Flink CDC 实时同步 Oracle
 本文主要介绍了使用 Flink CDC 实现 Oracle 到 Oracle 的数据实时同步。
本文主要介绍了使用 Flink CDC 实现 Oracle 到 Oracle 的数据实时同步。


- Flink CDC 实时同步 MySQL
- Flink CDC 实时同步 Oracle
准备工作
-
Oracle 数据库(version:
11g)-
开启归档日志
sqlplus /nolog SQL> conn /as sysdba; -- 立即关闭数据库 SQL> shutdown immediate; -- 以mount模式启动数据库 SQL> startup mount; -- 启用数据库归档日志模式 SQL> alter database archivelog; -- 打开数据库,允许用户访问 SQL> alter database open; -- 查看归档日志是否启用 SQL> archive log list;
备注:启用日志归档需要重启数据库。归档日志将占用大量的磁盘空间,因此需要定期清理过期的日志。
-
开启增量日志
sqlplus /nolog SQL> conn /as sysdba; SQL> ALTER DATABASE ADD SUPPLEMENTAL LOG DATA; -
以 DBA 权限登录数据库,赋予用户操作权限
sqlplus /nolog SQL> conn /as sysdba; -- 创建一个名为"cdc"的用户,密码为"123456" SQL> CREATE USER cdc IDENTIFIED BY 123456; -- 允许"cdc"用户创建会话,即允许该用户连接到数据库。 SQL> GRANT CREATE SESSION TO cdc; -- (不支持Oracle 11g)允许"cdc"用户在多租户数据库(CDB)中设置容器。 -- SQL> GRANT SET CONTAINER TO cdc; -- 允许"cdc"用户查询V_$DATABASE视图,该视图包含有关数据库实例的信息。 SQL> GRANT SELECT ON V_$DATABASE TO cdc; -- 允许"cdc"用户执行任何表的闪回操作。 SQL> GRANT FLASHBACK ANY TABLE TO cdc; -- 允许"cdc"用户查询任何表的数据。 SQL> GRANT SELECT ANY TABLE TO cdc; -- 允许"cdc"用户拥有SELECT_CATALOG_ROLE角色,该角色允许查询数据字典和元数据。 SQL> GRANT SELECT_CATALOG_ROLE TO cdc; -- 允许"cdc"用户拥有EXECUTE_CATALOG_ROLE角色,该角色允许执行一些数据字典中的过程和函数。 SQL> GRANT EXECUTE_CATALOG_ROLE TO cdc; -- 允许"cdc"用户查询任何事务。 SQL> GRANT SELECT ANY TRANSACTION TO cdc; -- (不支持Oracle 11g)允许"cdc"用户进行数据变更追踪(LogMiner)。 -- SQL> GRANT LOGMINING TO cdc; -- 允许"cdc"用户创建表。 SQL> GRANT CREATE TABLE TO cdc; -- 允许"cdc"用户锁定任何表。 SQL> GRANT LOCK ANY TABLE TO cdc; -- 允许"cdc"用户修改任何表。 SQL> GRANT ALTER ANY TABLE TO cdc; -- 允许"cdc"用户创建序列。 SQL> GRANT CREATE SEQUENCE TO cdc; -- 允许"cdc"用户执行DBMS_LOGMNR包中的过程。 SQL> GRANT EXECUTE ON DBMS_LOGMNR TO cdc; -- 允许"cdc"用户执行DBMS_LOGMNR_D包中的过程。 SQL> GRANT EXECUTE ON DBMS_LOGMNR_D TO cdc; -- 允许"cdc"用户查询V_$LOG视图,该视图包含有关数据库日志文件的信息。 SQL> GRANT SELECT ON V_$LOG TO cdc; -- 允许"cdc"用户查询V_$LOG_HISTORY视图,该视图包含有关数据库历史日志文件的信息。 SQL> GRANT SELECT ON V_$LOG_HISTORY TO cdc; -- 允许"cdc"用户查询V_$LOGMNR_LOGS视图,该视图包含有关LogMiner日志文件的信息。 SQL> GRANT SELECT ON V_$LOGMNR_LOGS TO cdc; -- 允许"cdc"用户查询V_$LOGMNR_CONTENTS视图,该视图包含LogMiner日志文件的内容。 SQL> GRANT SELECT ON V_$LOGMNR_CONTENTS TO cdc; -- 允许"cdc"用户查询V_$LOGMNR_PARAMETERS视图,该视图包含有关LogMiner的参数信息。 SQL> GRANT SELECT ON V_$LOGMNR_PARAMETERS TO cdc; -- 允许"cdc"用户查询V_$LOGFILE视图,该视图包含有关数据库日志文件的信息。 SQL> GRANT SELECT ON V_$LOGFILE TO cdc; -- 允许"cdc"用户查询V_$ARCHIVED_LOG视图,该视图包含已归档的数据库日志文件的信息。 SQL> GRANT SELECT ON V_$ARCHIVED_LOG TO cdc; -- 允许"cdc"用户查询V_$ARCHIVE_DEST_STATUS视图,该视图包含有关归档目标状态的信息。 SQL> GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO cdc;
-
-
Flink (version :
1.18.1),添加以下 jar 包到flink/lib:-
flink-connector-jdbc-3.2.0-1.18.jar -
flink-sql-connector-oracle-cdc-3.2-SNAPSHOT.jar -
ojdbc8-19.3.0.0.jar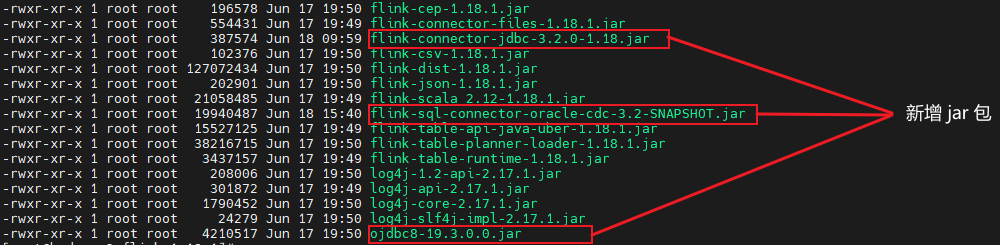
注意,这里添加的 flink-sql-connector-oracle-cdc 的版本是
3.2-SHAPSHOT, 这是我基于源码自主构建的,因为目前最新的 3.1.0 版本在同步 Oracle 时有 bug,截至版本 3.1.0 发布,尚未对此问题进行修复,但是改动已经合并到了 Master 分支,我们只能基于源码自主构建。详见 flink cdc 源码构建过程
-
-
准备待同步源端表和目标端表
源端表:
CDC_TEST.PLAYER_SOURCECREATE TABLE "CDC_TEST"."PLAYER_SOURCE" ( "ID" NUMBER(5,0) NOT NULL, "NAME" VARCHAR2(255 BYTE) ); -
准备目标端表
在目标端创建和源端同构的表:
CDC_TEST.PLAYER_TARGETCREATE TABLE "CDC_TEST"."PLAYER_TARGET" ( "ID" NUMBER(5,0) NOT NULL, "NAME" VARCHAR2(255 BYTE) );
SQL-Client 实现数据同步
使用 Flink 的 sql-client 实现数据同步
启动 Flink
./bin/start-cluster.sh
启动 sql-client
sudo ./bin/sql-client.sh
注意,这里启动 sql-client 时需要加 sudo,不然可能会报错,参见 [启动 sql-client 报错](#启动 sql-client 报错)
数据同步任务创建
-
创建源端表对应的逻辑表,参照 Oracle 字段类型和 FlinkSQL 字段类型的映射关系
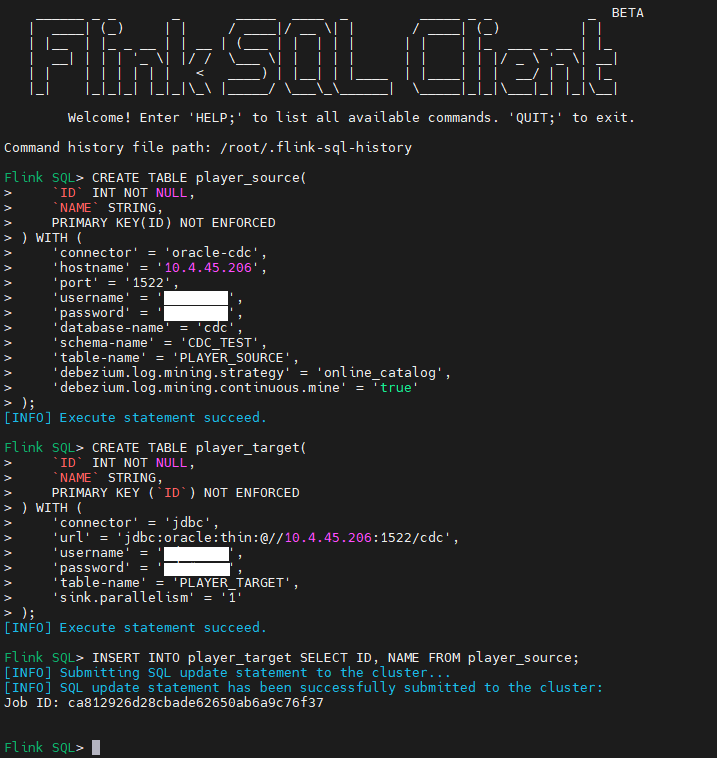
CREATE TABLE player_source( `ID` INT NOT NULL, `NAME` STRING, PRIMARY KEY(ID) NOT ENFORCED ) WITH ( 'connector' = 'oracle-cdc', 'hostname' = '127.0.0.1', 'port' = '1521', 'username' = 'username', 'password' = 'password', 'database-name' = 'cdc', 'schema-name' = 'CDC_TEST', 'table-name' = 'PLAYER_SOURCE', 'debezium.log.mining.strategy' = 'online_catalog', 'debezium.log.mining.continuous.mine' = 'true' );为了解决 Oracle 同步延迟的问题,添加了两个配置项:
'debezium.log.mining.strategy'='online_catalog', 'debezium.log.mining.continuous.mine'='true' -
创建目标端表对应的逻辑表
CREATE TABLE player_target( `ID` INT NOT NULL, `NAME` STRING, PRIMARY KEY (`ID`) NOT ENFORCED ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:oracle:thin:@//127.0.0.1:1521/cdc', 'username' = 'username', 'password' = 'password', 'table-name' = 'PLAYER_TARGET', 'sink.parallelism' = '1' ); -
建立源端逻辑表和目标端逻辑表的连接
INSERT INTO player_target SELECT ID, NAME FROM player_source; -
任务创建成功:
-
Flink Web 查看提交的任务:
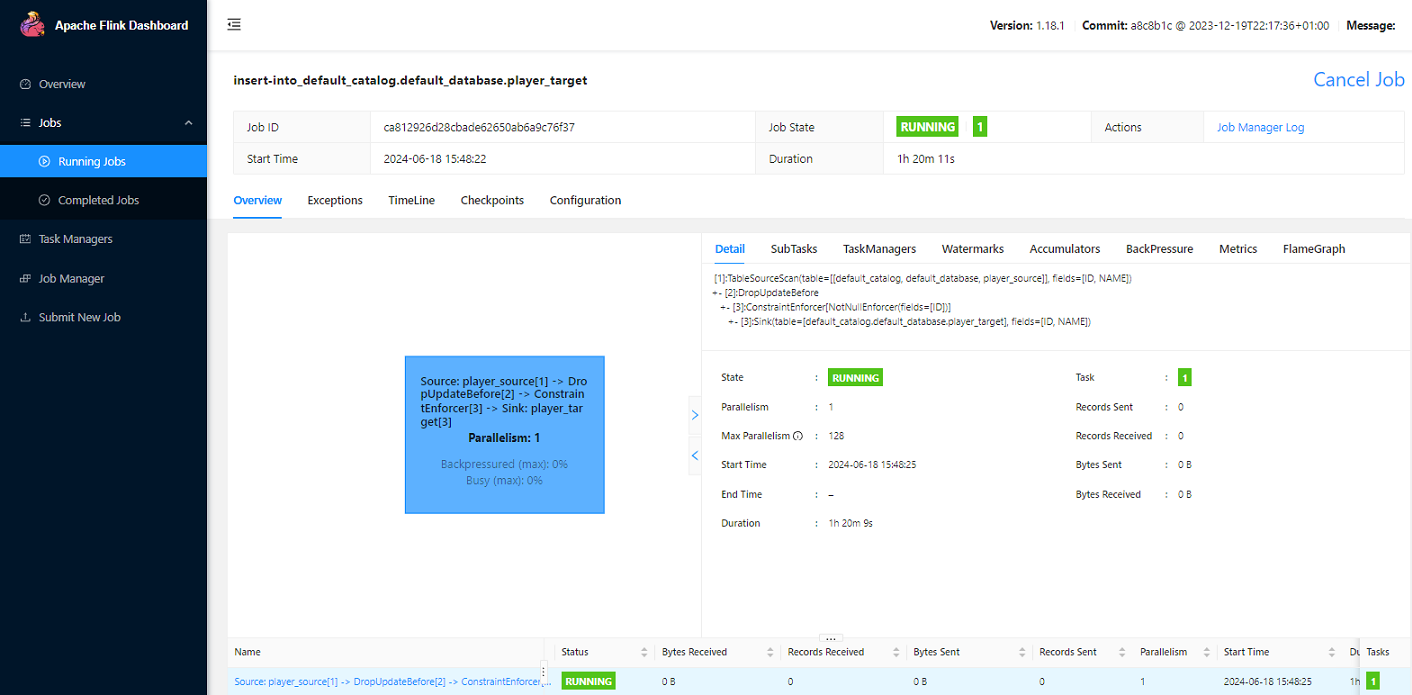
-
源端表中进行更新、删除操作,查看目标端表是否自动完成同步
TableAPI 实现数据同步
引入 maven 依赖:
<properties>
<flink.version>1.18.1</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-loader</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>3.1.2-1.18</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-oracle-cdc</artifactId>
<version>3.2-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>cn.easyproject</groupId>
<artifactId>orai18n</artifactId>
<version>12.1.0.2.0</version>
</dependency>
<dependencies>
程序实现:
package test.legacy.oracle;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.StatementSet;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class FlinkSQL {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
configuration.setInteger("rest.port", 9091);
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(configuration);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 创建源端逻辑表
String createSourceTableSQL = "CREATE TABLE player_source (" +
"`ID` INT NOT NULL, " +
"`NAME` STRING, " +
"PRIMARY KEY (`ID`) NOT ENFORCED" +
") WITH (" +
"'connector' = 'oracle-cdc', " +
"'hostname' = '127.0.0.1', " +
"'port' = '1521', " +
"'username' = 'username', " +
"'password' = 'password', " +
"'database-name' = 'cdc', " +
"'schema-name' = 'CDC_TEST', " +
"'table-name' = 'PLAYER_SOURCE', " +
"'scan.startup.mode' = 'latest-offset', " +
"'debezium.log.mining.strategy' = 'online_catalog', " +
"'debezium.log.mining.continuous.mine' = 'true'" +
");";
tableEnv.executeSql(createSourceTableSQL);
// 创建目标端逻辑表
String createSinkTableSQL = "CREATE TABLE player_target (" +
"`ID` INT NOT NULL, " +
"`NAME` STRING, " +
"PRIMARY KEY (`ID`) NOT ENFORCED" +
") WITH (" +
"'connector' = 'jdbc', " +
"'url' = 'jdbc:oracle:thin:@//127.0.0.1:1521/cdc', " +
"'username' = 'username', " +
"'password' = 'password', " +
"'table-name' = 'PLAYER_TARGET', " +
"'sink.parallelism' = '1'" +
");";
tableEnv.executeSql(createSinkTableSQL);
// 建立源端逻辑表和目标端逻辑表的连接
String insertSQL = "INSERT INTO player_target SELECT * FROM player_source;";
StatementSet statementSet = tableEnv.createStatementSet();
statementSet.addInsertSql(insertSQL);
statementSet.execute();
}
}
我们在 Configuration 中设置了 rest.port = 9091, 程序启动成功后,可以在浏览器打开 localhost:9091 看到提交运行的任务。
遇到的问题
启动 sql-client 报错
Exception in thread "main" org.apache.flink.table.client.SqlClientException: Could not read from command line.
at org.apache.flink.table.client.cli.CliClient.getAndExecuteStatements(CliClient.java:221)
at org.apache.flink.table.client.cli.CliClient.executeInteractive(CliClient.java:179)
at org.apache.flink.table.client.cli.CliClient.executeInInteractiveMode(CliClient.java:121)
at org.apache.flink.table.client.cli.CliClient.executeInInteractiveMode(CliClient.java:114)
at org.apache.flink.table.client.SqlClient.openCli(SqlClient.java:169)
at org.apache.flink.table.client.SqlClient.start(SqlClient.java:118)
at org.apache.flink.table.client.SqlClient.startClient(SqlClient.java:228)
at org.apache.flink.table.client.SqlClient.main(SqlClient.java:179)
Caused by: java.lang.NoClassDefFoundError: Could not initialize class org.apache.flink.table.client.config.SqlClientOptions
at org.apache.flink.table.client.cli.parser.SqlClientSyntaxHighlighter.highlight(SqlClientSyntaxHighlighter.java:59)
at org.jline.reader.impl.LineReaderImpl.getHighlightedBuffer(LineReaderImpl.java:3633)
at org.jline.reader.impl.LineReaderImpl.getDisplayedBufferWithPrompts(LineReaderImpl.java:3615)
at org.jline.reader.impl.LineReaderImpl.redisplay(LineReaderImpl.java:3554)
at org.jline.reader.impl.LineReaderImpl.doCleanup(LineReaderImpl.java:2340)
at org.jline.reader.impl.LineReaderImpl.cleanup(LineReaderImpl.java:2332)
at org.jline.reader.impl.LineReaderImpl.readLine(LineReaderImpl.java:626)
at org.apache.flink.table.client.cli.CliClient.getAndExecuteStatements(CliClient.java:194)
... 7 more
是权限问题,只要在启动时添加 sudo 就可以解决:
sudo ./bin/sql-client.sh
启动后还遇到报错:
Please specify JAVA_HOME. Either in Flink config ./conf/flink-conf.yaml or as system-wide JAVA_HOME.
需要在 flink-conf.yaml 中添加:
env.java.home: /opt/java-1.8.0
table or view does not exist
Caused by: java.sql.BatchUpdateException: ORA-00942: table or view does not exist
at oracle.jdbc.driver.OraclePreparedStatement.executeLargeBatch(OraclePreparedStatement.java:9711)
at oracle.jdbc.driver.T4CPreparedStatement.executeLargeBatch(T4CPreparedStatement.java:1447)
at oracle.jdbc.driver.OraclePreparedStatement.executeBatch(OraclePreparedStatement.java:9487)
at oracle.jdbc.driver.OracleStatementWrapper.executeBatch(OracleStatementWrapper.java:237)
at org.apache.flink.connector.jdbc.statement.FieldNamedPreparedStatementImpl.executeBatch(FieldNamedPreparedStatementImpl.java:65)
at org.apache.flink.connector.jdbc.internal.executor.TableSimpleStatementExecutor.executeBatch(TableSimpleStatementExecutor.java:64)
at org.apache.flink.connector.jdbc.internal.executor.TableBufferReducedStatementExecutor.executeBatch(TableBufferReducedStatementExecutor.java:98)
at org.apache.flink.connector.jdbc.internal.JdbcOutputFormat.attemptFlush(JdbcOutputFormat.java:202)
at org.apache.flink.connector.jdbc.internal.JdbcOutputFormat.flush(JdbcOutputFormat.java:172)
... 8 more
这是 Oracle 11g 对表名大小写敏感的问题。
如果 源端 表名存在小写字母,需要新增以下配置:
'debezium.database.tablename.case.insensitive' = 'true'
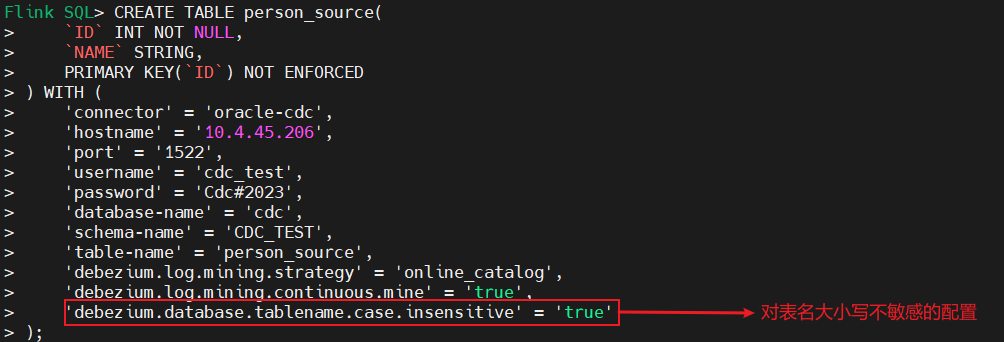
如果 目标端 表名存在小写字母,需要用双引号修正表名的大小写:
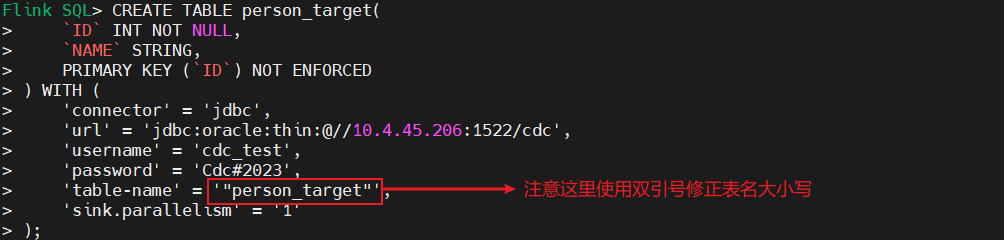
file is not a valid filed name
Caused by: com.ververica.cdc.connectors.shaded.org.apache.kafka.connect.errors.DataException: file is not a valid field name
at com.ververica.cdc.connectors.shaded.org.apache.kafka.connect.data.Struct.lookupField(Struct.java:254)
at com.ververica.cdc.connectors.shaded.org.apache.kafka.connect.data.Struct.getCheckType(Struct.java:261)
at com.ververica.cdc.connectors.shaded.org.apache.kafka.connect.data.Struct.getString(Struct.java:158)
at com.ververica.cdc.connectors.base.relational.JdbcSourceEventDispatcher$SchemaChangeEventReceiver.schemaChangeRecordValue(JdbcSourceEventDispatcher.java:193)
at com.ververica.cdc.connectors.base.relational.JdbcSourceEventDispatcher$SchemaChangeEventReceiver.schemaChangeEvent(JdbcSourceEventDispatcher.java:223)
at io.debezium.connector.oracle.OracleSchemaChangeEventEmitter.emitSchemaChangeEvent(OracleSchemaChangeEventEmitter.java:122)
at com.ververica.cdc.connectors.base.relational.JdbcSourceEventDispatcher.dispatchSchemaChangeEvent(JdbcSourceEventDispatcher.java:147)
at com.ververica.cdc.connectors.base.relational.JdbcSourceEventDispatcher.dispatchSchemaChangeEvent(JdbcSourceEventDispatcher.java:62)
at io.debezium.connector.oracle.logminer.processor.AbstractLogMinerEventProcessor.dispatchSchemaChangeEventAndGetTableForNewCapturedTable(AbstractLogMinerEventProcessor.java:1018)
at io.debezium.connector.oracle.logminer.processor.AbstractLogMinerEventProcessor.getTableForDataEvent(AbstractLogMinerEventProcessor.java:913)
at io.debezium.connector.oracle.logminer.processor.AbstractLogMinerEventProcessor.handleDataEvent(AbstractLogMinerEventProcessor.java:835)
at io.debezium.connector.oracle.logminer.processor.AbstractLogMinerEventProcessor.processRow(AbstractLogMinerEventProcessor.java:321)
at com.ververica.cdc.connectors.oracle.source.reader.fetch.EventProcessorFactory$CDCMemoryLogMinerEventProcessor.processRow(EventProcessorFactory.java:151)
at io.debezium.connector.oracle.logminer.processor.AbstractLogMinerEventProcessor.processResults(AbstractLogMinerEventProcessor.java:262)
at io.debezium.connector.oracle.logminer.processor.AbstractLogMinerEventProcessor.process(AbstractLogMinerEventProcessor.java:198)
at io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource.execute(LogMinerStreamingChangeEventSource.java:249)
... 8 more
这个是 flink-cdc 的 bug,参见 Github 关于此问题的讨论和最新进展:
https://github.com/apache/flink-cdc/pull/2315
https://github.com/apache/flink-cdc/issues/1792
截至目前,3.1 发布版本中尚未对此问题进行修复,但是改动已经合并到了 Master 分支,我们只能基于源码自主构建:
git clone https://github.com/ververica/flink-cdc-connectors.git
cd flink-cdc-connector
mvn clean install -DskipTests
打包完成后,将 flink-sql-connector-oracle-cdc-3.2-SNAPSHOT.jar 放到 flink/lib 目录下,重启 flink 和 sql-client。
Read the redoLog offset error
Caused by: org.apache.flink.util.FlinkRuntimeException: Read the redoLog offset error
at org.apache.flink.cdc.connectors.oracle.source.OracleDialect.displayCurrentOffset(OracleDialect.java:70)
at org.apache.flink.cdc.connectors.oracle.source.OracleDialect.displayCurrentOffset(OracleDialect.java:52)
at org.apache.flink.cdc.connectors.base.source.reader.external.AbstractScanFetchTask.execute(AbstractScanFetchTask.java:60)
at org.apache.flink.cdc.connectors.base.source.reader.external.IncrementalSourceScanFetcher.lambda$submitTask$1(IncrementalSourceScanFetcher.java:99)
... 3 more
Caused by: org.apache.flink.util.FlinkRuntimeException: Cannot read the redo log position via 'SELECT CURRENT_SCN FROM V$DATABASE'. Make sure your server is correctly configured
at org.apache.flink.cdc.connectors.oracle.source.utils.OracleConnectionUtils.currentRedoLogOffset(OracleConnectionUtils.java:82)
at org.apache.flink.cdc.connectors.oracle.source.OracleDialect.displayCurrentOffset(OracleDialect.java:68)
... 6 more
可能是用户权限问题,没有查看 V$DATABASE 的权限。需要 DBA 给用户赋权。
Supplemental logging not configured
Caused by: io.debezium.DebeziumException: Supplemental logging not properly configured. Use: ALTER DATABASE ADD SUPPLEMENTAL LOG DATA
at io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource.checkDatabaseAndTableState(LogMinerStreamingChangeEventSource.java:860)
at io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource.execute(LogMinerStreamingChangeEventSource.java:173)
... 7 more
提示增量日志未开启,切换至 SYS 用户,以 DBA 的权限登录数据库,为数据库启用增量日志:
sqlplus /nolog
SQL> conn /as sysdba;
SQL> ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;

