高并发系统三大利器之降级
服务降级是当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以此释放服务器资源以保证核心任务的正常运行。
我们可以举个栗子:双十一的时候,我们买东西是不是都不允许修改购物地址,不允许发起退货,不允许退款还有很多服务都不可以用,只允许用户选择商品加入购物车付钱。那天只有一个目的就是让一些不是很重要的服务所占用的cpu资源都让出来,给购物,付款这样的核心服务。这样的话,用户付款的速度就会越来越快,毕竟前多少名支付的用户是有免单机会的(大家都会挤在0点那一刻去付款)。服务降级主要用于当整个微服务架构整体的负载超出了预设的上限阈值或即将到来的流量预计将会超过预设的阈值时,为了保证重要或基本的服务能正常运行,将一些 不重要 或 不紧急 的服务或任务进行服务的 延迟使用 或 暂停使用。
降级就是为了解决资源不足和访问量增加的矛盾。
服务降级方式
- 延迟服务:定时任务处理、或者
mq延时处理。比如新用户注册送多少优惠券可以提示用户优惠券会24小时到达用户账号中,我们可以选择再凌晨流量较小的时候,批量去执行送券。 - 页面降级:页面点击按钮全部置灰,或者页面调整成为一个静态页面显示“系统正在维护中,。。。。”。
- 关闭非核心服务:比如电商关闭推荐服务、关闭运费险、退货退款等。保证主流程的核心服务下单付款就好。
- 写降级:比如秒杀抢购,我们可以只进行
Cache的更新返回,然后通过mq异步扣减库存到DB,保证最终一致性即可,此时可以将DB降级为Cache。 - 读降级:比如多级缓存模式,如果后端服务有问题,可以降级为只读缓存,这种方式适用于对读一致性要求不高的场景。
服务熔断
服务雪崩
说到服务熔断我们就得先了解下什么是服务雪崩。雪崩效应好比就是蝴蝶效应,说的都是一个小因素的变化,却往往有着无比强大的力量,以至于最后改变整体结构、产生意想不到的结果。
多个微服务之间调用的时候,比如A服务调用了B服务,B服务调用了C服务,然后C服务由于机器宕机或者网略故障, 然后就会导致B服务调用C服务的时候超时,然后A服务调用B服务也会超时,最终整个链路都不可用了,导致整个系统不可用就跟雪蹦一样。
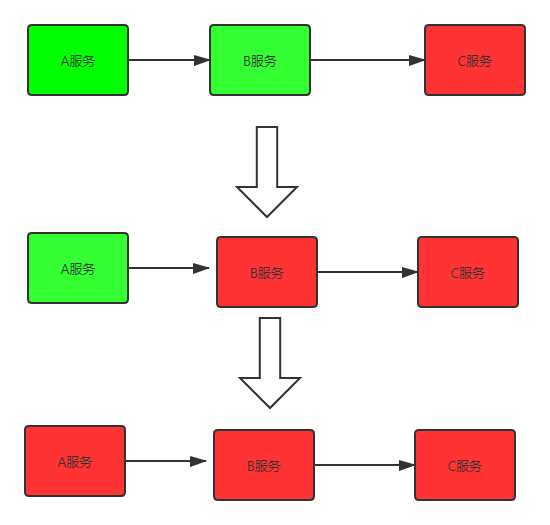
雪崩效应产生的几种场景
- 突增流量:比如一大波爬虫,或者黑客攻击等。
- 程序bug:代码死循环,或者资源未释放等。
- 硬件原因:机器宕机、机房断电、光纤被挖断等。
说完了服务雪崩然后就可以说下服务熔断了。 熔断机制是应对雪崩效应的一种微服务链路保护机制,在互联网系统中当下游的服务因为某种原因突然变得不可用或响应过慢,上游服务为了保证自己整体服务的可用性,暂时不再继续调用目标服务,直接快速返回,快速释放资源。如果目标服务情况好转则恢复调用。
通俗点来说的话就是,比如我们以前大学的时候宿舍是不是不允许使用大功率电器,一旦使用大功率电器,电流过大,宿舍立马就会跳闸断电。因为已经超过了这个已经超过了电线所能承载的最大电流。如果不断电话的会导致火灾,然后整栋宿舍都会断电。宿舍停电之后要恢复来电的话需要到宿管那里解释下为什么突然停电了,上交大功率电器,一顿教育然后才会给你恢复供电。
熔断和降级的比较
共性
- 目的很一致:都是从可用性可靠性着想,为防止系统的整体缓慢甚至崩溃,采用的技术手段,都是为了保证系统的稳定。
- 终表现类似:对于两者来说,最终让用户体验到的是某些功能暂时不可达或不可用;
- 粒度一般都是服务级别:当然,业界也有不少更细粒度的做法,比如做到数据持久层(允许查询,不允许增删改);
- 自治性要求很高: 熔断模式一般都是服务基于策略的自动触发,比如
降级虽说可人工干预,但在微服务架构下,完全靠人显然不可能,开关预置、配置中心都是必要手段;
差异性
- 触发原因不太一样,服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑;
- 管理目标的层次不太一样,熔断其实是一个框架级的处理,每个微服务都需要(无层级之分),而降级一般需要对业务有层级之分(比如降级一般是从最外围服务开始)熔断是降级方式的一种体现。
鸣谢:
https://blog.csdn.net/zengfanwei1990/article/details/108146116

