Flink 实战之从 Kafka 到 ES
 Flink 实战之从 Kafka 到 ES
Flink 实战之从 Kafka 到 ES

- Flink 实战之从 Kafka 到 ES
- Flink 实战之 Real-Time DateHistogram
做个数据搬运工
本例的场景非常常见:消费 Kafka 的数据写入到 ES。Kafka 是常见的 Source,ElasticSearch 是常见的 Sink。
Kafka 中的数据格式如下,为简化程序,测试数据做了尽可能的精简:
{
"gid" : "001254500828905",
"timestamp" : 1620981709790
}
版本说明:
| 组件 | 版本 |
|---|---|
Flink |
1.17.2 |
Kafka-Source-Connector |
1.17.2 |
ES-Sink-Connector |
3.0.1-1.17 |
ElasticSearch |
7.8.1 |
Kafka |
2.1.0 |
Maven pom.xml
<properties>
<flink.version>1.17.2</flink.version>
<flink.connector-es-version>3.0.1-1.17</flink.connector-es-version>
<gson.version>2.10.1</gson.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch7</artifactId>
<version>${flink.connector-es-version}</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>${gson.version}</version>
</dependency>
</dependencies>
实现:
package org.example.flink.data;
public class Trace {
private String gid;
private long timestamp;
// 省略Getter, Setter
}
package org.example.flink;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.elasticsearch.sink.Elasticsearch7SinkBuilder;
import org.apache.flink.connector.elasticsearch.sink.FlushBackoffType;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.contrib.streaming.state.EmbeddedRocksDBStateBackend;
import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.Requests;
import org.elasticsearch.common.xcontent.XContentType;
import org.example.flink.data.Trace;
import com.google.gson.Gson;
public class FromKafkaToEs {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
configuration.setString("rest.port", "9091");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
// 一定要开启checkpoint,只有开启了checkpoint才能保证一致性语义
env.enableCheckpointing(2 * 60 * 1000);
// 使用rocksDB作为状态后端
env.setStateBackend(new EmbeddedRocksDBStateBackend());
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("127.0.0.1:9092")
.setTopics("trace-2024")
.setGroupId("group-01")
.setStartingOffsets(OffsetsInitializer.committedOffsets())
.setProperty("commit.offsets.on.checkpoint", "true")
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> sourceStream = env.fromSource(source, WatermarkStrategy.noWatermarks(),
"Kafka Source");
sourceStream.setParallelism(2); // 设置source算子的并行度为2
SingleOutputStreamOperator<Trace> mapStream = sourceStream.map(new MapFunction<String, Trace>() {
private static final long serialVersionUID = 1L;
@Override
public Trace map(String value) throws Exception {
Gson gson = new Gson();
Trace trace = gson.fromJson(value, Trace.class);
return trace;
}
});
mapStream.setParallelism(1); // 设置map算子的并行度为1
DataStreamSink<Trace> sinkStream = mapStream.sinkTo(
new Elasticsearch7SinkBuilder<Trace>()
.setHosts(new HttpHost("127.0.0.1", 9200, "http"))
.setEmitter(
(element, context, indexer) -> {
IndexRequest indexRequest = Requests.indexRequest()
.index("trace-index")
.source(element.toString(), XContentType.JSON);
indexer.add(indexRequest);
}
)
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
// This enables an exponential backoff retry mechanism,
// with a maximum of 5 retries and an initial delay of 1000 milliseconds
.setBulkFlushBackoffStrategy(FlushBackoffType.CONSTANT, 5, 1000)
.build());
sinkStream.setParallelism(2); // 设置sink算子的并行度为2
// 执行
env.execute("From-Kafka-To-ElasticSearch");
}
}
由于我们引入了 flink-runtime-web,程序启动后,可以在控制台看到 Flink Web 的 endpoint,可以在浏览器中查看任务的运行时状态:

我们设置了 Source 算子的并行度为 2,Map 算子的并行度为 1,Sink 算子的并行度为 2,Job Graph 以及数据在各算子之间的流动状态如下图所示:

数据在 Kafka 中以序列化的方式存储,经由 Map 算子转换为 Object 结构,然后写入 ES 中存储为 doc 格式。
几个关键点
Kafka Source Idleness
如果 Source 算子的并行度 > Kafka Topic 分区数量,意味着会有 Source 算子消费不到数据,在早期版本的 Kafka Source Connector 中,如果 Source 算子的并行度设置不当,会消费不到数据的现象,因为有数据的 Source 算子一直在等待没有数据的 Source 算子的 watermark(目的是取所有算子的 watermark 的最小值作为 Job 的 watermark),但是没有数据对接的那个 Source 算子的 watermark 被初始成了 -1,就导致作业的 watermark 永远不会 advance。解决办法是设置 Source 算子的并行度一定要 ≤ Kafka Topic 分区数量。
本版本中的 Kafka Source Connector 新增了空闲检测的功能,如果某个 Source 算子一段时间内没有数据流动,会被识别为 idle 状态,不会再 hold back 整个作业 watermark 的进度。
Kafka Offset Commiting
Kafka 消费偏移量的提交方式是非常重要的配置。当开启 Checkpoint 时,Kafka 偏移量默认会在 Checkpoint 成功保存 后提交到 Kafka,这样做的目的是为了保证 Flink Checkpoint 中的 State(记录的就是 Kafka 的 offset)和 Kafka broker 中记录的 offset 的一致性。
如果不开启 Checkpoint,Kafka Source 算子就依赖其内部的 kafka consumer 的自动提交逻辑来管理消费偏移量了。这可以通过配置 consumer 的 properties 来实现,具体的配置项是: enable.auto.commit 和 auto.commit.interval.ms。
一致性测试
Flink 的 Kafka Source Connector 可以做到 Exactly-Once 保障,即保证每条数据精确消费一次,ES Sink Connector 可以做到 AtLeast-Once 保障,即至少写入一次。真的是这样吗?我们做个实验:
启动程序后,向 Kafka 生产 10, 000 条数据,可以看到 ES 中索引的数据量也是 10, 000;

停止 ES 服务:
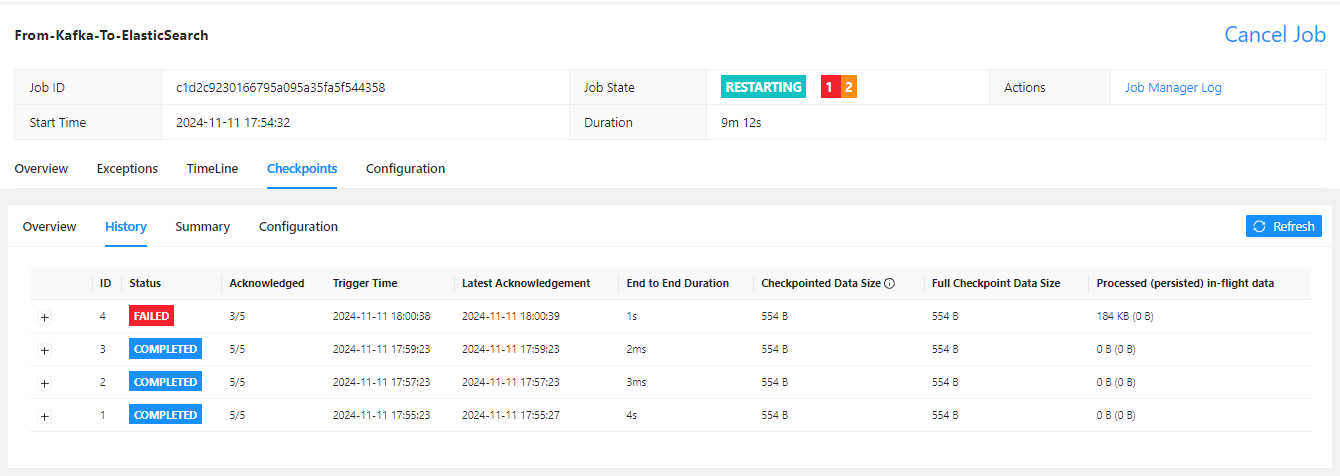
继续向 Kafka 中写入 10,000 条数据,观察 Flink 任务的运行状态,此时 Flink 任务状态是 Restarting,因为 es 写入失败触发了 Flink 的重启策略:
半小时后,重新启动 ES 服务;
Flink 在重启过程中,发现 es 状态恢复正常,尝试从 Kafka 的 committed offset 消费数据,成功将 es 停机期间的 10,000 条数据补到了索引中:

如果 Flink 在运行过程中出现故障重启,将尝试从上一个 checkpoint 中进行恢复,本例中将会从上一个 checkpoint 记录的 offset 开始消费数据,因此这部分数据可能在目标端出现重复写入:

图解原理
通过上面的实验可以看到,ES 的宕机没有对数据一致性造成任何影响,在服务恢复后数据仍然一条不差,Flink 确实太强大、太健壮了!Flink 是如何做到一致性保障的呢?
秘密都在 Checkpoint 中,Checkpoint 是 Flink 实现容错机制的核心功能之一,它确保了在分布式系统中,即使发生故障(如节点宕机、网络分区等),作业也能够从上次成功处理的状态继续运行,而不会丢失数据或重复处理,无需人工干预,在生产环境中强烈推荐开启。
Flink 的 Kafka Source Connector 是一个有状态的算子(operator),它集成了 Flink 的检查点机制,它的状态是所有 Kafka 分区的读取偏移量。当一个检查点被触发时,每一个分区的偏移量都被存到了这个检查点中。当一个 Job 的所有算子都成功存储了自己的状态,一个检查点才算完成。检查点的完成代表这个检查点之前的所有数据都完成了端到端的一致性传输,本例中代表从 Kafka 消费到的数据都已经成功落入到了 ES 中。因此,当系统从故障中恢复时,只要从上一个成功保存的检查点处恢复,就可以做到端到端的一致性语义保障。
我用图解的方式详细介绍 Flink 是如何管理 Kafka 消费位点的:
第 1 步
如下图所示,一个 Kafka topic 有两个 partition,每个 Kafka Source 算子负责一个 partition 数据的消费。Kafka Source 算子是一个有状态算子,状态中保存的是各自分区的消费偏移量。在初始时刻,消费偏移量是 0。

第 2 步
Flink 的 JobManager 会定时向数据流中注入 Checkpoint barrier,作为 checkpoint 的界限。Checkpoint barrier 跟随数据在算子链中流动,每到达一个算子都会触发将状态快照写入状态后端的动作。

第 3 步
Kafka Source 算子开始消费数据,并在算子的状态中记录各自分区的消费偏移量,图示时刻 Kafka-Source-1 算子的 Offset = 2,Kafka-Source-2 算子的 Offset = 1。注意此时的状态仍保存在内存中,并没有持久化。
图中所示的这个状态还有一个关键之处,就是此刻 Kafka-Source-1 算子收到了 Checkpoint barrier,开启了 Begin alignment,Kafka-Source-1 算子将暂停消费数据,等待其他的 Kafka-Source 算子收到相同的 Checkpoint barrier。

第 4 步
Kafka-Source-2 也收到了 Checkpoint barrier,所有算子都收到了同一版本的 Checkpoint barrier 后,标志着 End alignment。此时 Kafka-Source-1 算子的 Offset = 2,Kafka-Source-2 算子的 Offset = 4。

第 5 步
Checkpoint 的 End alignment 会触发算子状态保存到状态后端的动作,此时 Kafka-Source 算子将状态 { offset1 = 2, offset2 = 4 } 持久化保存到 State backend。只有当所有算子的状态都成功保存到 State backend,一个 Checkpoint 才算保存成功。

第 6 步
Checkpoint barrier 继续沿着算子链向下游流动,Map 算子集齐同一版本的 Checkpoint barrier 后,也将触发将状态保存到 State backend 的动作。

第 7 步
一般来说,Map 算子是无状态的,假设我们为 Map 算子添加了自定义的状态值 Count,用于统计数据流量。下图中 Map 算子的状态也已经保存到 State backend 中。以此类推,直到所有算子的状态全部保存到 State backend 中,一个 Checkpoint 才算保存成功。

故障恢复
在发生故障时(比如,某个 TaskManager 宕机了),所有的 Operator task 会被重启,而他们的状态会被重置到最近一次成功的 Checkpoint。Kafka source 分别从 offset 2 和 4 重新开始读取消息(因为这是完成的 Checkpoint 中存的 offset)。当作业重启后,我们可以期待正常的系统操作,就好像之前没有发生故障一样。如下图所示:

参考
[1] 云邪的博客:Flink 如何管理 Kafka 消费位点
[2] Flink官方文档

