第四次博客作业——结队编程
| 作业要求地址 | https://www.cnblogs.com/harry240/p/11524113.html |
| GitHub项目地址 | https://github.com/anranbixin/WordCount |
| 结对伙伴的博客 | https://www.cnblogs.com/step-enter/p/11644293.html |
1、PSP表格
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
30 |
40 |
|
· Estimate |
· 估计这个任务需要多少时间 |
1200 |
1440 |
|
Development |
开发 |
1080 |
1200 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
40 |
50 |
|
· Design Spec |
· 生成设计文档 |
20 |
20 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
20 |
30 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
30 |
30 |
|
· Design |
· 具体设计 |
60 |
50 |
|
· Coding |
· 具体编码 |
700 |
960 |
|
· Code Review |
· 代码复审 |
60 |
50 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
120 |
150 |
|
Reporting |
报告 |
30 |
20 |
|
· Test Report |
· 测试报告 |
60 |
40 |
|
· Size Measurement |
· 计算工作量 |
30 |
20 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
30 |
20 |
|
|
合计 |
1230 |
1480 |
2、计算模块接口的设计与实现过程
2.1项目分析(项目需求)
(1)应具备的功能
- 统计文件的字符数
要求:1、汉字不考虑,空格、空格,水平制表符,换行符,均算字符,
2、输出的单词统一为小写格式
- 统计文件的单词总数
要求:1、至少以4个英文字母开头,且可以跟上字母数字符号
2、单词以分隔符分割,且不区分大小写
- 统计文件的有效行数
要求:任何包含非空白字符的行都需要统计
- 统计文件中各单词的频数
要求:1、最终只输出频率最高的10个
2、频率相同的单词,优先输出字典序靠前的单词。
- 按照字典序输出到文件txt(默认为output.txt)
要求:1、字典里面的单词已经过频数排序
2、输出的文件可任意指定
3、输出的量可控
(2)新功能
- 词组统计
要求:能统计文件夹中指定长度的词组的词频
- 自定义输出
要求:能输出用户指定的前n多的单词与其数量
- 多参数的混合使用
要求:格式为 -i input路径 -o output路径 -n 参数 -m 参数
(3)附加功能(这个功能我们两个决定选择性的实现)
- 用户交互界面绘制
2.2项目思路
-- 首先假设给出的路径已知,分别为(便于我们之后要进行指令读入造成的代码修改):
(1)读入文件路径:D:\VS_practice\wordCount\wordCount\bin\Debug\input.txt
(2)写入文件路径:D:\VS_practice\wordCount\wordCount\bin\Debug\output.txt
注意:1、这里我们程序运行的当前路径为:D:\VS_practice\wordCount\wordCount\bin\Debug
2、我们只需要调用语句,即可获得当前程序路径,之后加上我们的文件名即可
//获取当前文件路径 string currentpath = Directory.GetCurrentDirectory();
(3)数据的读取上,我们考虑到文件内容如果很大会影响数据的读取,我们采用的是content.ReadLine()进行单行的读取,这里也是会出现问题的,值得注意的一点是:在读入的input.txt文件里面,每一行英文必须是要用空格或者其他符号结尾,不然在后面使用Regex(Regex我会在后面单独提到)进行单词的提取上会出现错误
-- 程序如何才能实现:
(1)我们预计设计两个.cs文件,一个为主函数.cs文件(program.cs),一个为函数.cs文件(port.cs)
(2)数据的存储:使用string 变量来存储字符数,list<> 来存储提取出来的单词,dictionary<string,int> 来存储单词以及其的频率(这里要使用到dictionary的两个参数的使用,key和)
(3)头文件的调用:文件的输入输出需要使用到StreamWriter,因此需要调用IO头文件;提取单词需要使用到System.Text.RegularExpressions.Regex,因此需要调用Text.RegularExpressions头文件
//文件流的输入输出 using System.IO; //正则表达式 using System.Text.RegularExpressions;
补充:
这里知识点的我参考了其他的博客:https://www.cnblogs.com/liangsetian/archive/2011/07/05/2098280.html
(4)获取字符数、单词数、频数等等,直接使用函数返回即可
(5)指定输出和指定单词组的输出都是涉及函数涉及,在之后会进行详解,这里输出会使用到遍历foreach ( element in list or dictionary)
(6)多参数的混合使用里面涉及到cmd命令,此时需要使用到args[i],通过Main方法中的string[] args参数来获取
补充:这里我进行了知识点的搜索(args),博客源为:https://blog.csdn.net/eric_k1m/article/details/37518579
-- 程序的流程大致为下图所示:
基础功能模块和新功能模块:


2.3接口的设计与代码的实现过程
-- 首先进行基础功能的接口设计与实现
这里我使用的是五个函数,首先必须依次调用Getcharacters(path);Withdraword();Tolower();Wordfrequency();这四函数,以实现初始化,中途涉及函数的调用,函数需要进行依次的设计,这四个函数需要依次进行实现,否则出来的结果是不正确的。例如:还没有进行字符的录入,但是你要输出单词这就是无法实现的。以下依次为5个函数的设计(4个基本+1个输出):
(1)进行字符的读取,这里我们必须要将待读取的文件的路径传进来,我们将函数设计为:public void Getcharacters(string path),在里面我们使用了ReadLine()来对path里面的文档进行一行一行的读取,然后将读取的字符直接存储于account_chara字符串里面


//读取文件,string account_chara用于存储字符 public void Getcharacters(string path) { StreamReader content = new StreamReader(path); //定义字符临时变量 string temp = content.ReadLine(); //读取 while (temp != null) { account_chara = account_chara + temp; account_line++; temp = content.ReadLine(); } //最后一行读入无效,将其删去 account_line -= 1; }
(2)接着就是将单词提取出来,这里我们采用的是之间说到的正则表达式,也就是使用Regex来对单词进行提取。由于我们提取单词是有要求的,需要我们(1)至少以4个英文字母开头,且可以跟上字母数字符号,所以我们采用的是:@"([a-zA-Z]{4}\w*)" (2)单词以分隔符分割,且不区分大小写,这里就需要把单词全部小写化,我们采用的是ToLower()
//正则表达式匹配英文单词 public void Withdraword() { //以字母开头,数字结尾,单词至少4个字符 MatchCollection mc_word = Regex.Matches(account_chara, @"([a-zA-Z]{4}\w*)"); //临时变量 int i = 0; while (i < mc_word.Count) { //存储单词 word.Add(Convert.ToString(mc_word[i])); i++; } }
//单词小写 foreach (string element in word) { element.ToLower(); }
注意:这里我们是弄的时间比较长,后来在参考博客发现可以使用正则表达式(Regex.Matches),博客的来源:https://www.cnblogs.com/gc2013/p/4071757.html
(3)计算字符的数目,这里需要注意的是我们的字符 (string account_chara)不包括中文,所以我们首先需要了解中文怎么表示,"[\u4e00-\u9fa5]" 表示中文。既然我们是把我们的字符存储在一个字符串temp里面(这里是出去中文字符),然后直接输出temp的长度即可得到我们想要的字符数
//字符总数 public int Characternum() { //区分是否为中文,中文是@"[\u4e00-\u9fa5]" \u4E00-\u9FA5 MatchCollection mc_chara = Regex.Matches(account_chara, @"[^\u4e00-\u9fa5]*"); string temp = null; int i = 0; while (i < mc_chara.Count) { temp = temp + Convert.ToString(mc_chara[i]); i++; } return temp.Length; }
(4)获取单词以及单词的频数,首先通过d_word.ContainsKey(word[i])获得单词以及单词的频数,然后通过dictionary的key和value进行排序(看你需要如何排序来进行设计)
//单词频数(dictionary,sort) public void Wordfrequency() { //排序之前,将单词存入dictionary Dictionary<string, int> d_word = new Dictionary<string, int>(); int i = 0; while (i < word.Count) { //ContainsKey判断是否存在 if (d_word.ContainsKey(word[i])) { d_word[word[i]]++; } else { d_word[word[i]] = 1; } i++; } //通过dictionary的key和value进行排序 word_num = d_word.OrderByDescending(p => p.Value).ToDictionary(p => p.Key, o => o.Value); }
注意:这里我的参考博客是:http://www.360doc.com/content/18/0425/18/54584204_748693269.shtml
(5)写入文档,这里需要使用到字节流的写入,通过FileStream,StreamWriter进行文件读写
//写入文件 public void Writetofile(string path,string outpath) { //准备(读入文档,单词提取,以及词频的排序) Prep(path); FileInfo file = null; if (outpath == null) { file = new FileInfo(@"D:\VS_practice\wordCount\wordCount\bin\Debug\output.txt"); } else { file = new FileInfo(outpath); } StreamWriter sw = file.AppendText(); sw.WriteLine("字符数:" + Characternum()); sw.WriteLine("单词数:" + Wordnum()); sw.WriteLine("行数:" + Wordlinenum()); Console.WriteLine("字符数为:" + Characternum()); Console.WriteLine("单词数为:" + Wordnum()); Console.WriteLine("行数为:" + Wordlinenum()); //统计前10个高频单词 Writeword(sw,10); //关闭文件 sw.Close(); }
注意:这里文件的写入参考的博客(内含有知识点)是:https://blog.csdn.net/u010159842/article/details/51785613
-- 然后是新功能的接口设计与实现
词组统计、自定义输出采用的是2个函数,多参数是在主函数中实现,这里我们使用到了args[i],我只展示多参数的实现:
//筛选出前10个高频单词 public void Writeword(StreamWriter sw,int n) //输出指定数量的单词数,并写入文件 public void Wordgroupp(StreamWriter sw, int m)
for (int i = 0; i < args.Length; i++) { switch (args[i]) { case "-i": path = args[i + 1];//输入路径 break; case "-o"://-o输出路径 outpath = args[i + 1]; break; case "-m"://-m输出几个高频词 m = args[i + 1]; break; case "-n"://-n输出几个单词的个数 n = args[i + 1]; break; } }
-- 运行结果
(1)程序运行:

(2)cmd输入命令


文件的截图不完整,由于数据太大了。

2.4接口的封装
由于每次都需要调用函数是容易出错的,所以需要进行接口的封装
例如:我的小伙伴在看我的程序的时候,不知道先后顺序,没有进行单词的排序就直接输出含有单词频数的dictionary变量,结果输出为空。
为此我们进行了函数接口的封装,如下所示:
public void Prep(string path) { Getcharacters(path); Withdraword(); Tolower(); Wordfrequency(); }
这是一个准备函数,直接将需要进行的函数进行封装,在我们开始我们的主程序的时候,只需要先调用这个函数即可完成文件的预处理。
再者,我们将函数写在了一个.cs文件里面,将主函数写在一个.cs文件里面,实现了函数的封装,下次直接调用即可。
3、代码互审过程
代码规范(由我们自己制定的,我们两个的博客中相同)
经过参考C#代码规范,我们制定了我们的代码规范:
我们本着“保持简明,让代码更容易读”的原则,让我们更好地理解和维护程序。
代码风格的原则是:简明,易读,无二义性。
1.缩进:4个空格,在VS2017和其他的一些编辑工具中都可以定义Tab键扩展成为几个空格键。不用 Tab键的理由是Tab键在不同的情况下会显示不同的长度。4个空格的距离从可读性来说正好。
2.括号:在复杂的条件表达式中,用括号清楚地表示逻辑优先级。
3.断行与空白的{ }行:每个“{”和“}”都独占一行
如:
if ( condition)
{
DoSomething();
}
else
{
DoSomethingElse();
}
4.分行:不要把多行语句放在一行上。
5.命名:命名方法使用“匈牙利命名法”,在变量面前加上有意义的前缀,就可以让程序员一眼看出变量的类型及相应的语义
例如:
fFileExist,表明是一个bool值,表示文件是否存在;
szPath,表明是一个以0结束的字符串,表示一个路径。
6.下划线问题:下划线用来分隔变量名字中的作用域标注和变量的语义
7.大小写问题:由多个单词组成的变量名,如果全部都是小写,很不易读,一个简单的解决方案就是用大小写区分它们
Pascal——所有单词的第一个字母都大写;
Camel——第一个单词全部小写,随后单词随Pascal格式,这种方式也叫lowerCamel。
一个通用的做法是:所有的类型/类/函数名都用Pascal形式,所有的变量都用Camel形式。
类/类型/变量:名词或组合名词,如Member、ProductInfo等。
函数则用动词或动宾组合词来表示,如gett; RenderPage()。
8.注释:复杂的注释应该放在函数头,养成边写代码边写注释的好习惯
总结:
真的在两个人的项目中我真切的感受到了这个的重要性,刚开始我以为我的代码真的算是规范的了,但是我的小伙伴在看我的代码的时候却还是出现了问题了。
应该是每个人的命名都是会有区别的,我喜欢把关键字写在后面,虽然采用的也是英文命名,但是一个意思的英文单词确实太多了,每次都会有点小差错。
然后我们就自己制定了一个命名规范,并用于我们的小项目当中。
4、接口部分的性能改进
4.1效能分析与改进
首先可以看到我们测出来的代码的性能图,第一个是内存使用率,第二个为CPU使用率: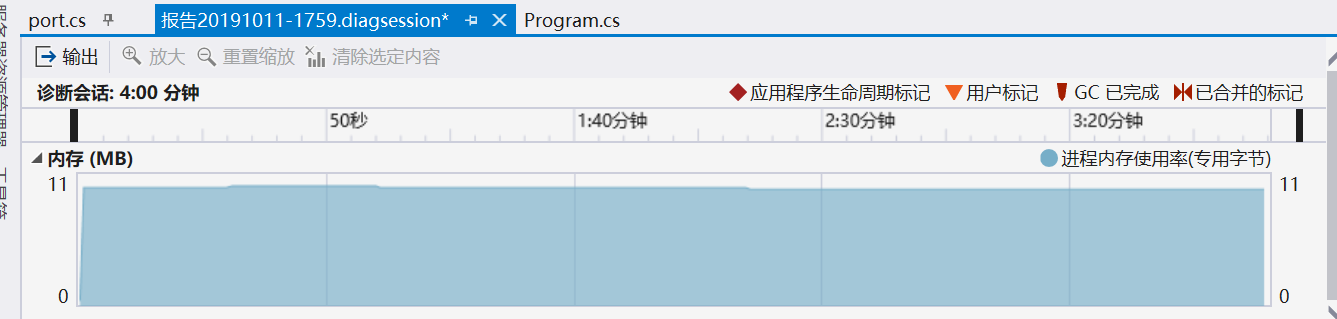
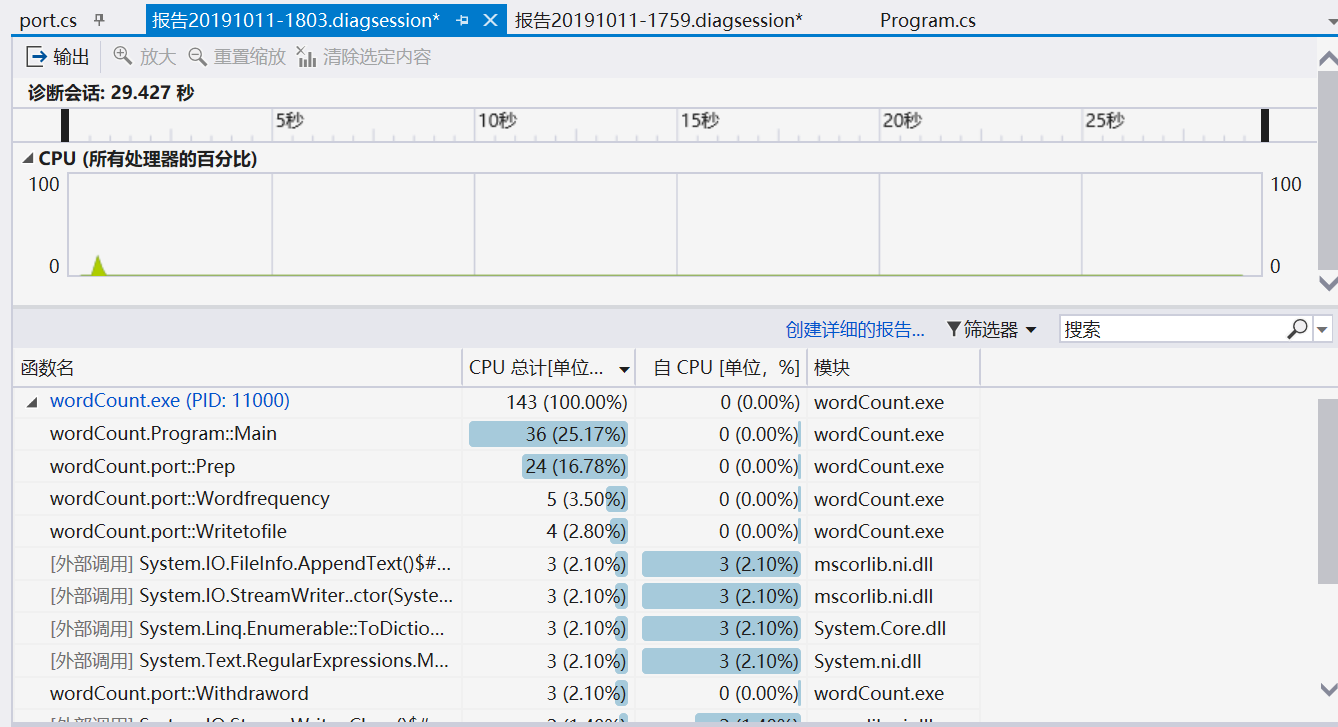
总结(综合我和我的结对小伙伴):
可以看到我们调用主函数的频率是高的,可以看出Main函数中是CPU占比最多的函数,这样子是不太好的,经过我两的一致讨论结果是把主函数简化,确实相比之后是要优化很多的。
于是我们看到main函数,其中在该函数中,我们读取文件、将最后结果放在文件中所花时间、判断命令行中出现的命令选项、判断并打印结果等所花时间都很多,特别是文件的读取过程很慢,因此我们针对文件读取做了很多分析,最后减少了程序对文件的读取的个数使得性能加快。我们就尽量将主函数在调用port.cs里面的函数都统一在一个函数里面,这样就降低 了他的调用频率,其实对于主函数过于庞大我们两个还是有意见的,她希望将指令单独列成一个函数,我坚持写在主函数里面,可能将其列成函数是有一定的优化效果的。
在另一个类port中,WordFrequency()函数占用率最高,因此我们针对WordFrequency()函数进行了分析,WordFrequency()函数中主要拖垮性能的原因是有大量的判断语句,判断d_word字典中的key值,即单词word[i]是否存在,若存在则执行value值加1的操作,若不存在,则将其作为key存入字典并将其value值令为1,因此我们在函数外将我们需要判断的值优先判断,最后再根据其判断值进行value的值操作,加快了程序性能。
4.2接口性能的改进
将主要的准备工作做成一个函数,到时候直接进行一次调用,就可实现初始化效果,这样子还减少了主函数对于其他函数的调用。但是可以看出将其封装为一个函数的时候(Prep),Prep()的调用率是很高的。
5、异常(错误)处理说明
使用try {} catch {} 来进行异常处理:
首先我们需要了解到哪里是需要进行异常处理的,当我们进行输入的时候,或者是需要进行传参的时候,需要我们来检验那些输入和传入的参数是否有效,如果无效则抛出异常。
(1)在文件进行路径读入的时候(判断路径中是否含有文档,-i 与 -o类似):
try { path.Contains(".txt"); } catch { Console.WriteLine("输入的路径不含有txt文件!"); }
(2)指令的输入的时候(判断指令后面的数据是否有效-m 与 -n 的是类似的,这里只列举一个):
try { int test = int.Parse(args[i + 1]); } catch { Console.WriteLine("输入的指令无效"); }
6、单元测试展示
将代码转移到自己的电脑上的时候,出现了一些错误,然后通过调试之后可以运行且无错误。
根据之前的经验我们开始进行单元测试,刚开始的时候还有一些错误(并修改了一些源代码):
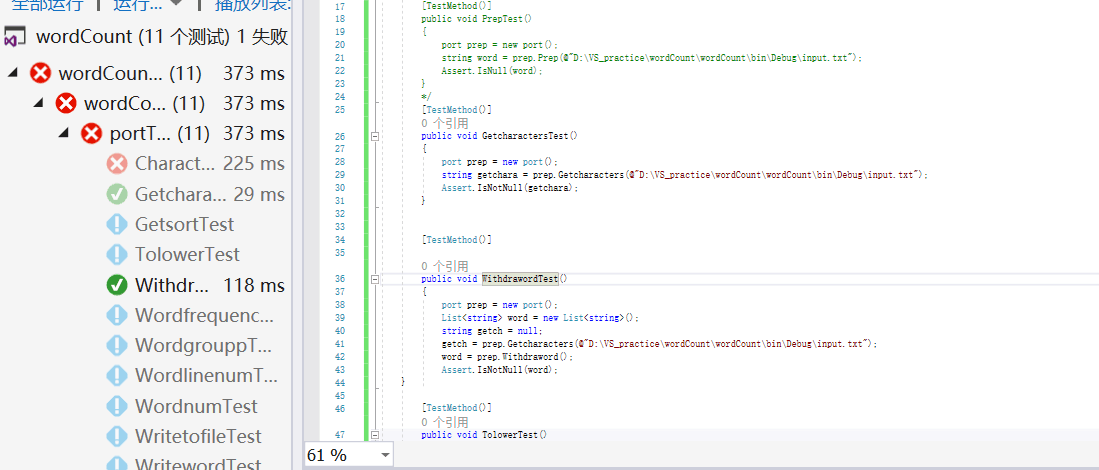
然后通过写单元测试代码,可以看到测试全部都通过了:
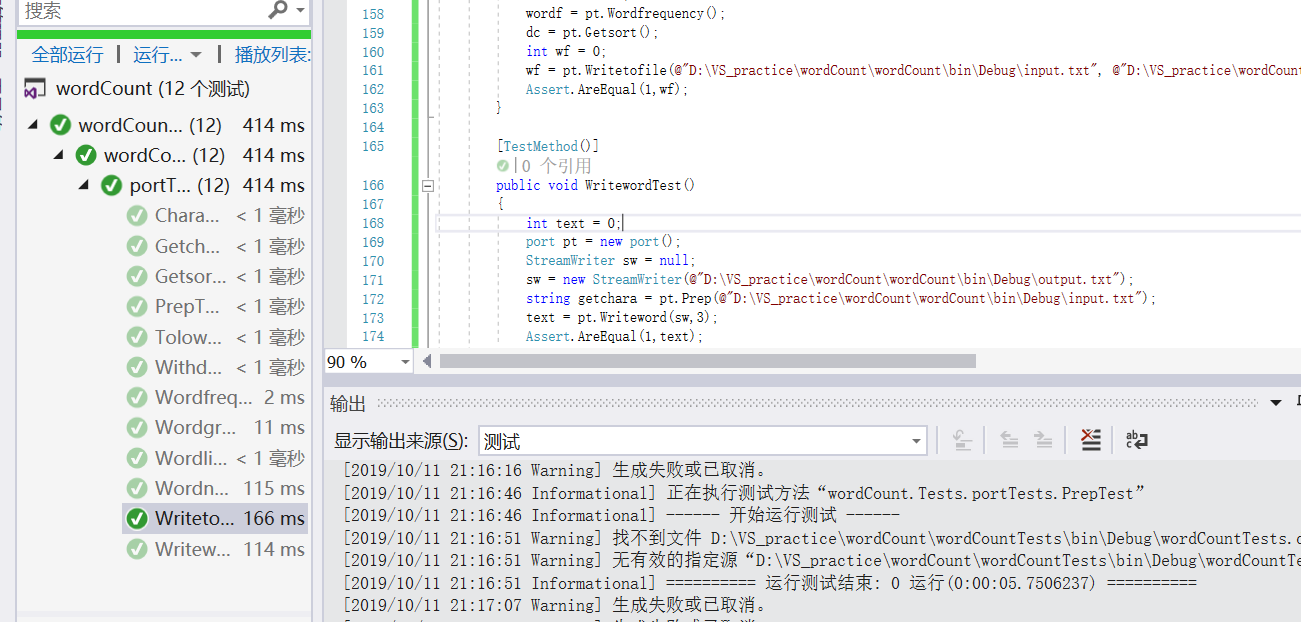
在图片中我们可以看到部分的测试代码,这里就不一一进行解释了。
7、提交项目到GitHub上
将项目git到自己的仓库,再将文件下载下来,再里面创建一个我们两个其中一个的学号的文档(创建的我的),然后将项目放在里面。
通过git bush提交项目(提交命令如下图所示,注意要修改了代码才可以进行提交,每次提交都类似):

之后可以看到我们的提交记录,如下图所示:
三次提交项目:

8、结对过程的描述
项目在我们两个人的努力下就这样完成了,刚开始我们最难的也就是写代码。最初的时候不知道怎么开始,在设计好PSP表格之后,就开始设计函数 。设计好基本函数之后,我们就直接输入输入路径来进行测试 (此时发现了一些代码错误,然后 进行了修改),测试良好。然后就进行命令的输入的设计,通过args来读取得到路径(两个人一起查资料,很快就解决了~)。


8、总结
此次的结对编程感觉还不错,两个的代码能力都一般,刚开始的时候还很无措,但是两个人的解决办法就多了,很多问题在短时间就得到了解决。
总体而言两个人的编程1+1>2的,编代码的时间得到了大大的缩短,两个人的代码测试使得代码的结构更加的稳定,而且代码的编写更为规范了。
在实践的过程中还发现了很多自己的不足之处,觉得自己还是有很多需要改进的地方。

