Flink 实战之维表关联
 在实际的生产应用场景中,实时流式数据与维表数据的关联并生成宽表是极为常见的需求。面对这样的需求,存在多种维表关联方式可供选择。本文聚焦于其中三种常见方式展开具体实现与研究,分别是 1. 预加载维表、2. 异步 IO 3. 广播维表。
为了让读者更直观、深入地理解这三种实现方式,本文采用了实验和图解原理相结合的方法,不仅如此,还对每种方法的优点和缺点进行了细致比较。此外,为了便于读者实践和进一步探索,每种实现方式都附上了源码,同时搭配动态效果图,让复杂的技术内容变得更加清晰易懂。
在实际的生产应用场景中,实时流式数据与维表数据的关联并生成宽表是极为常见的需求。面对这样的需求,存在多种维表关联方式可供选择。本文聚焦于其中三种常见方式展开具体实现与研究,分别是 1. 预加载维表、2. 异步 IO 3. 广播维表。
为了让读者更直观、深入地理解这三种实现方式,本文采用了实验和图解原理相结合的方法,不仅如此,还对每种方法的优点和缺点进行了细致比较。此外,为了便于读者实践和进一步探索,每种实现方式都附上了源码,同时搭配动态效果图,让复杂的技术内容变得更加清晰易懂。

- Flink 实战之 Real-Time DateHistogram
- Flink 实战之从 Kafka 到 ES
- Flink 实战之维表关联
生产应用中,经常遇到将实时 流式数据 与 维表数据 进行关联的场景。常见的维表关联方式有多种,本文对以下 3 种进行了实现,并对每种方法的优缺点进行了比较:
- 预加载维表
- 异步 IO
- 广播维表
下面分别使用不同方式来完成维表 join 的实验。
实验设计
用户数据存储在数据库中,是为维表。表结构设计如下:
| id | name | age | |
|---|---|---|---|
| 1 | Tom | 19 | tom@qq.com |
| 2 | John | 21 | john@gmail.com |
| 3 | Roy | 20 | roy@hotmail.com |
用户在购物网站的实时行为数据存储在 Kafka 中,数据结构如下:
{
"userId": 2, // 用户id
"productId": 9, // 商品id
"eventType": "Add to cart", // 用户对商品做出的行为,如:加购,收藏
"timestamp": 1620981709790 // 时间戳
}
Kafka 中的行为数据实时产生,要求与维表数据实时关联后生成订单数据。
预加载维表
定义一个 RichMapFunction,在 open 方法中读取维表数据加载到内存中,在 map 方法中完成与数据流的关联。
下面是基本实现:
DimExtendRichMapFunction.java
package org.example.flink.operator;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.HashMap;
import java.util.Map;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.configuration.Configuration;
import org.example.flink.data.User;
import org.example.flink.data.Action;
import org.example.flink.data.UserAction;
public class DimExtendRichMapFunction extends RichMapFunction<Action, UserAction> {
private static final long serialVersionUID = 1L;
private transient Connection connection;
// User 数据缓存
private Map<Integer, User> userInfoMap;
@Override
public void open(Configuration configuration) throws Exception {
String url = "jdbc:mysql://127.0.0.1:3306/flink";
String username = "username";
String password = "password";
connection = DriverManager.getConnection(url, username, password);
// 加载维表数据到缓存中
userInfoMap = new HashMap<>();
PreparedStatement ps = connection.prepareStatement("SELECT id, name, age, email FROM user");
ResultSet rs = ps.executeQuery();
while (rs.next()) {
int id = rs.getInt("id");
String name = rs.getString("name");
int age = rs.getInt("age");
String email = rs.getString("email");
User user = new User(id, name, age, email);
userInfoMap.put(id, user);
}
}
/**
* 流表数据与维表数据关联, 接收是 Action, 输出是 UserAction
*/
@Override
public UserAction map(Action action) throws Exception {
UserAction userAction = new UserAction(action);
int userId = action.getUserId();
if (userInfoMap.containsKey(userId)) {
User user = userInfoMap.get(userId);
userAction.setUser(user);
}
return userAction;
}
@Override
public void close() throws Exception {
// 关闭数据库连接
if (connection != null) {
connection.close();
}
}
}
DimExtendRichMapFunction.java
package org.example.flink;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.example.flink.data.Action;
import org.example.flink.data.UserAction;
import org.example.flink.operator.DimExtendRichMapFunction;
import com.google.gson.Gson;
public class DimensionExtendUsingMap {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
configuration.setString("rest.port", "9091");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
// 1. 从Kafka中加载用户行为数据流
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("127.0.0.1:9092")
.setTopics("user-action")
.setGroupId("group-01")
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> sourceStream = env.fromSource(source, WatermarkStrategy.noWatermarks(),
"Kafka Source");
sourceStream.setParallelism(1); // 设置source算子的并行度为1
// 2. 转换为UserAction对象
SingleOutputStreamOperator<Action> actionStream = sourceStream
.map(new MapFunction<String, Action>() {
private static final long serialVersionUID = 1L;
@Override
public Action map(String value) throws Exception {
Gson gson = new Gson();
Action userAction = gson.fromJson(value, Action.class);
return userAction;
}
});
actionStream.name("Map to Action");
actionStream.setParallelism(1); // 设置map算子的并行度为1
// 3. 维表关联
SingleOutputStreamOperator<UserAction> userActionStream = actionStream
.map(new DimExtendRichMapFunction());
userActionStream.name("Extend Dimensions");
userActionStream.setParallelism(2); // 设置RichMap算子的并行度为2
// 4. 打印关联结果
userActionStream.print();
// 执行
env.execute("Dimension Extend Using RichMapFunction");
}
}
实现效果:
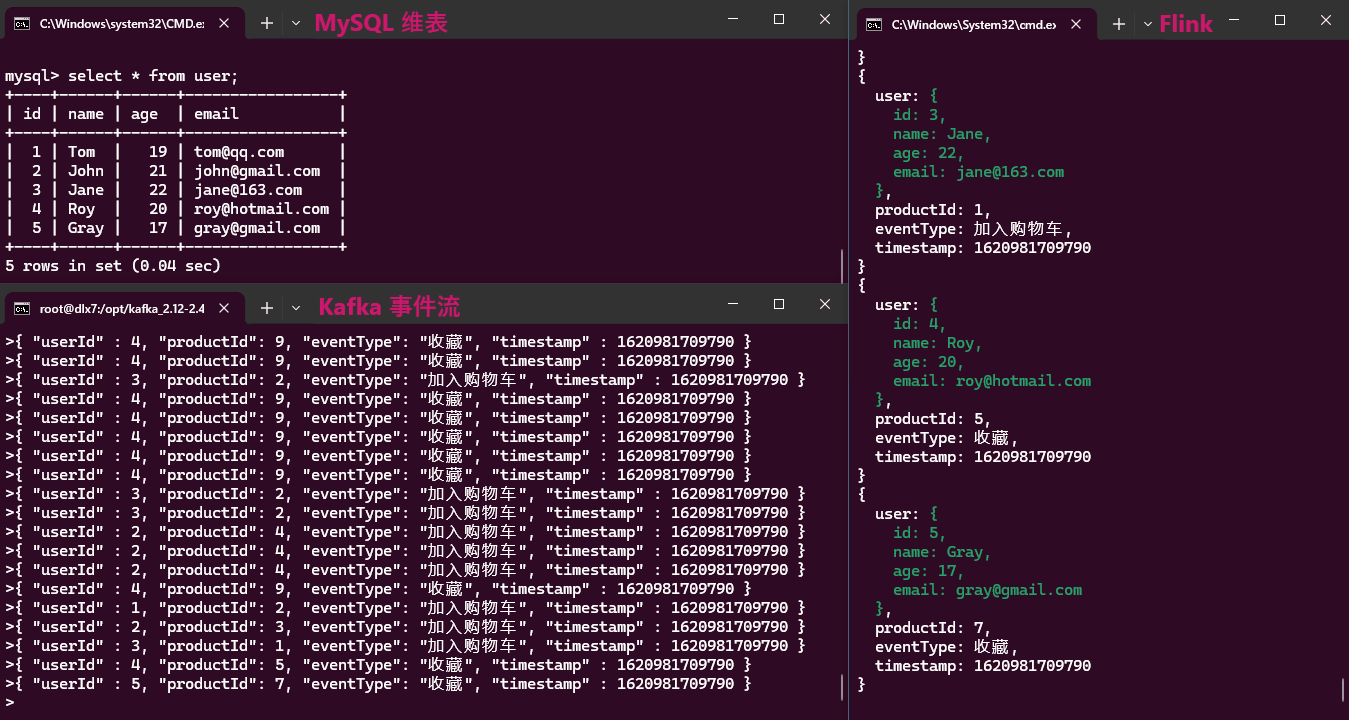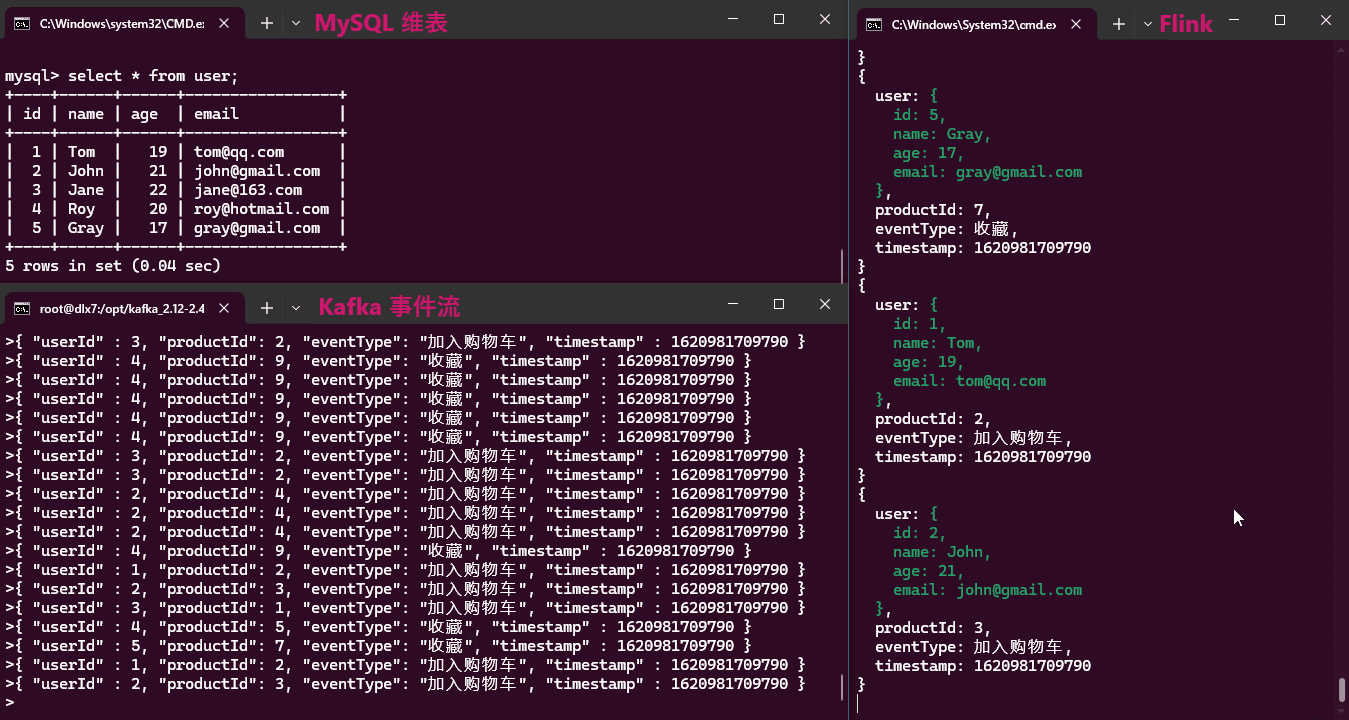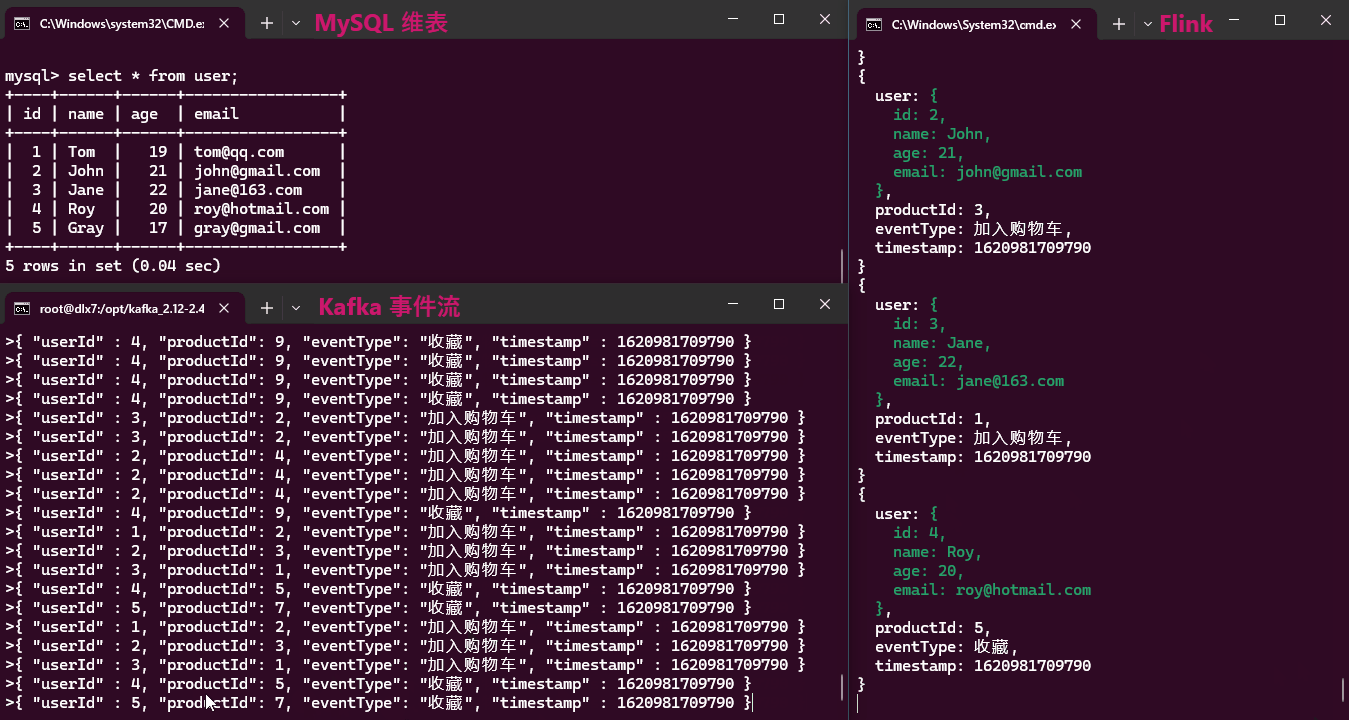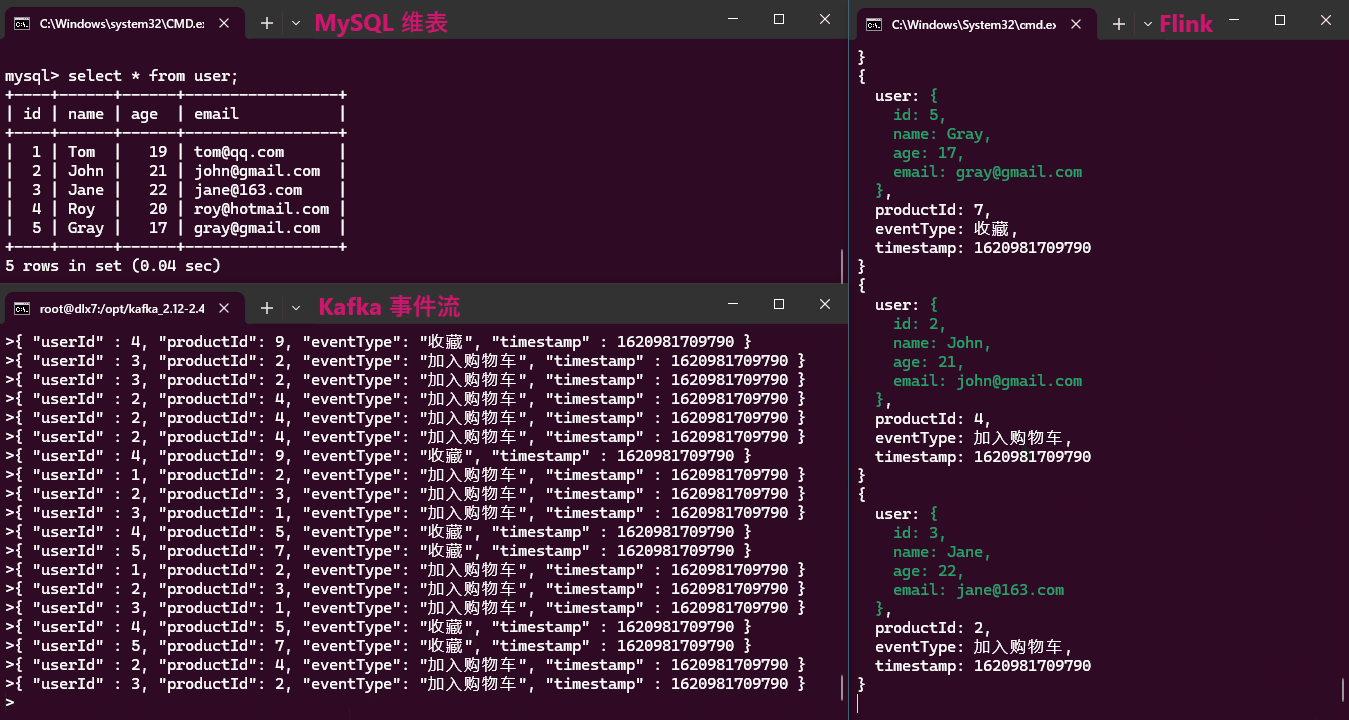
从效果动画中可以看出,维表数据的更新无法被感知,因此本方案只适合维表数据不频繁更新的情况。
预加载维表的关联方式,优缺点非常明显:
- 优点:实现简单
- 缺点:无法及时感知维表数据更新,维表数据一次性加载到内存,所以不适合大数据量。
异步 IO
Flink中可以使用异步 IO 来读写外部系统。与数据库异步交互是指一个并行函数实例可以并发地处理多个请求和接收多个响应。这样,函数在等待的时间可以发送其他请求和接收其他响应。至少等待的时间可以被多个请求摊分。大多数情况下,异步交互可以大幅度提高流处理的吞吐量。参见官网

不过既然是异步,那就需要考虑以下几个问题:
- 超时处理:当异步 I/O 请求超时的时候,默认会抛出异常并重启作业。 如果你想处理超时,可以重写
AsyncFunction#timeout方法; - 结果的顺序:
AsyncFunction发出的并发请求经常以不确定的顺序完成,这取决于请求得到响应的顺序。 Flink 提供两种模式控制结果记录以何种顺序发出。- 无序模式:异步请求一结束就立刻发出结果记录。 流中记录的顺序在经过异步 I/O 算子之后发生了改变。 当使用 处理时间 作为基本时间特征时,这个模式具有最低的延迟和最少的开销。 此模式使用
AsyncDataStream.unorderedWait(...)方法。 - 有序模式:这种模式保持了流的顺序。发出结果记录的顺序与触发异步请求的顺序(记录输入算子的顺序)相同。为了实现这一点,算子将缓冲一个结果记录直到这条记录前面的所有记录都发出(或超时)。由于记录或者结果要在 checkpoint 的状态中保存更长的时间,所以与无序模式相比,有序模式通常会带来一些额外的延迟和 checkpoint 开销。此模式使用
AsyncDataStream.orderedWait(...)方法。
- 无序模式:异步请求一结束就立刻发出结果记录。 流中记录的顺序在经过异步 I/O 算子之后发生了改变。 当使用 处理时间 作为基本时间特征时,这个模式具有最低的延迟和最少的开销。 此模式使用
下面是基本实现:
AsyncDatabaseRequest.java
package org.example.flink.operator;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Collections;
import java.util.concurrent.CompletableFuture;
import java.util.function.Supplier;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.async.ResultFuture;
import org.apache.flink.streaming.api.functions.async.RichAsyncFunction;
import org.example.flink.data.Action;
import org.example.flink.data.User;
import org.example.flink.data.UserAction;
public class AsyncDatabaseRequest extends RichAsyncFunction<Action, UserAction> {
private static final long serialVersionUID = 1L;
private transient Connection connection;
private transient PreparedStatement statement;
@Override
public void open(Configuration configuration) throws Exception {
String url = "jdbc:mysql://127.0.0.1:3306/flink";
String username = "username";
String password = "password";
connection = DriverManager.getConnection(url, username, password);
statement = connection.prepareStatement("SELECT name, age, email FROM user WHERE ID = ?");
}
@Override
public void asyncInvoke(Action action, ResultFuture<UserAction> resultFuture) throws Exception {
CompletableFuture.supplyAsync(new Supplier<User>() {
@Override
public User get() {
// 获取实时流的id
int id = action.getUserId();
// 根据实时流的id去获取维表数据
try {
statement.setInt(1, id);
ResultSet rs = statement.executeQuery();
User user = new User();
while (rs.next()) {
String name = rs.getString("name");
int age = rs.getInt("age");
String email = rs.getString("email");
user = new User(id, name, age, email);
}
return user;
} catch (SQLException e) {
e.printStackTrace();
return null;
}
}
}).thenAccept( (User user) -> {
if (user != null) {
resultFuture.complete(Collections.singleton(new UserAction(user, action)));
} else {
System.out.println("User not found for action: " + action.toString());
resultFuture.complete(Collections.emptyList());
}
});
}
@Override
public void close() throws Exception {
// 关闭连接
if (statement != null) {
statement.close();
}
if (connection != null) {
connection.close();
}
}
}
DimensionExtendUsingAsyncIO.java
package org.example.flink;
import java.util.concurrent.TimeUnit;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.AsyncDataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.example.flink.data.Action;
import org.example.flink.data.UserAction;
import org.example.flink.operator.AsyncDatabaseRequest;
import com.google.gson.Gson;
public class DimensionExtendUsingAsyncIO {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
configuration.setString("rest.port", "9091");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
// 1. 从Kafka中加载用户行为数据流
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("127.0.0.1:9092")
.setTopics("user-action")
.setGroupId("group-01")
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> sourceStream = env.fromSource(source, WatermarkStrategy.noWatermarks(),
"Kafka Source");
sourceStream.setParallelism(1); // 设置source算子的并行度为1
// 2. 转换为UserAction对象
SingleOutputStreamOperator<Action> actionStream = sourceStream
.map(new MapFunction<String, Action>() {
private static final long serialVersionUID = 1L;
@Override
public Action map(String value) throws Exception {
Gson gson = new Gson();
Action userAction = gson.fromJson(value, Action.class);
return userAction;
}
});
actionStream.name("Map to Action");
actionStream.setParallelism(1); // 设置map算子的并行度为1
// 3. 维表关联
SingleOutputStreamOperator<UserAction> userActionStream = AsyncDataStream.unorderedWait(actionStream,
new AsyncDatabaseRequest(), 30, TimeUnit.SECONDS);
userActionStream.name("Extend Dimensions");
userActionStream.setParallelism(2);
// 4. 打印关联结果
userActionStream.print();
// 执行
env.execute("Dimension Extend Using AsyncIO");
}
}
实现效果:
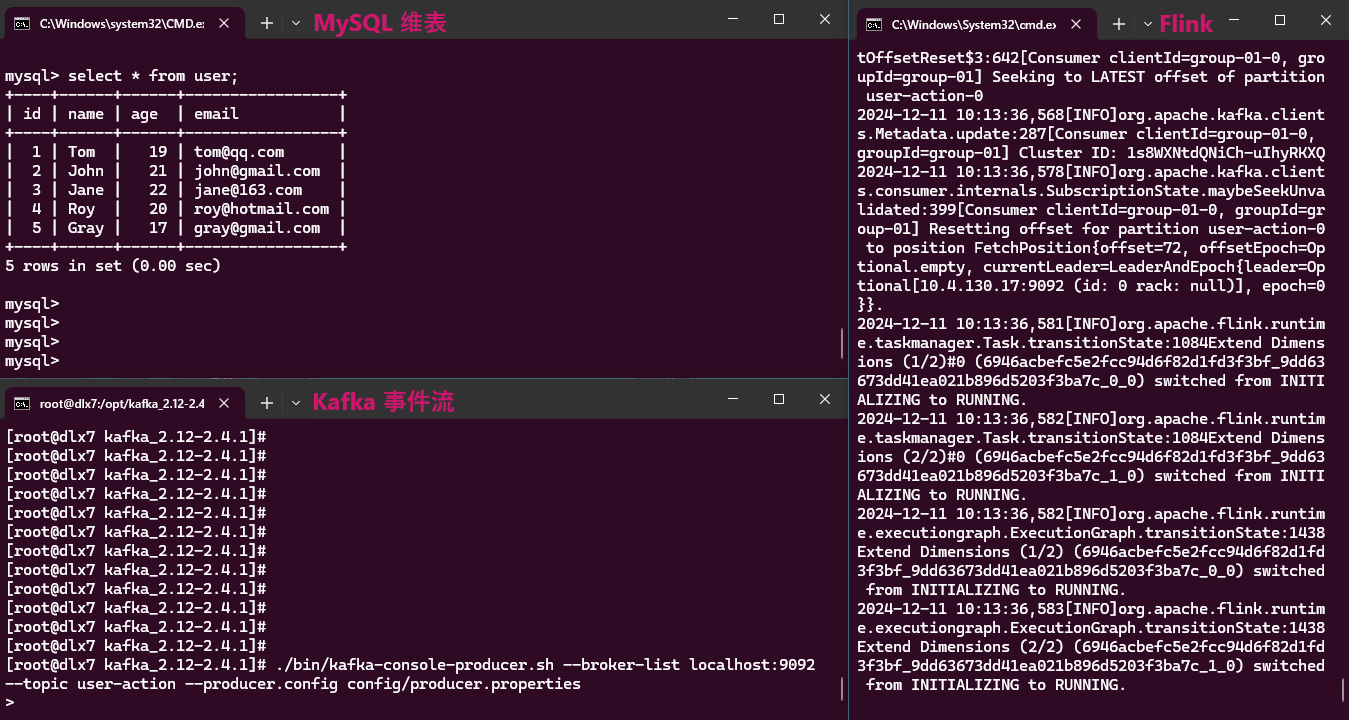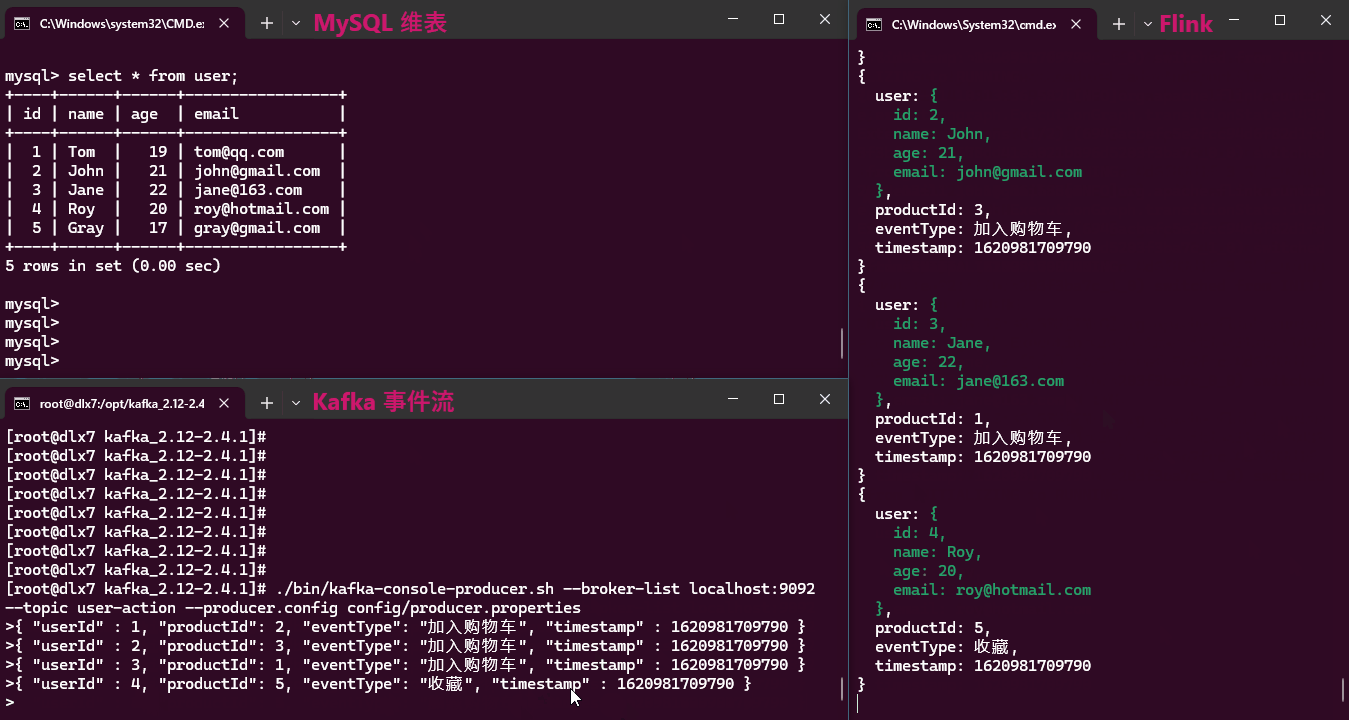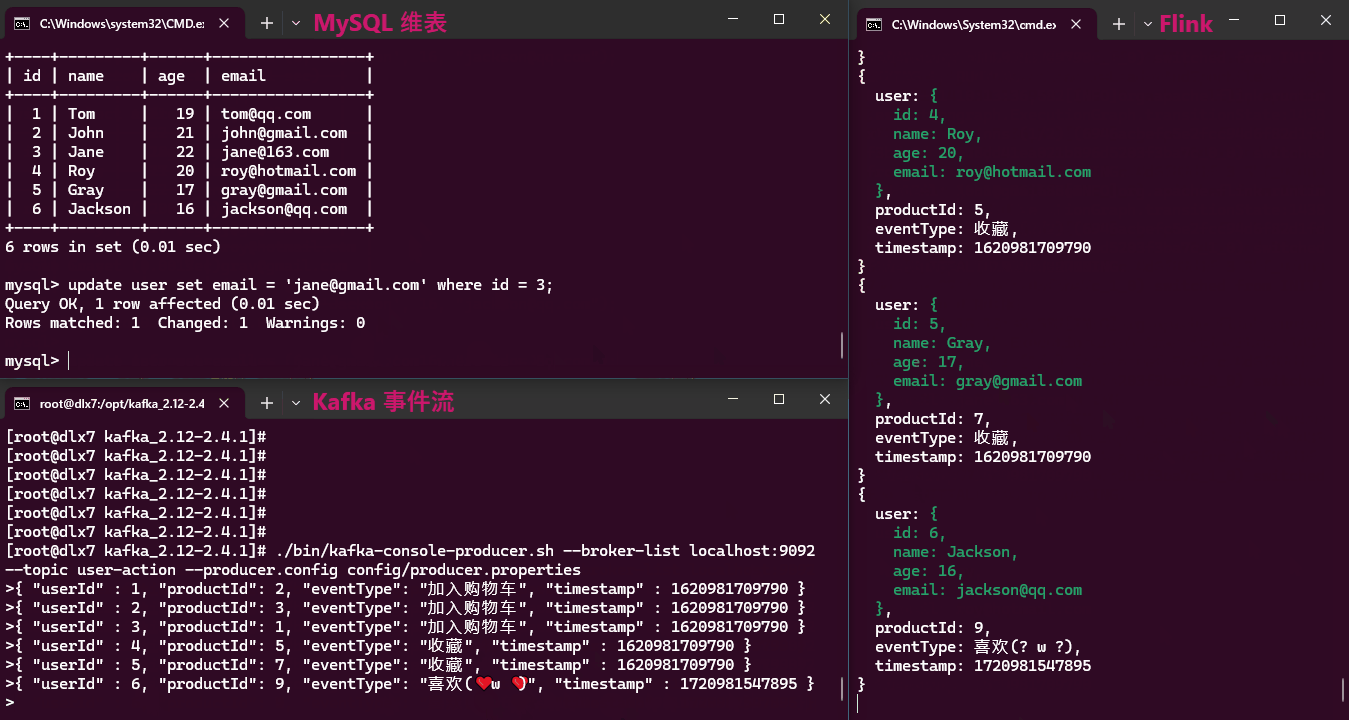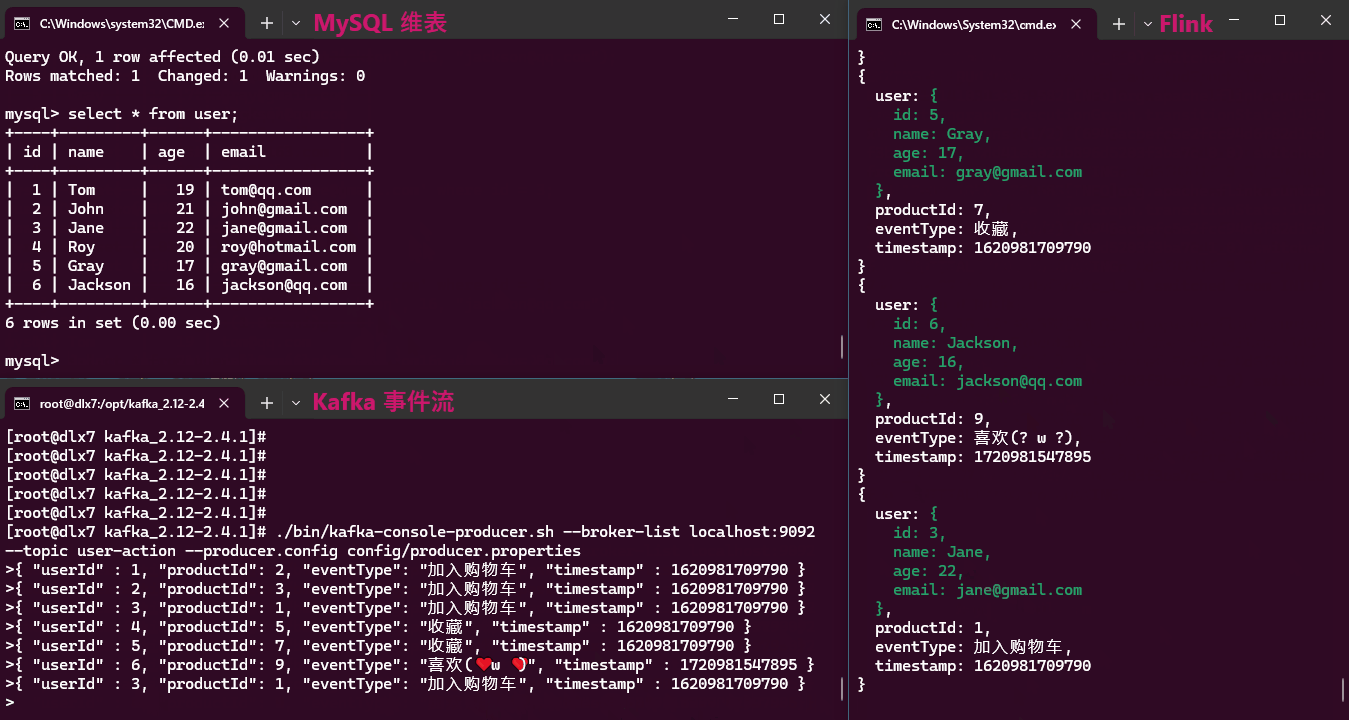
从效果动画中可以看出,维表数据的任何更新,都能及时反映在关联结果中。
- 优点:维度数据量不再受内存的限制,可以存储很大的数据量;
- 缺点:因为维表数据存储在外部存储中,吞吐量受限于外部的读取速度;
广播维表
将维表数据作为 Broadcast State 传递到下游做关联。这是 Flink 状态广播的最常规用法。
回到我们的实验场景,我们的维表数据存储在 MySQL 中,将数据库中的数据加载为广播流容易,如何及时地将数据库的更新也同步到广播流就很棘手了。如果还要定时拉取全量数据以更新广播状态,这本质上和 预加载维表 的方案并无区别。
如何及时捕获到数据库的更新操作呢,这就要借助 Flink CDC 技术了。数据库的每一个事务,都会记录在数据库的日志中,对于 MySQL 来说是 binlog,对于 Oracle 来说是 archive log。
以 MySQL 的 binlog 为例,数据格式如下:
{
"op": "c", // 操作类型,c=create, u=update, d=delete, r=read
"ts_ms": 1465491411815, // 时间戳
"before": null, // row 在操作之前的数据,如果是插入,before为null
"after": { // row 在操作之后的数据,如果是删除,after为null
"id": 1004,
"first_name": "Anne",
"last_name": "Kretchmar",
"email": "annek@noanswer.org"
},
"source": {
"db": "inventory",
"table": "customers",
"server_id": 0,
"file": "mysql-bin.000003",
"query": "INSERT INTO customers (first_name, last_name, email) VALUES ('Anne', 'Kretchmar', 'annek@noanswer.org')"
}
}
读取 MySQL binlog 的 Connector 就是官方提供的 mysql-cdc, 读取到 binlog 数据流之后,再反序列化即可同步更新到 Broadcast State 中了。
数据流图:

基本实现:
package org.example.flink;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.state.BroadcastState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.BroadcastStream;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.util.Collector;
import org.example.flink.data.Action;
import org.example.flink.data.User;
import org.example.flink.data.UserAction;
import com.alibaba.fastjson.JSONObject;
import com.google.gson.Gson;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
public class DimensionExtendUsingBroadcast {
private static final String INSERT = "+I";
private static final String UPDATE = "+U";
private static final String DELETE = "-D";
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
configuration.setString("rest.port", "9091");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
// 1. 从Kafka中加载用户行为数据流
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("127.0.0.1:9092")
.setTopics("user-action")
.setGroupId("group-01")
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> sourceStream = env.fromSource(source, WatermarkStrategy.noWatermarks(),
"Kafka Source");
sourceStream.setParallelism(1); // 设置source算子的并行度为1
// 2. 转换为UserAction对象
SingleOutputStreamOperator<Action> actionStream = sourceStream
.map(new MapFunction<String, Action>() {
private static final long serialVersionUID = 1L;
@Override
public Action map(String value) throws Exception {
Gson gson = new Gson();
Action userAction = gson.fromJson(value, Action.class);
return userAction;
}
});
actionStream.name("Map to Action");
actionStream.setParallelism(1); // 设置map算子的并行度为1
// 3. 读取MySQL维表的binlog
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("127.0.0.1")
.port(3306)
.databaseList("flink")
.tableList("flink.user")
.username("username")
.password("password")
.startupOptions(StartupOptions.initial()) // 设置initial才会加载存量数据
.deserializer(new JsonDebeziumDeserializationSchema()) // 读取到的binlog反序列化为json格式
.build();
DataStream<String> userBinlogStream = env
.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")
.setParallelism(1); // 设置MySQL维表读取并行度为1
// 4. 将json格式的binlog转换为User对象
DataStream<User> userStream = userBinlogStream
.map(new MapFunction<String, User>() {
private static final long serialVersionUID = 1L;
@Override
public User map(String value) throws Exception {
JSONObject jsonObject = JSONObject.parseObject(value);
JSONObject before = jsonObject.getJSONObject("before");
JSONObject after = jsonObject.getJSONObject("after");
// binlog日志before和after都不为null, 表示为更新操作, 用'+U'标记
if (before != null && after != null) {
return new User(UPDATE, after.toJSONString());
}
// binlog日志before为null, 表示为插入操作, 用'+I'标记
else if (before == null) {
return new User(INSERT, after.toJSONString());
}
// binlog日志after为null, 表示为删除操作, 用'-D'标记
else {
return new User(DELETE, before.toJSONString());
}
}
})
.setParallelism(1);
// 5. 将User维表转换为broadcast state
MapStateDescriptor<Integer, User> broadcastStateDescriptor = new MapStateDescriptor<>(
"user-state",
Integer.class,
User.class
);
BroadcastStream<User> broadcastUserStream = userStream.broadcast(broadcastStateDescriptor);
// 6. 将维表信息传递(connect)给流表, 即维表与流表关联
DataStream<UserAction> userActionStream = actionStream.connect(broadcastUserStream)
.process(new BroadcastProcessFunction<Action, User, UserAction>() {
private static final long serialVersionUID = 1L;
@Override
public void processElement(Action action, ReadOnlyContext ctx, Collector<UserAction> out)
throws Exception {
UserAction userAction = new UserAction(action);
// 从broadcast state中获取维表信息
BroadcastState<Integer, User> broadcastState = (BroadcastState<Integer, User>) ctx
.getBroadcastState(broadcastStateDescriptor);
User user = broadcastState.get(action.getUserId());
// 流表与维表关联
if (user != null) {
userAction.setUser(user);
}
out.collect(userAction);
}
@Override
public void processBroadcastElement(User user, Context ctx, Collector<UserAction> out)
throws Exception {
// 维表更新时, 更新broadcast state
BroadcastState<Integer, User> broadcastState = (BroadcastState<Integer, User>) ctx
.getBroadcastState(broadcastStateDescriptor);
if (user.getOp() == null || user.getOp().equals(UPDATE) || user.getOp().equals(INSERT)) {
// 新增/更新数时,更新broadcast state
broadcastState.put(user.getId(), user);
} else if (user.getOp().equals(DELETE)) {
// 删除数时,更新broadcast state
broadcastState.remove(user.getId());
}
}
})
.setParallelism(1);
// 7. 打印关联结果
userActionStream.print();
// 执行
env.execute("Dimension Extend Using Broadcast");
}
}
实现效果:
从实现效果可以看出,当维表数据更新时,binlog 实时更新,broadcast state 随之更新,关联结果也实时更新。
广播维表的方式实现的关联:
- 优点:支持维表数据的实时变更
- 缺点:维表数据存储在内存中,支持的维度数据量受限于内存大小
总结
不同关联方式的比较:
| 支持维表实时更新 | 支持维表数据量 | 处理速度 | |
|---|---|---|---|
| 预加载维表 | 否 | 小 | 快 |
| 异步 IO | 是 | 大 | 慢 |
| 广播维表 | 是 | 小 | 快 |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报