JVM垃圾回收算法
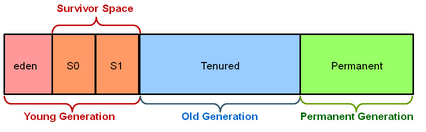
2017-09-20 11:03 钰火 阅读(906) 评论(0) 收藏 举报1.堆的分代和区域
(年轻代)Young Generation(eden、s0、s1 space) Minor GC
(老年代)Old Generation (Tenured space) Major GC|| Full GC
(永久代)Permanent Generation (Permanent space)【方法区(method area)】 Major GC
本地化的String从JDK 7开始就被移除了永久代(Permanent Generation )
JDK 8.HotSpot JVM开始使用本地化的内存存放类的元数据,这个空间叫做元空间(Metaspace)
2.判断对象是否存活(哪些是垃圾对象)
1.引用计数(ReferenceCounting):对象有引用计数属性,增加一个引用计数加1,减少一个引用计数减1,计数为0时可回收。(无法解决对象相互循环引用的问题)
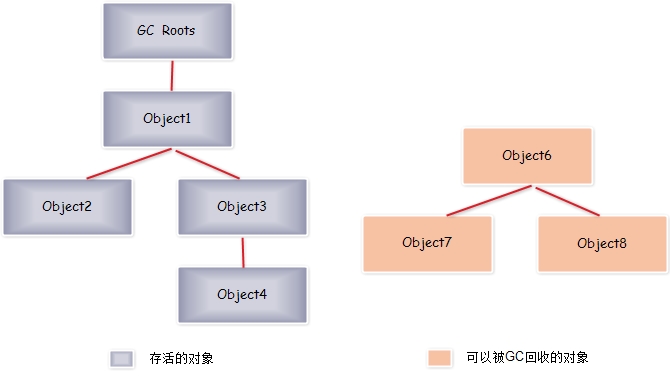
2.根搜索(GC Roots Tracing):GCRoot对象作为起始点(根)。如果从根到某个对象是可达的,则该对象称为“可达对象”(存活对象,不可回收对象)。否则就是不可达对象,可以被回收。
下图中,对象Object6、Object7、Object8虽然互相引用,但他们的GC Roots是不可到达的,所以它们将会被判定为是可回收的对象
3.垃圾收集算法
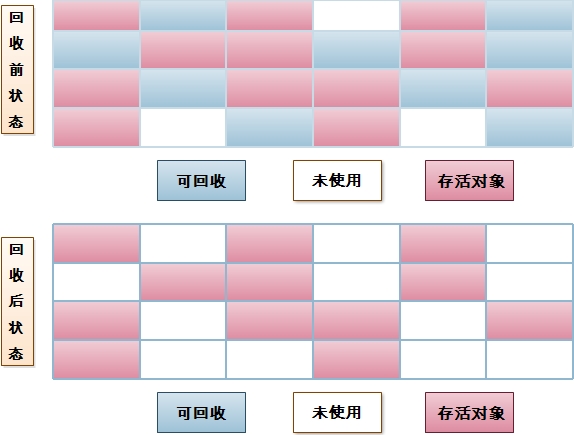
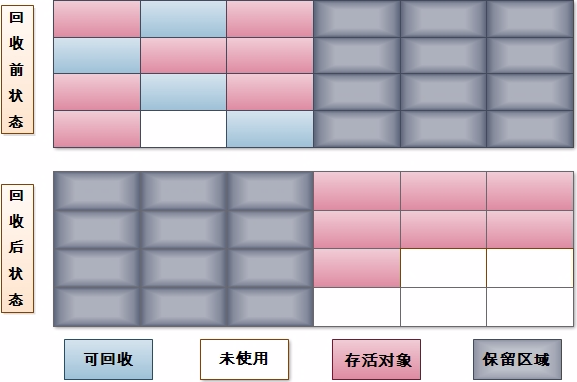
1.标记-清除(Mark-Sweep)算法:
标记清除算法分为“标记”和“清除”两个阶段:首先标记出需要回收的对象,标记完成之后统一清除对象。
缺点:
1、标记和清除效率不高;
2、产生大量不连续的内存碎片,导致有大量内存剩余的情况下,由于,没有连续的空间来存放较大的对象,从而触发了另一次垃圾收集动作。
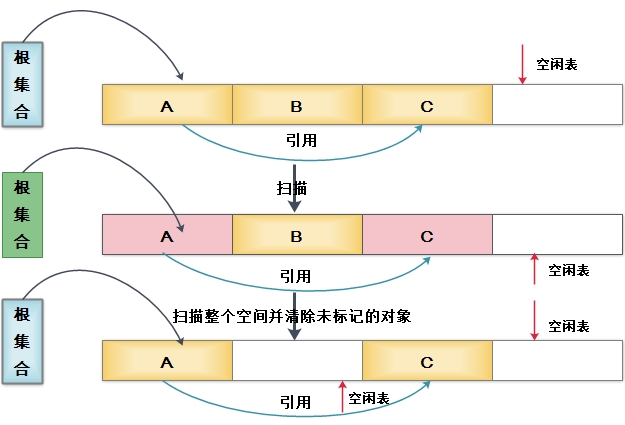
将可用内存容量划分为大小相等的两块,每次只使用其中的一块。当这一块用完之后,就将还存活的对象复制到另外一块上面,然后在把已使用过的内存空间一次清理掉。这样使得每次都是对其中的一块进行内存回收,不会产生碎片等情况,只要移动堆订的指针,按顺序分配内存即可,实现简单,运行高效。
缺点:
1.内存缩小为原来的一半,太浪费内存
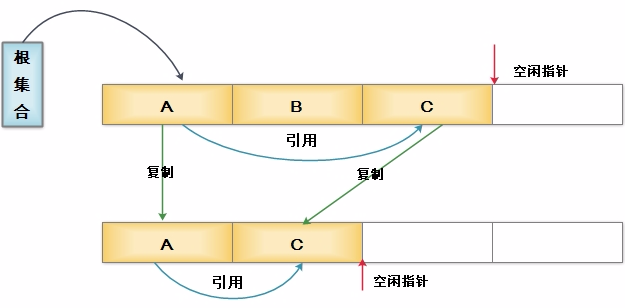
对复制算法进一步优化:使用Eden/S0/S1三个分区
平均分成A/B块太浪费内存,采用Eden/S0/S1三个区更合理,一个较大的Eden空间和两个较小的Survivor空间,空间比例为Eden:S0:S1==8:1:1,有效内存(即可分配新生对象的内存)是总内存的9/10。
算法过程:
1. Eden+S0可分配新生对象;
2. 对Eden+S0进行垃圾收集,存活对象复制到S1。清理Eden+S0。一次新生代GC结束。
3. Eden+S1可分配新生对象;
4. 对Eden+S1进行垃圾收集,存活对象复制到S0。清理Eden+S1。二次新生代GC结束。
5. goto 1。
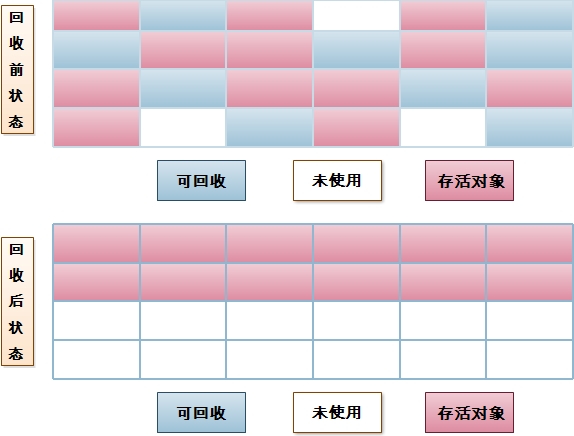
3.标记-整理(Mark-Compact)算法:
同样的该算法分为两个阶段:标记、整理。标记阶段同“标记-清除”算法。整理阶段,不是直接对标记对象进行清理,而是让所有存活的对象都移动到一端,然后,直接把边界以外的内存清空。解决“标记-清除”算法会造成大量不连续内存碎片的问题。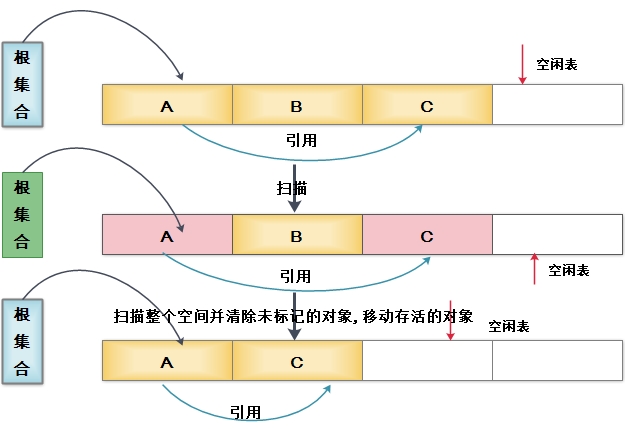
4.分代收集算法:
分代收集算法是根据对象的存活周期的不同,将内存划分为几块。当前的商业虚拟机的垃圾收集都采用了该算法。一般把Java堆分成年轻代和老年代(年老代)。可以根据各年代中对象的存活周期来选择最合适的收集算法。
新生代,由于只有少量的对象能存活下来,所以选用“复制算法”,只需要付出少量存活对象的复制成本。老年代,由于对象的存活率高,没有额外的空间分担,就必须使用“标记-清除”或“标记-整理”算法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号