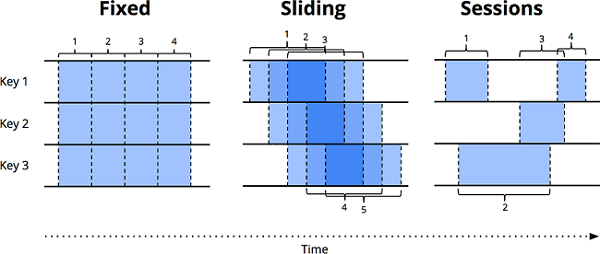
窗口的划分策略,在 第一章 中已有提及,下图所示为常用的三种窗口划分策略:固定窗口、滑动窗口、会话窗口。
在示例 2-1 的基础上添加窗口,窗口类型选择 Fixed,窗口大小设置为 2 分钟,于是就有了示例 2-2:
PCollection<KV<String, Integer>> scores = input.apply(Window.into(FixedWindows.of(TWO_MINUTES))) .apply(Sum.integersPerKey());
示例 2-2 在样例数据集上的执行过程如下图所示。从时序图上可以看出,在事件时间上,以 2 分钟为步长,数据被划分到相应的窗口,求和运算在窗口内部进行,每个窗口都有独立的求和结果,当处理完整个数据集时,将每个窗口的输出进行累加就可以得到最终的求和结果。
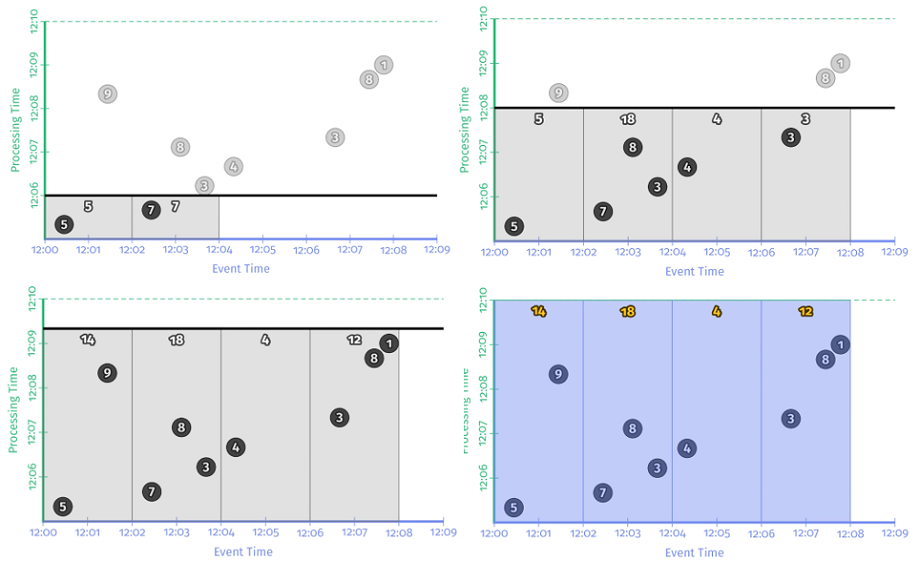
窗口的引入似乎能帮助我们在一定程度上解决无界数据处理的问题,因为它能把大的数据拆分成小的,但是还没有从根本上解决的问题是:依然需要等待整个数据集输入完成才能输出最终结果。
流处理进阶: When and How
目前为止我们还停留在批处理层面,依然要等待整个数据集输入完成才能给出最终计算结果。这在无界数据流计算中是不可行的,为此我们引入 触发器(Trigger)和水印(Watermark) 的概念,这也是第三个问题 “何时触发计算结果” 这个问题的答案。
When: Triggers
一般而言,触发器分为两种类型:
- 重复更新式触发器:积累到一定数量的记录后触发(每累计 n 条记录),或每隔一段时间周期性地触发(每秒钟/每分钟)。
- 完整性触发器:当属于某个窗口的数据全部到达时触发。
重复更新式触发器最简单也最常用,我们在 示例 2-2 的基础上增加一个触发器就得到了 示例 2-3,每遇到一条新记录就更新一次计算结果:
PCollection<KV<String, Integer>> scores = input.apply(Window.into(FixedWindows.of(TWO_MINUTES)) .triggering(Repeatedly(AfterCount(1)))) .apply(Sum.integersPerKey());
示例 2-3 在样例数据集上的运行时序图如下:
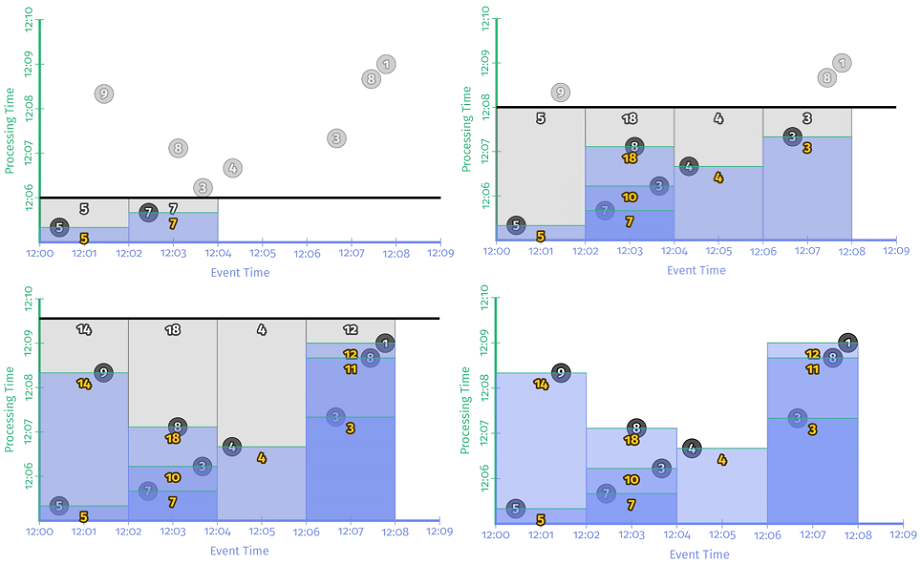
有了触发器,每个窗口的结果能够比较实时地更新了,并且随着时间的推移,在不断向正确结果收敛。不过,每遇到一个新记录就更新一次结果的方式太过频繁了,如果样例数据集中有很多 Team,每个 Team 中都有很多活跃的玩家,可想而知这种触发方式给系统带来的负载会很大。那 每隔一段时间周期性更新结果 的触发方式怎么样呢,例如 每秒钟/每分钟 更新一次?
这种类型的触发器又可以分为 对齐延时触发 (将处理时间上切分成固定大小的时间片,然后按照固定时间来触发计算) 和 非对齐延时触发 (延时时间与窗口内数据有关,是按照数据进入系统的时间+延时时间触发计算)。
引入对齐延时触发器的程序如 示例 2-4 所示,运行结果如 图 2-7 所示。
PCollection<KV<String, Integer>> scores = input.apply(Window.into(FixedWindows.of(TWO_MINUTES)) .triggering(Repeatedly(AlignedDelay(TWO_MINUTES)))) .apply(Sum.integersPerKey());
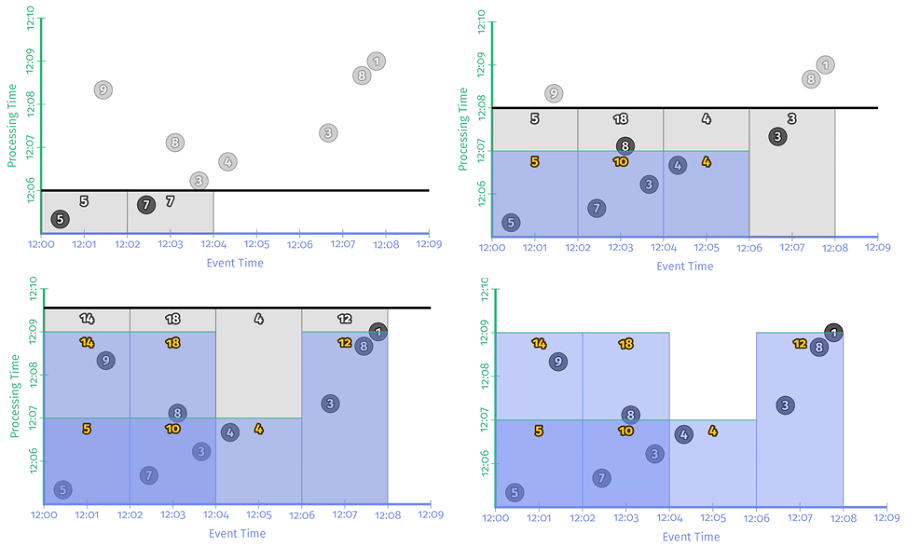
可以看到,每间隔 2min,各窗口更新一次计算结果,这样的更新触发分别发生在处理时间轴的 12:07,12:09。与逐条记录更新的方式相比,对齐延时触发器更新不再那么频繁了,但也有缺点:要更新所有窗口同时更新,每当更新时间到达,系统负载会突发性地增加。与之相比,非对齐延时触发器则能很好的避免这个问题。
引入非对齐延时触发器的程序如 示例 2-5 所示,运行结果如 图 2-8 所示。
PCollection<KV<String, Integer>> scores = input.apply(Window.into(FixedWindows.of(TWO_MINUTES)) .triggering(Repeatedly(UnalignedDelay(TWO_MINUTES)))) .apply(Sum.integersPerKey());
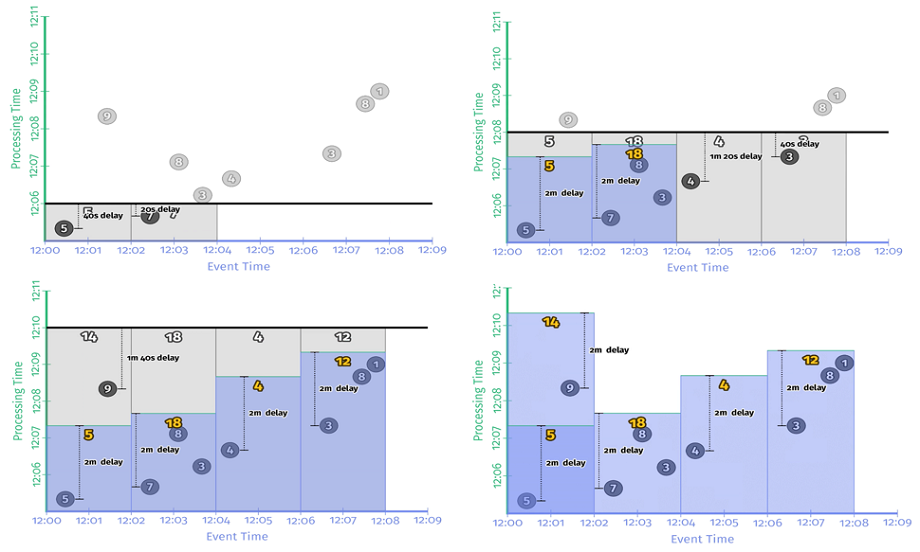
可以看到,非对齐延时触发器是以有数据进入窗口的时间作为起点开始计时,在 进入时间 + 延时时间 触发计算。至于平均延迟,应该和对齐延时触发器是一致的。从这个角度来看,未对齐延时触发器通常是大规模数据处理的更好选择,因为随着时间的推移,它能更好的均分负载。
有了触发器的窗口,能够比较实时的更新计算结果而不用等待整个数据集输入完成了,但是还有一个问题亟待解决:这些窗口什么时候关闭呢?一直处于开启状态的窗口会很占用资源的。
什么时候可以关闭窗口呢?就是当属于这个窗口的所有数据都到齐了的时候。
那如何判断属于这个窗口的数据都到齐了呢?
由于这是事件时间窗口,事件时间本身可能就是乱序到达的,由于网络传输等原因,数据迟到也不是啥稀奇事,如何判断窗口中事件的完整性可是个难题,这时就需要完整性触发器了,watermark 就是一种完整性触发器。
When: Watermarks
什么是 watermarks?看一下《Streaming Systems》中原文是怎样描述的:
Watermarks are temporal notions of input completeness in the event-time domain. Worded differently, they are the way the system measures progress and completeness relative to the event times of the records being processed in a stream of events (either bounded or unbounded, though their usefulness is more apparent in the unbounded case).
Flink 官方文档中 对 watermark 的定义如下:
The mechanism in Flink to measure progress in event time is watermarks. Watermarks flow as part of the data stream and carry a timestamp t.
A Watermark(t) declares that event time has reached time t in that stream, meaning that there should be no more elements from the stream with a timestamp t' <= t(i.e. events with timestamps older or equal to the watermark).
综合以上,Watermarks 在事件时间域衡量数据完整性的概念,Watermarks 作为数据流的一部分流动并携带时间戳 t,Watermark(t) 断言数据流中不会再有小于时间戳 t 的事件出现。换言之,当 Watermark(t) 到达时,标志着所有小于时间戳 t 的事件都已到齐,可放心地对时间戳 t 之前的所有事件执行聚合、窗口关闭等动作。
从概念上讲,可以把 watermark 理解成一个函数 \(F(P) \rightarrow E\),向这个函数输入一个处理时间 P,就返回对应的事件时间 E,含义是事件时间小于 E 的数据都已经到齐,换言之,断言事件时间小于 E 的数据不会再出现。
结合 watermark 的定义,回顾一下 第一章 中 事件时间和处理时间的关系图,红色的代表 Reality 的曲线,实际上不就是 watermark 吗?
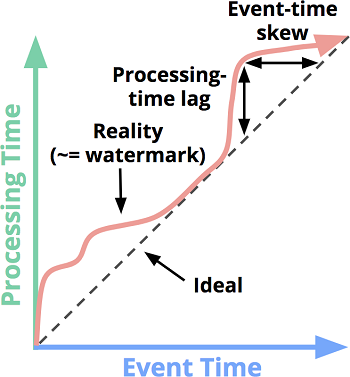
如果按照 Flink 官方文档的理解,可以把 watermark 想象成如下图所示:
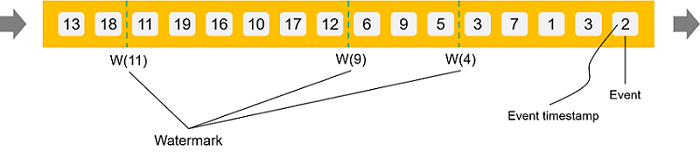
Watermark 是一种判断数据完整性的理念,是一种断言,既然是断言,就有可能是 100% 严格保证或仅仅是有根据的猜测,前者我们称之为 完美型水位线(Perfect watermark),后者我们称之为 启发式水位线(Heuristic watermarks)。
-
完美型水位线(Perfect watermark)
当我们完全了解所有输入数据的情况时,是可以构建完美型水位线。 在这种情况下,没有诸如数据迟到之类的情况发生,所有数据都是提前或准时到达的。 -
启发式水位线(Heuristic watermarks)
对于许多分布式数据源来说,100% 掌握输入数据的先验知识是不切实际的,在这种情况下,我们只能退而求其次选择相对准确的启发式水印。 可以利用的启发式信息包括但不限于分区信息、网络带宽、网络拓扑、数据增长速率。相对准确 的含义是可能会出错,可能会存在迟到数据,至于如何处理迟到数据,我们后面展开讨论。
Watermarks 本身是一个复杂的话题,我们在 第三章 中详细展开讨论。我们先来看看,引入了 watermark 之后,可否真的解决前文遇到的 数据完整性 问题。引入 watermark 后的程序如 示例 2-6 所示。
PCollection<KV<String, Integer>> scores = input.apply(Window.into(FixedWindows.of(TWO_MINUTES)) .triggering(AfterWatermark())) .apply(Sum.integersPerKey());
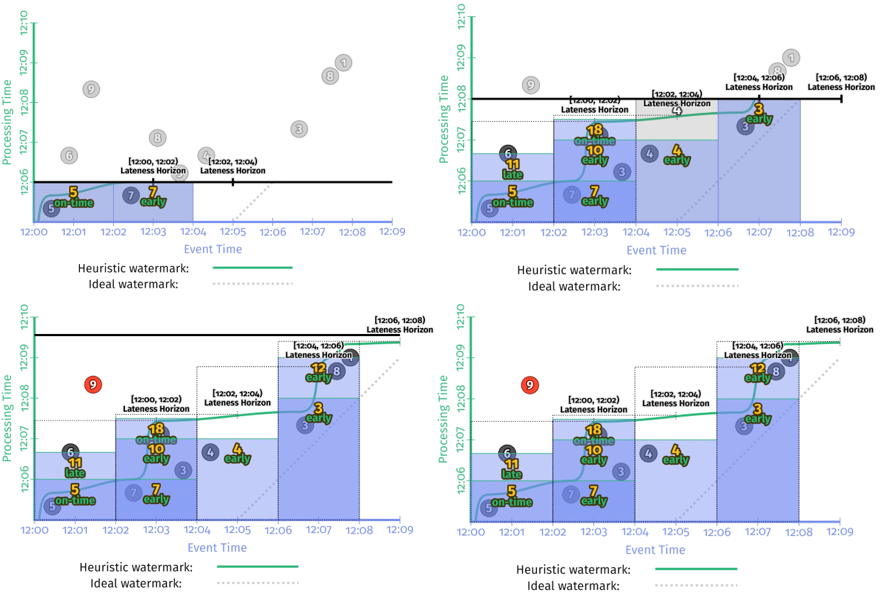
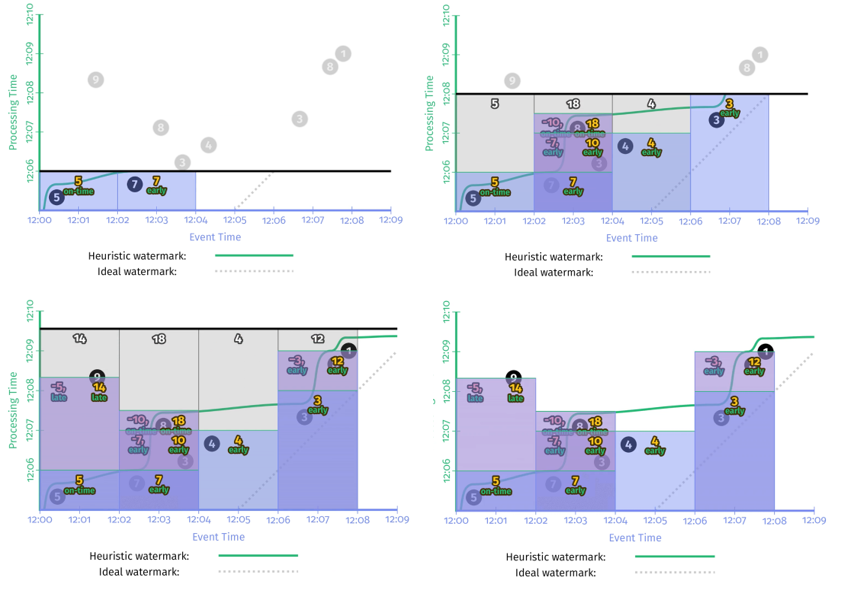
注意 AfterWatermark() 是一个函数,意味着我们需要根据具体情况具体实现,作为对比,假设我们同时实现了完美型水位线和启发式水位线,两种类型水位线在同一样例数据集上的运行结果如 图 2-10 所示:
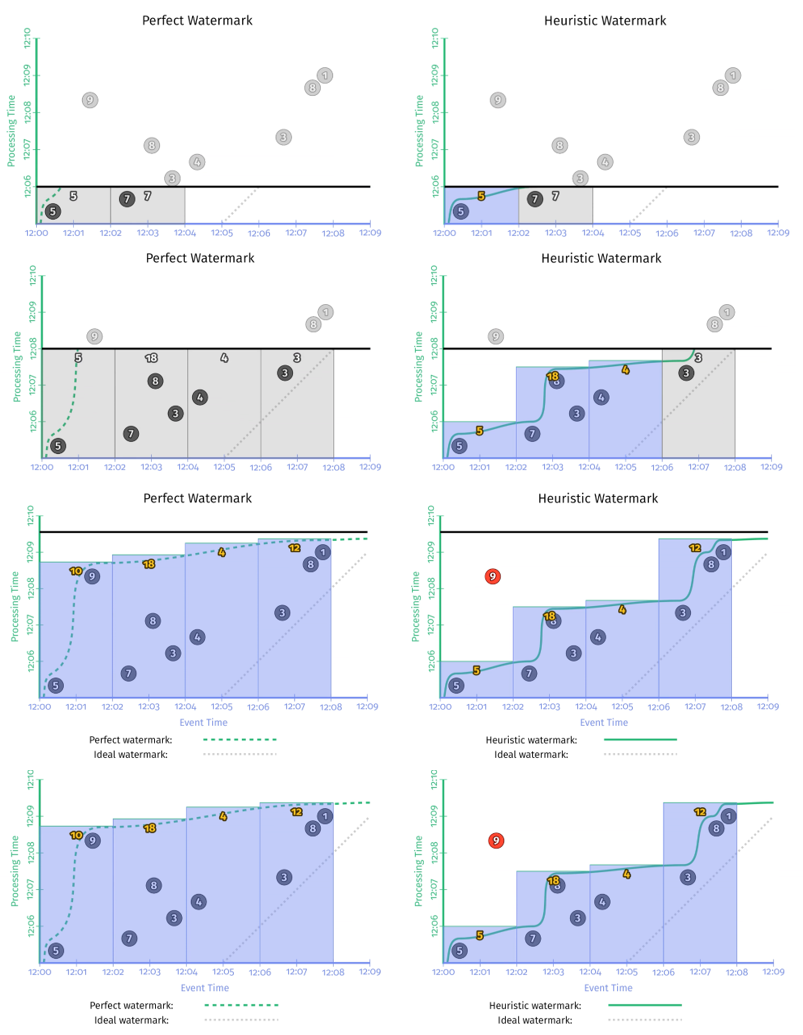
图中左侧为 Perfect Watermark,右侧为 Heuristic Watermark。每次 watermark 经过窗口右界时,窗口都会输出计算结果。区别是 Perfect Watermark 的结果始终是正确的(书中插图存在一处笔误,Perfect Watermark 在窗口 [12:00, 12:02] 的结果应该是14),而 Heuristic Watermark 在时间窗口 [12:00, 12:02] 的结果是错误的,少计算了 “9” 这个数据。
通过对比 图2-10 和 图2-6 图2-7 图2-8,Watermark 和重复更新式触发器的最大不同之处在于:watermarks give us a way to reason about the completeness of our input。如果您想要推断输入中是否 缺少数据/丢失数据,这一点就显得尤其重要了。一个典型的例子就是 outer join,试想如果没有 watermark,你怎么知道什么时候该放弃等待输出 partial join 结果,什么时候该继续等待另一部分数据的到来? 你无从知道。
当然,从 图 2-10 中我们可以看到 watermark 也存在缺点:
-
输出太慢
如果数据流中有晚到数据,越趋近于 perfect 的 watermark,将会一直等待这个 late event,而不会输出结果,这会导致输出的延时增加。 -
输出太快
启发式 watermark 的问题是输出太快,会导致结果不准。
因此,水印并不能同时保证数据处理过程中的低延时和正确性。既然重复更新触发器(Repeated update triggers)可以保证低延时,完整性触发器(Completeness triggers),能保证结果正确。那能不能将两者结合起来呢?
When: Early/On-Time/Late Triggers FTW!
注:FTW(For The Win)作用是表达对某一事物喜欢到极致的心情,属于网络用词。
如果将两种触发器的优势结合,即允许在 watermark 之前/之时/之后 使用标准的重复更新触发器。就产生了 3 种新的触发器:Early/On-time/Late trigger:
-
Early
在 watermark 经过窗口之前就周期性的输出结果。这些结果可能是不准确的,但是避免了 watermark 输出太慢的问题。 -
On-time
仅在 watermark 通过窗口右界时触发一次。这时的结果可以看作是准确的。 -
Late
在 watermark 通过窗口结束边界之后,如果这个窗口有 late event,也可以触发计算。允许迟到数据更新窗口结果,避免了输出太快导致的结果不对的问题。
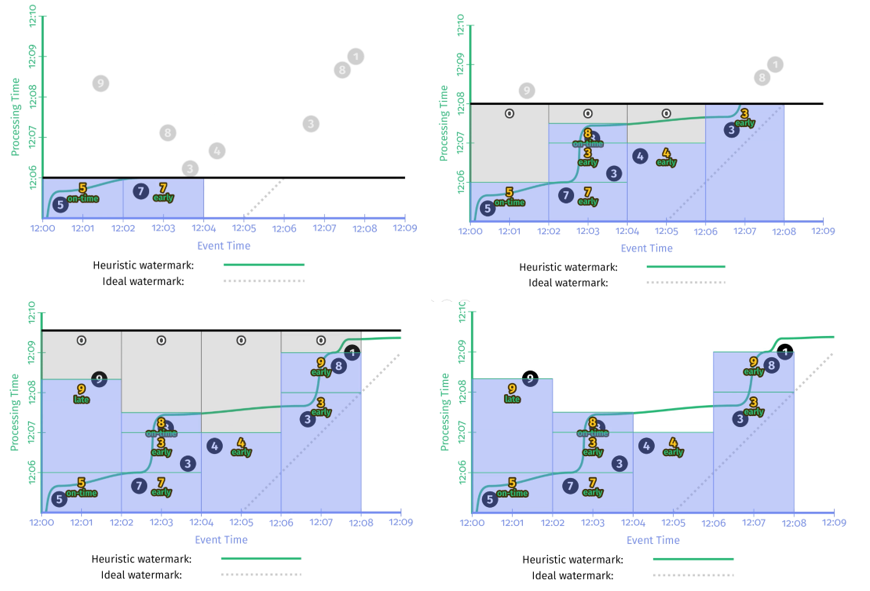
引入 Early/On-Time/Late 触发器,于是就有了 示例 2-7:
PCollection<KV<String, Integer>> scores = input.apply(Window.into(FixedWindows.of(TWO_MINUTES)) .triggering(AfterWatermark() .withEarlyFirings(AlignedDelay(ONE_MINUTE)) .withLateFirings(AfterCount(1)))) .apply(Sum.integersPerKey());
示例 2-7 在样例数据集上的运行结果如 图 2-11 所示,在 watermark 到来之前采用对齐延时方式每隔 1 分钟触发一次结果更新,在 watermark 经过窗口右界时触发一次结果更新,在 watermark 经过之后每累计超过 1 个事件也触发一次结果更新。
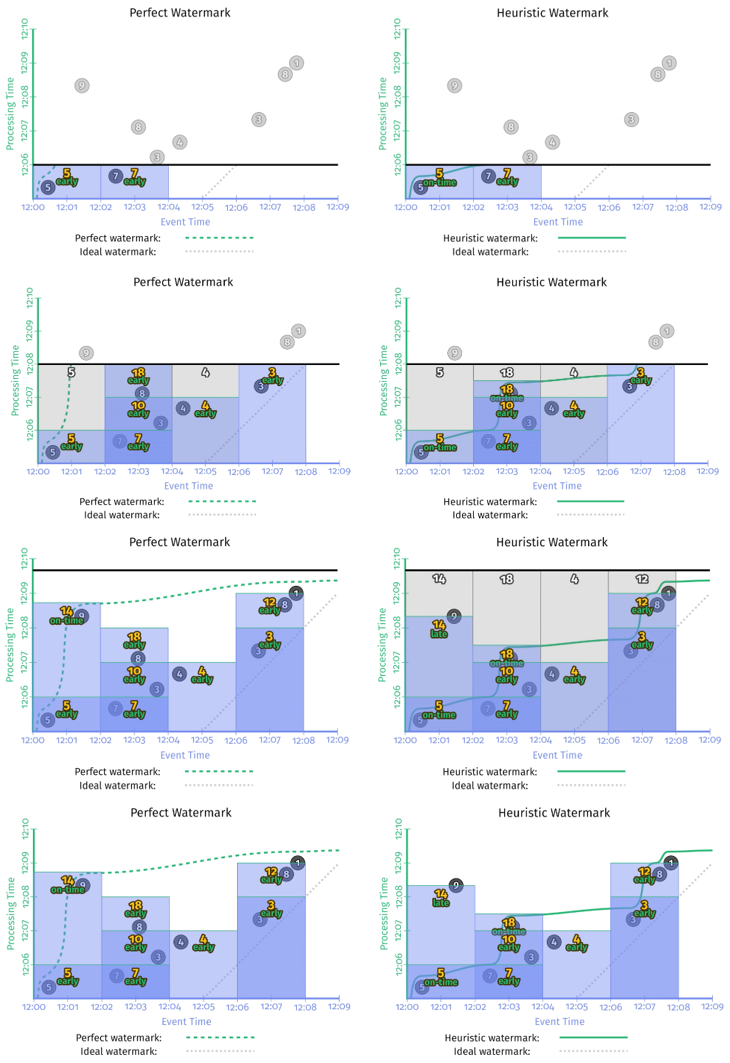
通过对比 图2-11 和 图 2-10 可以发现 Early/On-Time/Late 触发器改善了 watermark 的 输出太慢 和 输出太快 的问题,无论是 Perfect Watermark 还是 Heuristic Watermark 最终都得到了正确的计算结果。
完美型 watermark 和启发式 watermark 一个非常大的区别是,在完美型 watermark 例子中,当 watermark 经过窗口结束边界时,这个窗口里的数据一定是完整的,因此得出该窗口计算结果之后,就可以把这个窗口的状态和数据全部删除了。但启发式 watermark 中,由于 late event 的存在,为了保证结果的正确性,需要把窗口的数据保存一段时间。但其实我们根本不知道要把这个窗口的状态保存多长时间。这就需要引入一个新的概念:Allowed Lateness。
When: Allowed Lateness
实际生产环境中,由于磁盘大小等限制,窗口的状态不可能无限的保存下去。因此,需要为窗口状态定义一个最大保存时间,换言之,就是为窗口中的数据定义一个最大允许延迟时间 Allowed Lateness,过了这个时间,窗口的状态和数据会被清理掉,之后到来的 late event 也不会被处理了。流处理系统选择将 Allowed Lateness 参数开放给用户,让用户决定是否耗费更多资源去保证结果的准确性。
在 示例 2-7 的基础上,引入 Allowed Lateness 就有了 示例 2-8:
PCollection<KV<String, Integer>> scores = input.apply(Window.into(FixedWindows.of(TWO_MINUTES)) .triggering(AfterWatermark() .withEarlyFirings(AlignedDelay(ONE_MINUTE)) .withLateFirings(AfterCount(1))) .withAllowedLateness(ONE_MINUTE)) .apply(Sum.integersPerKey());
本例中设置 Allowed Lateness 为 1 分钟,也就是说当 watermark 经过窗口右界时开始计时,1 分钟后窗口将关闭,与窗口有关的状态全部丢弃进行垃圾回收。图中所示数值 “9” 由于迟到时间超过 1 分钟将不会合并到最终结果中。
How: Accumulation
引入了触发器的窗口,结果会被触发多次,自然也会更新多次。新的结果如何修正旧的结果呢?这就是我们面对的第 4 个问题。修正方法分为 3 种:
-
丢弃(Discarding)
窗口每次产生新的输出结果之后,相关 state 都被丢弃。适用于窗口中每次输出的结果都互相独立的场景,比较适合下游是聚合类的运算。 -
累积(Accumulating)
从 示例 2-2 到 示例 2-7 都是采用的累积模式,窗口每次输出的中间结果都会被保存,新的数据到达之后,和上一次的保存结果做累积运算作为新的结果输出。这种方式适合下游是可更新式的数据存储,比如 HBase/Bigtable。 -
累积 & 撤回(Accumulating and retracting)
累积与上文第 2 点一样,即新的数据到达之后,与上一次保存的结果做累积运算。撤回是指,得到新的计算结果之后,还要把上一次窗口输出的结果撤回。含义类似 “我上次告诉你的结果是 X 吧,不好意思是我弄错了,把上次结果 X 丢弃吧,正确结果应该是 Y”。什么时候会用到这种模式呢?
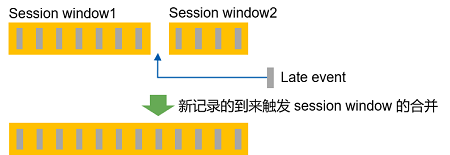
比如会话窗口合并的时候。假设本来有两个会话窗口 Session window 1 和 Session window 2,后来到达一批迟到数据,迟到数据加入后把两个会话窗口之间的 gap 填充了,两个窗口原来是一个窗口,此时就要合并两个窗口得到一个新窗口。可是上次已经把两个会话窗口的结果发往下游了,这次得到的 1 个新窗口,只能覆盖掉上次的一个计算结果,还有一个错误的窗口依然在下游存在。这时候就只能撤回了:撤回两个错误窗口,发射一个新窗口。
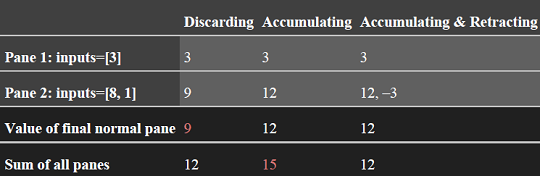
以 图 2-12 中的 [12:06, 12:08] 窗口为例,横向对比一下三种累积模式:
-
如果采用的是 Discarding 模式,只对在特定期间内到达的数据做运算,第一个窗格的结果是 3,第二个窗格的结果是 9,不关心全局信息。如果在下游添加一个聚合算子对每个窗格的结果求和,能得到正确结果 12。这就是为什么说 Discarding 模式适合下游是聚合类的运算 的原因。
-
如果采用的是 Accumulating 模式,新结果是当前窗格的结果 + 之前窗格的累积结果,因此第一个窗格的结果是 3,第二个窗格的结果是 3 + 9 = 12。如果在下游再进行聚合计算,则会存在重复计算的情况,会得到错误的计算结果 15。Accumulating 模式只需用新值覆盖以前的值:新值已经包含了迄今为止看到的所有数据。
-
如果采用的是 Accumulating and retracting 模式,每个窗格的计算结果包含 累积结果 和 上一次的计算结果 两部分。第一个窗格的计算结果是 3,第二个窗格的计算结果是(12,-3)。最后一个窗格的计算结果和所有窗格的累积结果都是正确的结果:12。这就是 累积&撤回 模式强大之处了。
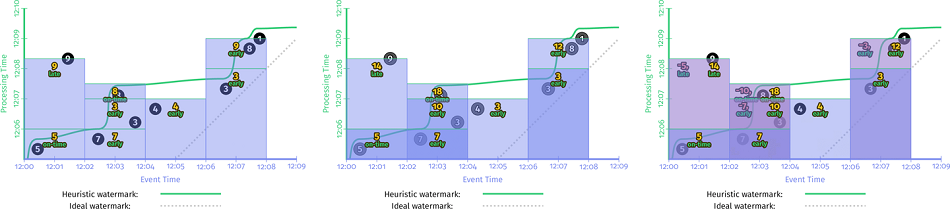
在 示例 2-7 的基础上,引入 Discarding 模式,就有了 示例 2-9:
PCollection<KV<String, Integer>> scores = input.apply(Window.into(FixedWindows.of(TWO_MINUTES)) .triggering(AfterWatermark() .withEarlyFirings(AlignedDelay(ONE_MINUTE)) .withLateFirings(AfterCount(1))) .discardingFiredPanes()) .apply(Sum.integersPerKey());
看一下 示例 2-9 在样例数据集上的运行结果:
再看一下 累积&撤回 模式的示例 2-10:
PCollection<KV<String, Integer>> scores = input.apply(Window.into(FixedWindows.of(TWO_MINUTES)) .triggering(AfterWatermark() .withEarlyFirings(AlignedDelay(ONE_MINUTE)) .withLateFirings(AfterCount(1))) .accumulatingAndRetractingFiredPanes()) .apply(Sum.integersPerKey());
示例 2-10 在样例数据集上的运行结果:
最后将丢弃模式、累积模式、累积&撤回模式放在一起对比一下:
图中从左到右丢弃模式、累积模式、累积&撤回模式对存储的要求和计算复杂度依次递增。因此 How 的选择需要综合考虑结果正确性、延迟、内存、计算复杂度等综合因素。
本章小结
本章中,我们首先详细讨论了以下流处理核心概念:
- 窗口:处理无界数据的有效方式是采用窗口的方式对无界数据进行切分。
- 触发器:用于定义何时触发计算结果更新动作。
- 水位线:一种推断数据完整性的理念,对于处理无界数据中的乱序、迟到、缺失等问题非常有效。
- 累积:当窗口结果需要多次更新时如何修正之前的结果。
其次,我们通过对 what,where,when,how 这 4 个问题的回答,逐步揭开流处理过程的全貌:
- What:计算什么结果?—— 转换
- Where:在哪里计算结果?—— 窗口
- When:在什么时间计算结果?—— 触发器 + 水位线
- How:如何修正计算结果?—— 累积

