Flink On YARN
 本文主要介绍了部署 Flink Application 到 YARN 集群的实践步骤。
本文主要介绍了部署 Flink Application 到 YARN 集群的实践步骤。

0. 环境准备
本实验基于以下 8 台测试机器进行:
| IP | hostname |
|---|---|
| 10.4.79.90 | hadoop-1 |
| 10.4.79.8 | hadoop-2 |
| 10.4.79.6 | hadoop-3 |
| 10.4.79.58 | hadoop-4 |
| 10.4.79.38 | hadoop-5 |
| 10.4.79.96 | hadoop-6 |
| 10.4.79.62 | hadoop-7 |
| 10.4.79.92 | hadoop-8 |
首先确认每个机器都安装了如下软件:
- JAVA >= 1.8.x
- SSH,并确保所有集群节点之间可互相 SSH免密登录
为集群每个节点配置 hostname:vi /etc/hosts
10.4.79.90 hadoop-1
10.4.79.8 hadoop-2
10.4.79.6 hadoop-3
10.4.79.58 hadoop-4
10.4.79.38 hadoop-5
10.4.79.96 hadoop-6
10.4.79.62 hadoop-7
10.4.79.92 hadoop-8
YARN 环境搭建可参考 hadoop 环境搭建
1. Flink 任务提交到 YARN
1.1 准备
a. 测试 Yarn 环境是否已经准备好接受一个 Flink Application 了: yarn top

b. 下载 Flink 并解压缩
c. 系统环境添加配置项:
export HADOOP_CLASSPATH=`hadoop classpath`
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
1.2 以 Application 模式提交任务
./bin/flink run-application -t yarn-application ./examples/streaming/TopSpeedWindowing.jar
启动成功后,会返回一个 JobID,如下图所示:
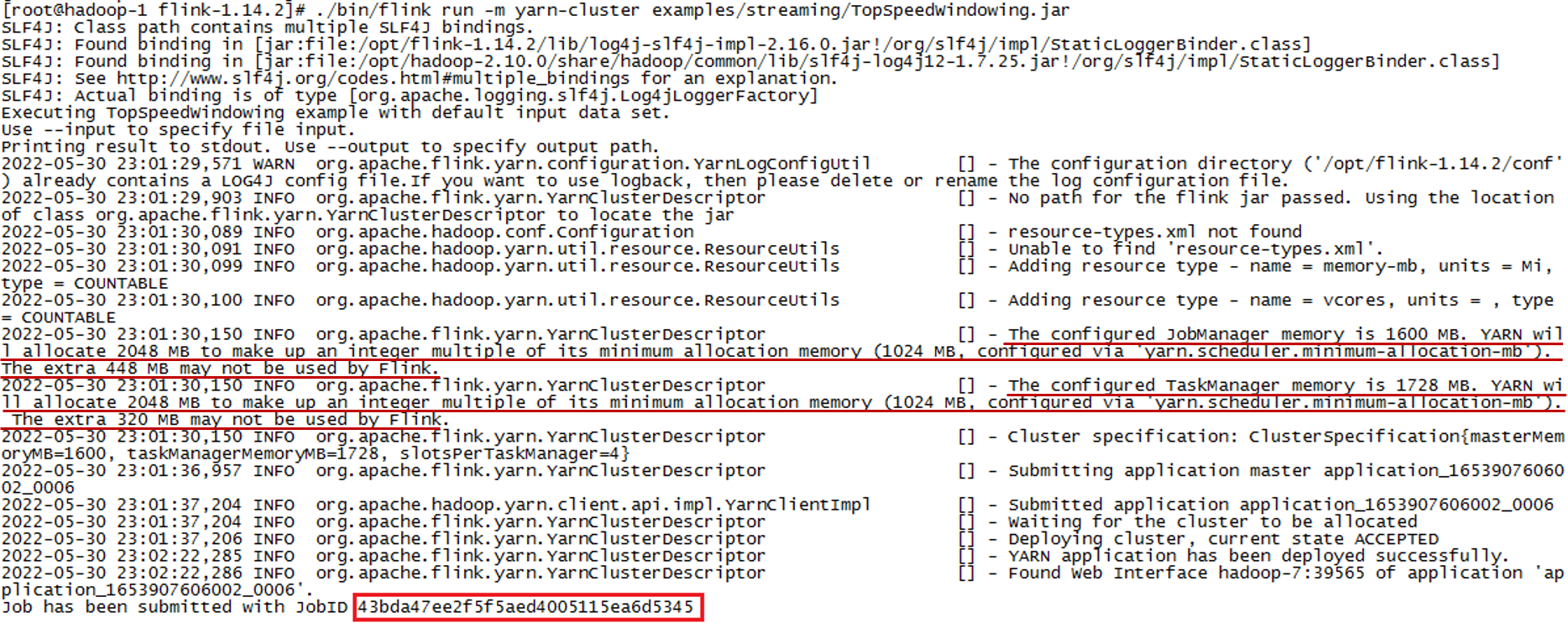
启动日志中有一部分关键信息:
The configured JobManager memory is 1600 MB. YARN will allocate 2048 MB to make up an integer multiple of its minimum allocation memory (1024 MB, configured via
yarn.scheduler.minimum-allocation-mb). The extra 448 MB may not be used by Flink.
The configured TaskManager memory is 1728 MB. YARN will allocate 2048 MB to make up an integer multiple of its minimum allocation memory (1024 MB, configured viayarn.scheduler.minimum-allocation-mb). The extra 320 MB may not be used by Flink.
因为我们前文在 yarn-site.xml 中配置 yarn 的每个任务最小内存分配单元(yarn.scheduler.minimum-allocation-mb)是 1024MB,而我们在 Flink/conf/flink-conf.yaml 中配置的 jobmanager 内存使用大小(jobmanager.memory.process.size:)是 1600m,所以 yarn 会分配给 jobmanager 共计 2x1024=2048MB,Flink 只使用了其中的 1600MB,剩余 448MB,这些空间就浪费了。
同理,taskmanager 的内存大小配置是 1728MB,yarn 会分配给 taskmanager 共计 2x1024=2048MB,Flink 只使用了其中的 1728MB,剩余的 320MB 空间就浪费了。
因此我们将 Flink 的 JobManager (jobmanager.memory.process.size) 和 TaskManager (taskmanager.memory.process.size) 大小都配置为 2048M。
重新提交任务,启动成功后,可以在 yarn 管理页面看到正在运行的 Application:
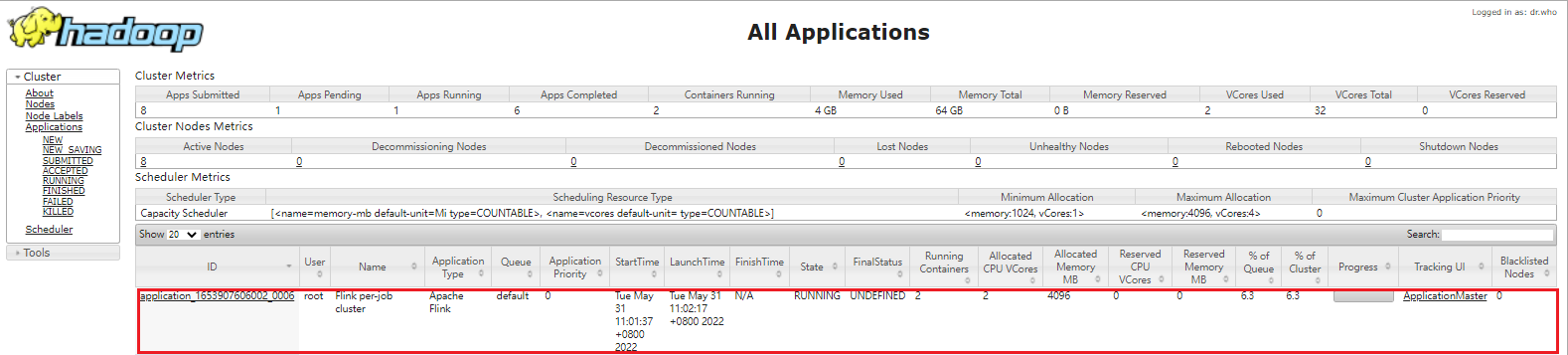
点击任务 ID 跳转至任务详情页:
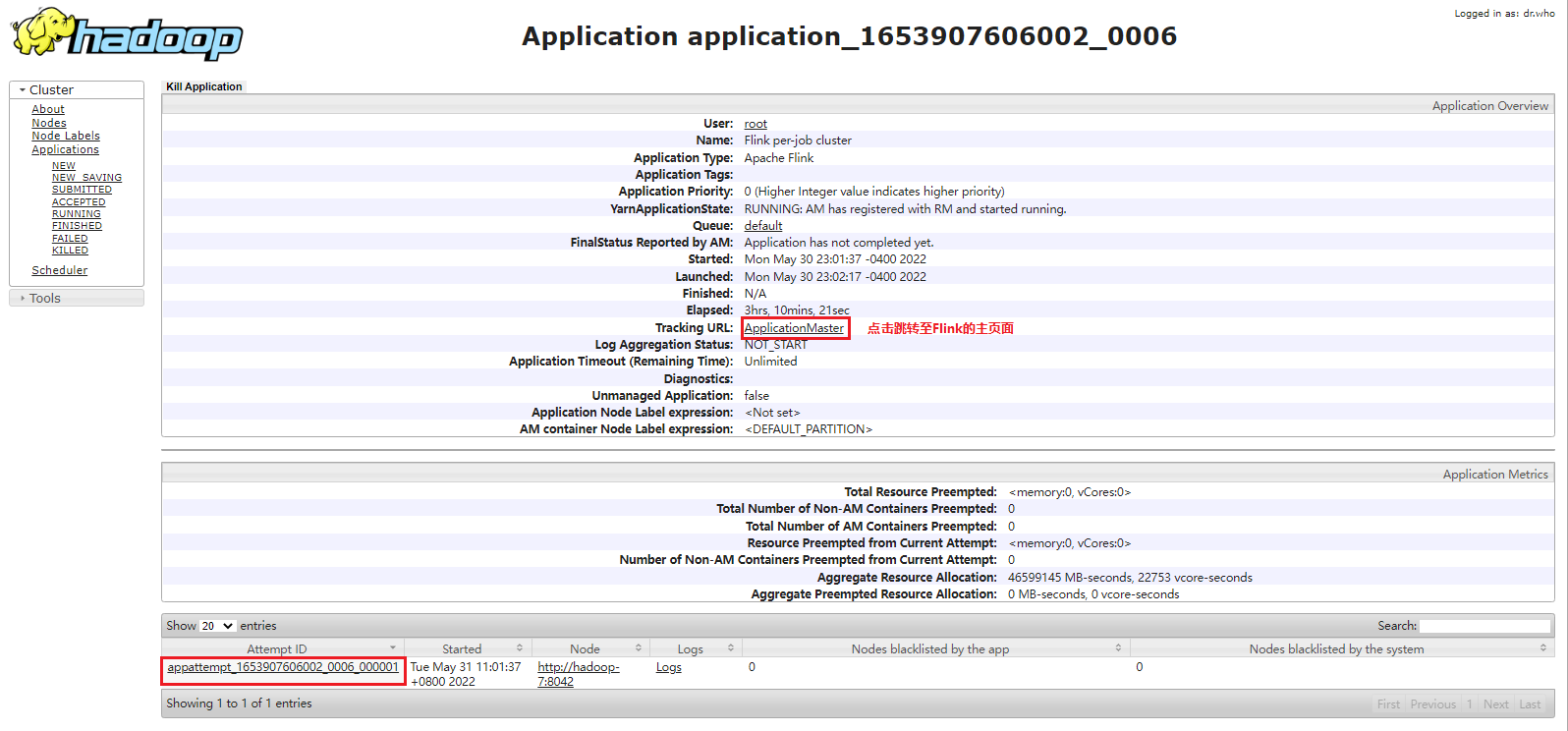
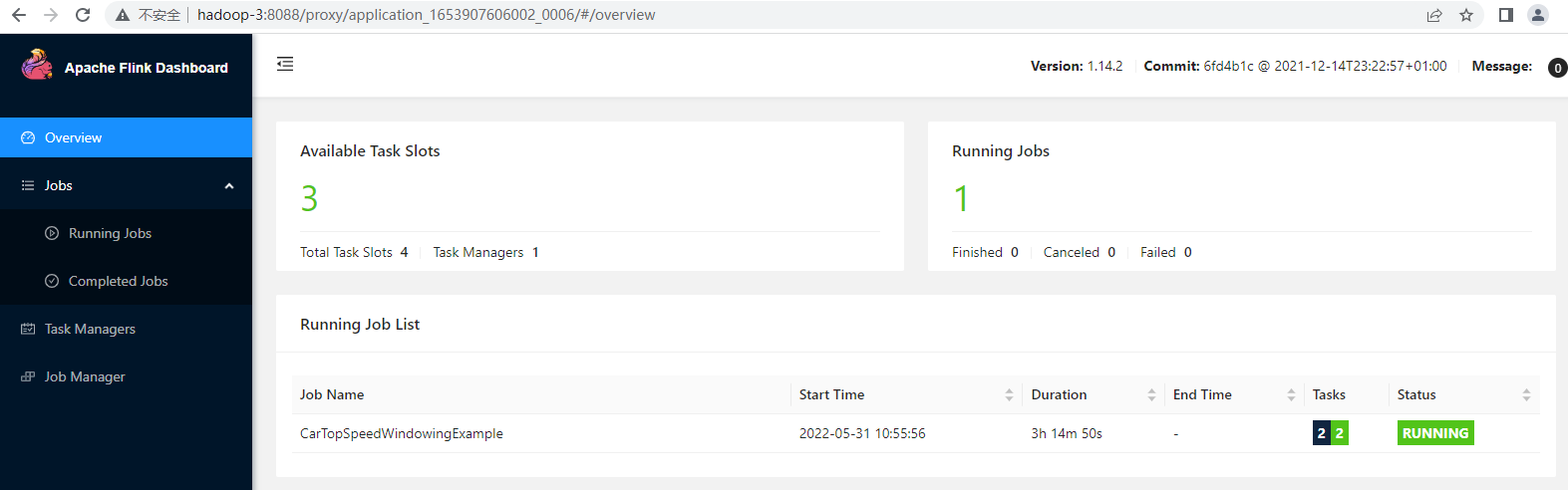
点击 ApplicationMaster 就跳转到了我们熟悉的 Flink 管理页面:
点击 AttempID 可以查看任务具体运行在哪个节点:
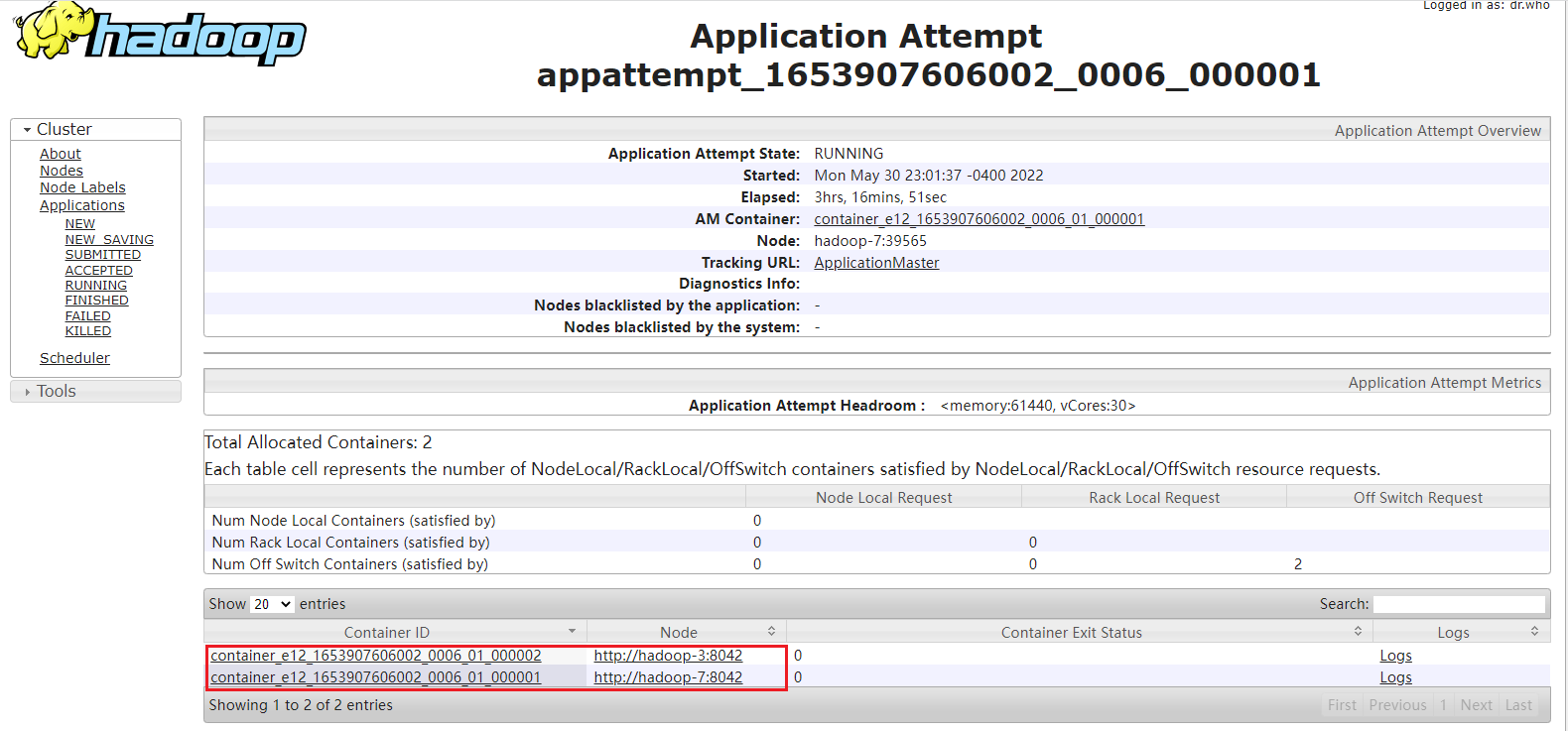
可以看到刚刚提交的 Flink 任务占用了两个 Yarn Container,分别在 hadoop-3 和 hadoop-7,一个 Container 用于运行 JobManager,一个 Container 用于运行 TaskManager。
1.3 日志查看
登陆到 hadoop-3 查看后台日志:
cd /opt/hadoop-2.10.0/logs/userlogs/{applicationid}/{containerid}

可以看出 hadoop-3 是一个 TaskManager。
登陆到 hadoop-7 查看后台日志:
cd /opt/hadoop-2.10.0/logs/userlogs/{applicationid}/{containerid}

可以看出 hadoop-7 是一个 JobManager。
1.4 日志归档
在 flink/conf 目录下已经提供了 log4j.properties 和 logback.xml,说明可以 log4j 和 logback 两种方案任选其一。
如果选择 logback 方案,需要移除(重命名)log4j.properties。
另外 官方文档 中还特别提示:
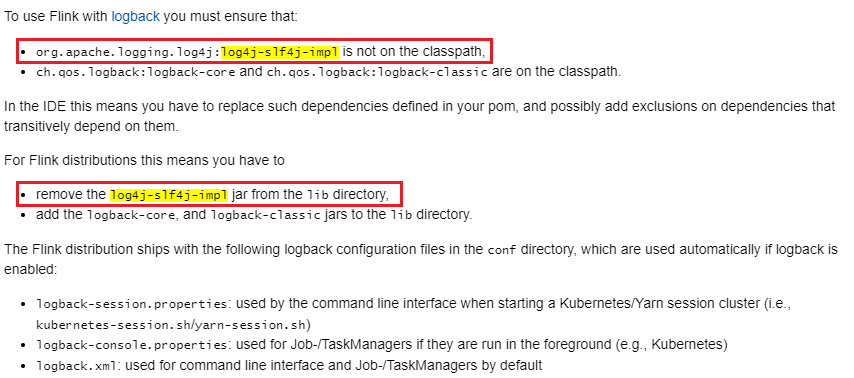
就是说对于 flink on yarn 模式,日志的归档策略并不依赖 yarn 的配置,而是 flink 的配置:
flink on yarn 的日志滚动策略配置 flink/conf/logback.xml:
<configuration>
<appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.file}</file>
<append>false</append>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!-- 日志按天滚动 -->
<fileNamePattern>${log.file}_%d{yyyy-MM-dd}.%i</fileNamePattern>
<!-- 每个文件最大100MB, 保留7天的历史日志, 最多保留2GB -->
<maxFileSize>100MB</maxFileSize>
<maxHistory>7</maxHistory>
<totalSizeCap>2GB</totalSizeCap>
</rollingPolicy>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{60} %X{sourceThread} - %msg%n</pattern>
</encoder>
</appender>
<!-- This affects logging for both user code and Flink -->
<root level="INFO">
<appender-ref ref="file"/>
</root>
<logger name="akka" level="INFO">
<appender-ref ref="file"/>
</logger>
<logger name="org.apache.kafka" level="INFO">
<appender-ref ref="file"/>
</logger>
<logger name="org.apache.hadoop" level="INFO">
<appender-ref ref="file"/>
</logger>
<logger name="org.apache.zookeeper" level="INFO">
<appender-ref ref="file"/>
</logger>
<!-- Suppress the irrelevant (wrong) warnings from the Netty channel handler -->
<logger name="org.jboss.netty.channel.DefaultChannelPipeline" level="ERROR">
<appender-ref ref="file"/>
</logger>
</configuration>
1.5 遇到的问题
a. 启动任务报错:
Trying to access closed classloader. Please check if you store classloaders directly or indirectly in static fields. If the stacktrace suggests that the leak occurs in a third party library and cannot be fixed immediately, you can disable this check with the configuration 'classloader.check-leaked-classloader'.
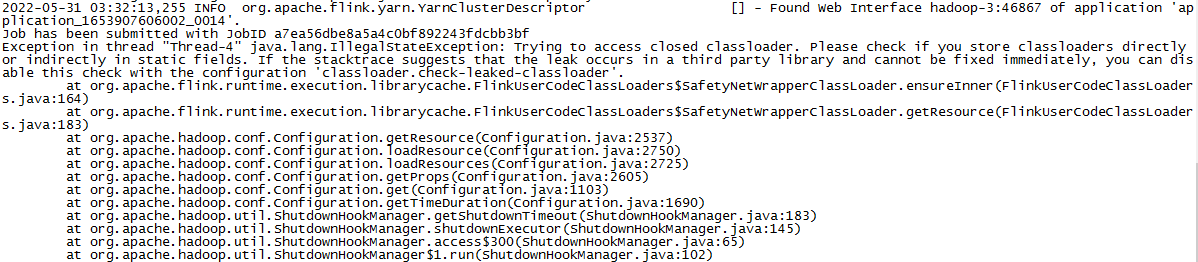
解决办法: 在 flink 配置文件 flink-conf.yaml 设置禁用 classloader.check-leaked-classloader
classloader.check-leaked-classloader: false
b. Flink 消费 kafka 数据源,提交新任务可以成功,但是状态在 RUNNING 持续几秒钟后即转变为 FAILED.
查看错误日志:
Caused by: java.lang.ClassCastException: cannot assign instance of org.apache.kafka.clients.consumer.OffsetResetStrategy to field org.apache.flink.connector.kafka.source.enumerator.initializer.ReaderHandledOffsetsInitializer.offsetResetStrategy of type org.apache.kafka.clients.consumer.OffsetResetStrategy in instance of org.apache.flink.connector.kafka.source.enumerator.initializer.ReaderHandledOffsetsInitializer
at java.io.ObjectStreamClass$FieldReflector.setObjFieldValues(ObjectStreamClass.java:2302)
at java.io.ObjectStreamClass.setObjFieldValues(ObjectStreamClass.java:1432)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2409)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2327)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2185)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1665)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2403)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2327)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2185)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1665)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2403)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2327)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2185)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1665)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:501)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:459)
at org.apache.flink.util.InstantiationUtil.deserializeObject(InstantiationUtil.java:617)
at org.apache.flink.util.InstantiationUtil.deserializeObject(InstantiationUtil.java:602)
at org.apache.flink.util.InstantiationUtil.deserializeObject(InstantiationUtil.java:589)
at org.apache.flink.util.SerializedValue.deserializeValue(SerializedValue.java:67)
at org.apache.flink.runtime.operators.coordination.OperatorCoordinatorHolder.create(OperatorCoordinatorHolder.java:431)
at org.apache.flink.runtime.executiongraph.ExecutionJobVertex.<init>(ExecutionJobVertex.java:211)
... 17 common frames omitted
大概意思是: org.apache.kafka.clients.consumer.OffsetResetStrategy 字段赋值给
org.apache.flink.connector.kafka.source.enumerator.initializer.ReaderHandledOffsetsInitializer.offsetResetStrategy 失败
看起来像是 kafka-clients 和 flink-connector-kafka 之间类型转换有误,目测是 flink-clients 和 flink-connector-kafka 版本兼容性或依赖冲突问题,在 flink-conf.yaml 中添加配置项解决依赖冲突:
classloader.resolve-order: parent-first
重新提交,成功!
c. 无法提交新任务,状态一直处于 ACCEPTED:
Deployment took more than 60 seconds. Please check if the requested resources are available in the YARN cluster
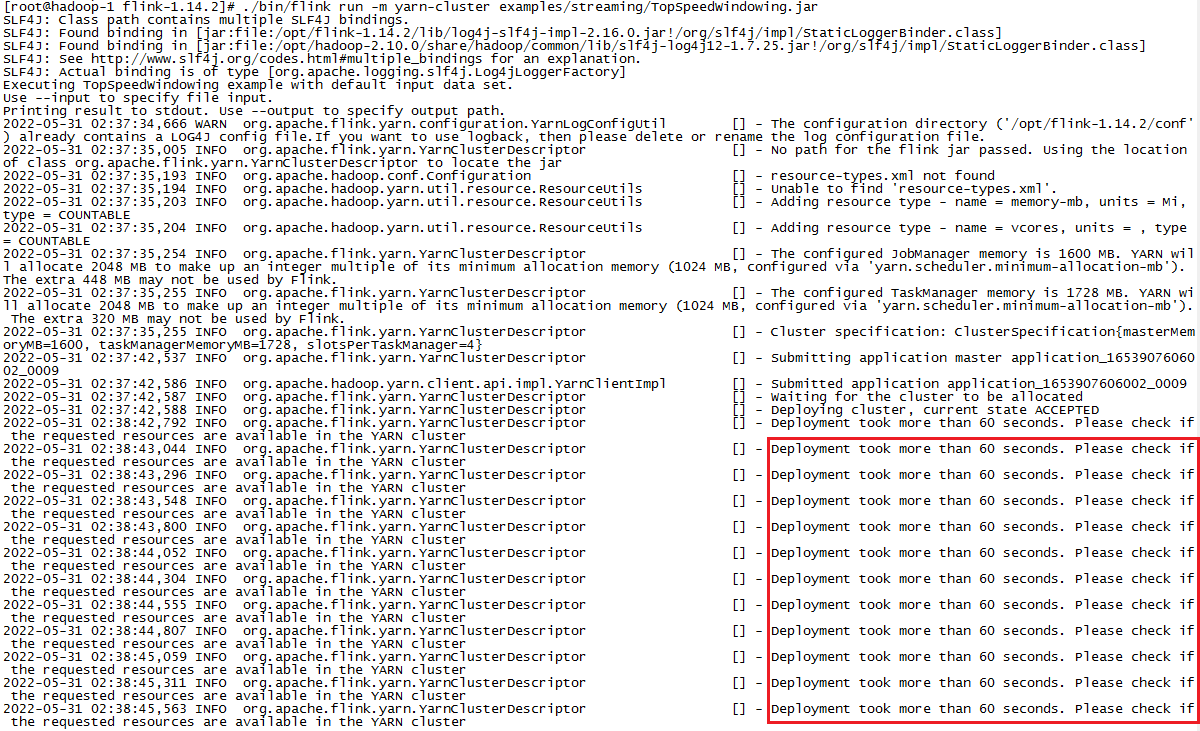
似乎是资源不够用了。
-
查看 CPU 和内存资源占用情况
Total Resources Used Resources <memory:64 GB, vCores:32> <memory:4 GB, vCores:2> CPU 和内存资源是充足的。
-
查看调度器的使用情况
可以看到,集群中使用的是
Capacity Scheduler调度器,也就是所谓的容量调度,这种方案更适合多租户安全地共享大型集群,以便在分配的容量限制下及时分配资源。采用队列的概念,任务提交到队列,队列可以设置资源的占比,并且支持层级队列、访问控制、用户限制、预定等等配置。但是,对于资源的分配占比调优需要更多的经验处理。但它不会出现在使用 FIFO Scheduler 时会出现的有大任务独占资源,会导致其他任务一直处于 pending 状态的问题。 -
查看任务队列的使用情况

从上图中可以看出用户队列没有做租户划分,用的都是 default 队列,从图中可以看出使用的容量也只有 6.3%,队列中最多可存放 10000 个 application,而实际的远远少于 10000,貎似这里也看不出来什么问题。
但是有一处限制需要特别注意:
Configured Max Application Master Limit,这是集群中可用于运行 application master 的资源比例上限,通常用于限制并发运行的应用程序数目,默认值为 10%。每个 Flink Application 拥有一个 JobManager,每个 JobManager 分配 2GB 内存,集群中共有 64GB 内存,64 x 0.1 = 6.4GB,因此最多可以提交 3 个 Flink Application,提交第 4 个的时候会超过资源限制无法提交!
-
解决验证
修改
hadoop/etc/hadoop/capacity-scheduler.xml:<property> <name>yarn.scheduler.capacity.maximum-am-resource-percent</name> <value>0.5</value> </property>按照这个配置,最多可以运行 64GB x 0.5 / 2GB = 16 个 Flink Application。
修改完成后,刷新一下 yarn 队列:
yarn rmadmin -refreshQueues继续提交任务,成功!
d. Flink 消费 Kerberos 认证的 Kafka:
错误日志:
org.apache.kafka.common.KafkaException: Failed to construct kafka consumer
at org.apache.kafka.clients.consumer.KafkaConsumer.<init>(KafkaConsumer.java:820)
at org.apache.kafka.clients.consumer.KafkaConsumer.<init>(KafkaConsumer.java:666)
at org.apache.kafka.clients.consumer.KafkaConsumer.<init>(KafkaConsumer.java:646)
at org.apache.flink.connector.kafka.source.reader.KafkaPartitionSplitReader.<init>(KafkaPartitionSplitReader.java:96)
at org.apache.flink.connector.kafka.source.KafkaSource.lambda$createReader$1(KafkaSource.java:153)
at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcherManager.createSplitFetcher(SplitFetcherManager.java:161)
at org.apache.flink.connector.base.source.reader.fetcher.SingleThreadFetcherManager.addSplits(SingleThreadFetcherManager.java:84)
at org.apache.flink.connector.base.source.reader.SourceReaderBase.addSplits(SourceReaderBase.java:242)
at org.apache.flink.streaming.api.operators.SourceOperator.handleOperatorEvent(SourceOperator.java:428)
at org.apache.flink.streaming.runtime.tasks.OperatorEventDispatcherImpl.dispatchEventToHandlers(OperatorEventDispatcherImpl.java:70)
at org.apache.flink.streaming.runtime.tasks.RegularOperatorChain.dispatchOperatorEvent(RegularOperatorChain.java:83)
at org.apache.flink.streaming.runtime.tasks.StreamTask.lambda$dispatchOperatorEvent$19(StreamTask.java:1473)
at org.apache.flink.streaming.runtime.tasks.StreamTaskActionExecutor$1.runThrowing(StreamTaskActionExecutor.java:50)
at org.apache.flink.streaming.runtime.tasks.mailbox.Mail.run(Mail.java:90)
at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.processMailsWhenDefaultActionUnavailable(MailboxProcessor.java:338)
at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.processMail(MailboxProcessor.java:324)
at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:201)
at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:809)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:761)
at org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:958)
at org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:937)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:766)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:575)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.kafka.common.KafkaException: javax.security.auth.login.LoginException: Checksum failed
at org.apache.kafka.common.network.SaslChannelBuilder.configure(SaslChannelBuilder.java:158)
at org.apache.kafka.common.network.ChannelBuilders.create(ChannelBuilders.java:146)
at org.apache.kafka.common.network.ChannelBuilders.clientChannelBuilder(ChannelBuilders.java:67)
at org.apache.kafka.clients.ClientUtils.createChannelBuilder(ClientUtils.java:99)
at org.apache.kafka.clients.consumer.KafkaConsumer.<init>(KafkaConsumer.java:741)
... 23 more
Caused by: javax.security.auth.login.LoginException: Checksum failed
at com.sun.security.auth.module.Krb5LoginModule.attemptAuthentication(Krb5LoginModule.java:808)
at com.sun.security.auth.module.Krb5LoginModule.login(Krb5LoginModule.java:617)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at javax.security.auth.login.LoginContext.invoke(LoginContext.java:755)
at javax.security.auth.login.LoginContext.access$000(LoginContext.java:195)
at javax.security.auth.login.LoginContext$4.run(LoginContext.java:682)
at javax.security.auth.login.LoginContext$4.run(LoginContext.java:680)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.login.LoginContext.invokePriv(LoginContext.java:680)
at javax.security.auth.login.LoginContext.login(LoginContext.java:587)
at org.apache.kafka.common.security.authenticator.AbstractLogin.login(AbstractLogin.java:60)
at org.apache.kafka.common.security.kerberos.KerberosLogin.login(KerberosLogin.java:103)
at org.apache.kafka.common.security.authenticator.LoginManager.<init>(LoginManager.java:62)
at org.apache.kafka.common.security.authenticator.LoginManager.acquireLoginManager(LoginManager.java:112)
at org.apache.kafka.common.network.SaslChannelBuilder.configure(SaslChannelBuilder.java:147)
... 27 more
Caused by: KrbException: Checksum failed
at sun.security.krb5.internal.crypto.Aes256CtsHmacSha1EType.decrypt(Aes256CtsHmacSha1EType.java:102)
at sun.security.krb5.internal.crypto.Aes256CtsHmacSha1EType.decrypt(Aes256CtsHmacSha1EType.java:94)
at sun.security.krb5.EncryptedData.decrypt(EncryptedData.java:175)
at sun.security.krb5.KrbAsRep.decrypt(KrbAsRep.java:150)
at sun.security.krb5.KrbAsRep.decryptUsingKeyTab(KrbAsRep.java:121)
at sun.security.krb5.KrbAsReqBuilder.resolve(KrbAsReqBuilder.java:300)
at sun.security.krb5.KrbAsReqBuilder.action(KrbAsReqBuilder.java:488)
at com.sun.security.auth.module.Krb5LoginModule.attemptAuthentication(Krb5LoginModule.java:780)
... 44 more
Caused by: java.security.GeneralSecurityException: Checksum failed
at sun.security.krb5.internal.crypto.dk.AesDkCrypto.decryptCTS(AesDkCrypto.java:451)
at sun.security.krb5.internal.crypto.dk.AesDkCrypto.decrypt(AesDkCrypto.java:272)
at sun.security.krb5.internal.crypto.Aes256.decrypt(Aes256.java:76)
at sun.security.krb5.internal.crypto.Aes256CtsHmacSha1EType.decrypt(Aes256CtsHmacSha1EType.java:100)
... 51 more
flink 消费 Kerberos 认证的 kafka,除了 kafka.props 的基本设置项:
props.put("sasl.mechanism", "GSSAPI");
props.put("security.protocol", "SASL_PLAINTEXT");
props.put("sasl.kerberos.service.name", "kafka-server");
还要做到以下几点:
-
将
kafka-client.keytab,krb5.conf,kafka-client-jaas.conf3 个配置文件放到 yarn 集群中每个节点的同一路径下。 -
修改
conf/flink-conf.yaml:security.kerberos.loginuse-ticket-cache: false security.kerberos.login.keytab: /opt/flink-1.14.2/conf/kafka-client.keytab security.kerberos.login.principal: kafka-client@ABC.COM security.kerberos.login.contexts: Client,KafkaClient env.java.opts: -Djava.security.krb5.conf=/opt/flink-1.14.2/conf/krb5.conf -Djava.security.auth.login.config=/opt/flink-1.14.2/conf/kafka-client-jaas.conf最关键的是这个配置
env.java.opts,在 Flink on yarn 模式下,这个配置项似乎并不能被下面的代码取代:System.setProperty("java.security.auth.login.config", "/path/to/kafka-client-jaas.conf"); System.setProperty("java.security.krb5.conf", "/path/to/krb5.conf");


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律