

一、背景
Hadoop设计之初借鉴GFS/MapReduce的思想:移动计算的成本远小于移动数据的成本。所以调度通常会尽可能将计算移动到拥有数据的节点上,在作业执行过程中,从HDFS角度看,计算和数据通常是同一个DataNode节点,即存在大量的本地读写。
但是HDFS最初实现时,并没有区分本地读和远程读,二者的实现方式完全一样,都是先由DataNode读取数据,然后通过DFSClient与DataNode之间的Socket管道进行数据交互。这样的实现方式很显然由于经过DataNode中转对数据读性能有一定的影响。
社区很早也关注到了这一问题,先后提出过两种方案来提升性能,分别是HDFS-347和HDFS-2246。
HDFS-2246是比较直接和自然的想法,既然DFSClient和DataNode在同一个节点上,当DFSClient对数据发出读请求后,DataNode提供给DFSClient包括文件路径,偏移量和长度的三元组(path,offset,length),DFSClient拿到这些信息后直接从文件系统读取数据,从而绕过DataNode避免一次数据中转的过程。但是这个方案存在两个问题,首先,HDFS需要为所有用户配置白名单,赋予其可读权限,当增加新用户需要更新白名单,维护不方便;其次,当为用户赋权后,意味着用户拥有了访问所有数据的权限,相当于超级用户,从而导致数据存在安全漏洞。
HDFS-347使用UNIX提供的Unix Domain Socket进程通讯机制实现了安全的本地短路读取。DFSClient向DataNode请求数据时,DataNode打开块文件和元数据文件,通过Unix Domain Socket将对应的文件描述符传给DFSClient,而不再是路径、偏移量和长度等三元组。文件描述符是只读的,DFSClient不能随意修改接收到的文件。同时由于DFSClient自身无法访问块所在的目录,也就不能访问未授权数据。
虽然本地短路读在性能上有了明显的提升,但是从全集群看,依然存在几个性能问题:
(1)DFSClient向DataNode发起数据读请求后,DataNode在OS Buffer对数据会进行Cache,但是数据Cache的分布情况并没有显式暴漏给上层,对任务调度透明,造成Cache浪费。比如同一Block多个副本可能被Cache在多个存储这些副本的DataNode OS Buffer,造成内存资源浪费。
(2)由于Cache的分布对任务调度透明,一些低优先级任务的读请求有可能将高优先级任务正在使用的数据从Cache中淘汰出去,造成数据必须从磁盘读,增加读数据的开销从而影响任务的完成时间,甚至影响到关键生产任务SLA。
针对这些问题,社区在2013年提出集中式缓存方案(Centralized cache management)HDFS-4949,由NameNode对DataNode的Cache进行统一集中管理,并将缓存接口显式暴漏给上层应用,该功能在2.3.0发布。这个功能对于提升HDFS读性能和上层应用的执行效率与实时性有很大帮助。
集中式缓存方案的主要优势:
(1)用户可以指定常用数据或者高优先级任务对应的数据常驻内存,避免被淘汰到磁盘。例如在数据仓库应用中事实表会频繁与其他表JOIN,如果将这些事实表常驻内存,当DataNode内存使用紧张的时候也不会把这些数据淘汰出去,可以很好的实现了对于关键生产任务的SLA保障;
(2)由NameNode统一进行缓存的集中管理,DFSClient根据Block被Cache分布情况调度任务,尽可能实现本地内存读,减少资源浪费;
(3)明显提升读性能。当DFSClient要读取的数据被Cache在同一DataNode时,可以通过ZeroCopy直接从内存读,略过磁盘IO和checksum校验等环节,从而提升读性能;
(4)由于NameNode统一管理并作为元数据的一部分进行持久化处理,即使DataNode节点出现宕机,Block移动,集群重启,Cache不会受到影响。
二、部署与使用
2.1 部署
集群开启HDFS集中式缓存特性非常简单,虽然HDFS本身为集中式缓存在NameNode/DataNode端均提供了多个配置参数,但是大多不是必须配置项,最核心的配置项是DataNode侧一个参数。
hdfs-site.xmlhdfs-default.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
|
|
如配置项描述所述,该配置的默认值为0,表示集中式缓存特性处于关闭状态,选择适当的值打开该特性。
开启集中式缓存特性需要注意两个前提:
(1)DataNode的native库必须可用;因为集中式缓存特性通过系统调用mmap/mlock实现,DataNode需要通过native库支持完成系统调用,否则会导致该特性不生效。
(2)系统memlock至少与配置值相同;因为集中式缓存特性通过系统调用mmap/mlock实现,所以系统最大锁定内存空间需要至少与DataNode配置的锁定空间大小相同,否则会导致DataNode进行启动失败。
此外,HDFS还包括了其他可选的配置项:
hdfs-site.xmlhdfs-default.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
|
2.2 使用
HDFS集中式缓存对数据读写接口并没有影响,正常调用已缓存数据的读写即可使用缓存特性。 为了便于数据管理,HDFS通过CacheAdmin对外暴露了一系列缓存管理的接口,其中CLI接口如下。
CacheAdmin
1
2
3
4
5
6
7
8
9
10
11
|
|
CacheAdmin主要对用户暴露的是对缓存数据/缓存池(在系统架构及原理进行详细解释)的增删改查功能,另外还提供了相关的缓存策略,供用户灵活使用。
如这里期望能够缓存数据仓库中被频繁访问的user表数据:
CacheAdmin CLI
1
2
|
|
首先新建名称为factPool的缓存池,并赋予相关的用户组及权限等信息,另外限制该缓存池可以缓存的最大空间及缓存数据的最大TTL等;
然后将user表数据加入到缓存池factPool进行缓存,并指定缓存时间为1天,缓存3个副本;
之后当有读user表数据的请求过来后即可调度到缓存节点上从内存直接读取,从而提升读性能。其它CLI的用法可类比这里不再一一罗列。
2.3 适用场景
当前内存相比HDD成本还比较高,另外对于Hadoop集群,节点的内存大部分是分配给YARN供计算使用,所以剩余的内存资源其实非常有限,能够提供给HDFS集中式缓存使用的部分更少,为了使有限的资源发挥出最好的效率,这里提供几点建议:
(1)数据仓库中存在一部分事实表被频繁访问,与其他事实表/维度表JOIN,将访问频率较高的部分事实表进行缓存,可以提高数据生产的效率;
(2)根据局部性原理,最近写入的数据最容易被访问到,从数据仓库应用来看,每天有大量报表统计任务,需要读取前一天数据做分析,事实上大量表都是按天进行分区,可以把符合要求的热点分区数据做缓存处理,过期后清理缓存,也能大幅提升生产和统计效率;
(3)资源数据,当前存在非常多的计算框架依赖JAR/SO等一些公共资源,传统的做法是将这些资源数据写入到HDFS,通过Distributed Cache进行全局共享,也便于管理,如Spark/Tez/Hive/Kafaka等使用到的公共JAR包。如果将这部分资源数据进行长期缓存,可以优化JVM初始化时间,进而提升效率;
(4)其他;
三、系统架构及原理
3.1 架构
设计文档中定义集中式缓存机制(Centralized cache management):
An explicit caching mechanism that allows users to specify paths to be cached by HDFS.
其中包含了若干具体的目标:
Strong semantics for cached paths
Exposing cache state to framework schedulers
Defer cache policy decisions to higher level frameworks
Backwards compatibility
Management, debugging, metrics
Security
Quotas
为了实现上述目标,首先引入两个重要的概念:CacheDirective,CachePool。其中CacheDirective定义了缓存基本单元,本质上是文件系统的目录或文件与具体缓存策略等属性的集合;为了便于灵活管理,将属性类似的一组CacheDirective组成缓存池(CachePool),在缓存池CachePool上可以进行权限、Quota、缓存策略和统计信息等灵活控制。
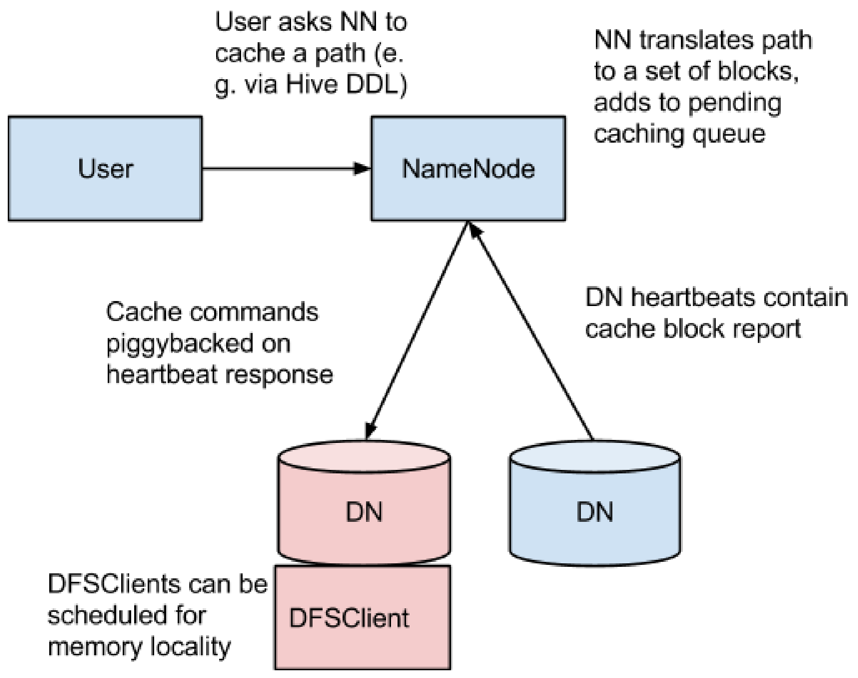
在具体展开集中式缓存的系统架构和原理前,首先梳理对CacheDirective缓存的详细流程,具体如图1:
(1)用户通过调用客户端接口向NameNode发起对CacheDirective(Directory/File)缓存请求;
(2)NameNode接收到缓存请求后,将CacheDirective转换成需要缓存的Block集合,并根据一定的策略并将其加入到缓存队列中;
(3)NameNode接收到DataNode心跳后,将缓存Block的指令下发到DataNode;
(4)DataNode接收到NameNode发下的缓存指令后根据实际情况触发Native JNI进行系统调用,对Block数据进行实际缓存;
(5)此后DataNode定期(默认10s)向NameNode进行缓存汇报,更新当前节点的缓存状态;
(6)上层调度尽可能将任务调度到数据所在的DataNode,当客户端进行读数据请求时,通过DFSClient直接从内存进行ZeroCopy,从而显著提升性能;
HDFS集中式缓存的架构如图2所示,这里主要涉及到NameNode和DataNode两侧的管理和实现,NameNode对数据缓存的统一集中管理,并根据策略调度合适的DataNode对具体的数据进行数据的缓存和置换,DataNode根据NameNode的指令执行对数据的实际缓存和置换。
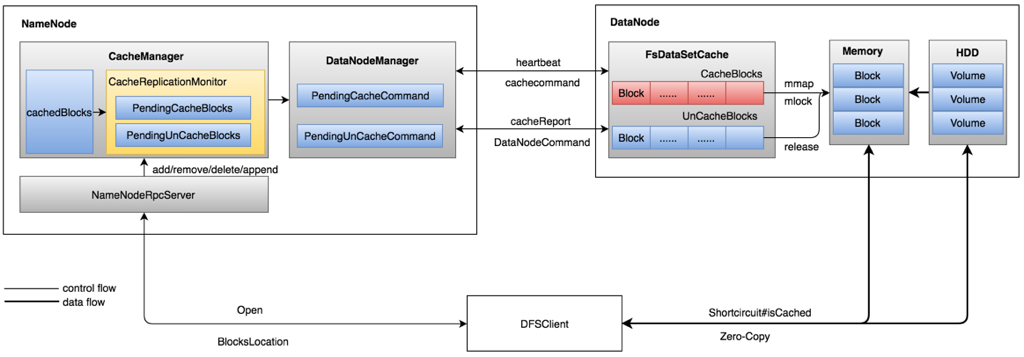
3.2 DataNode
DataNode是执行缓存和置换的具体执行者,具体来说即cacheBlock和uncacheBlock调用。FsDatasetImpl#FsDatasetCache类是该操作的执行入口。
Manages caching for an FsDatasetImpl by using the mmap(2) and mlock(2) system calls to lock blocks into memory. Block checksums are verified upon entry into the cache.
FsDatasetCache的核心是称为mappableBlockMap的HashMap,用于维护当前缓存的Block集合,其中Key为标记该Block的ExtendedBlockId,为了能够实现与Federation的兼容,在blockid的基础上增加了blockpoolid,这样多个blockpool的block不会因为blockid相同产生冲突;Value是具体的缓存数据及当前的缓存状态。
FsDatasetCache#mappableBlockMap
1
|
|
mappableBlockMap更新只有FsdatasetCache提供的两个具体的函数入口:
FsDatasetCache.java
1
2
|
|
可以看出,对mappableBlockMap的并发控制实际上放在了cacheBlock和uncacheBlock两个方法上,虽然锁粒度比较大,但是并不会对并发读写带来影响。原因是:cacheBlock在系统调用前构造空Value结构加入mappableBlockMap中,此时该Value维护的Block状态是CACHING,之后将真正缓存数据的任务加入异步任务CachingTask去完成,所以锁很快会被释放,当处于CACHING状态的Block被访问的时候会退化到从HDD访问,异步任务CachingTask完成数据缓存后将其状态置为CACHED;uncacheBlock是同样原理。所以,虽然锁的粒度比较大,但是并不会阻塞后续的数据缓存任务,也不会对数据读写带来额外的开销。
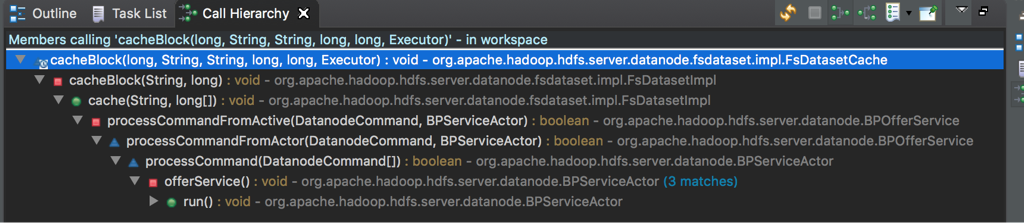
顺着自底向上的思路,再来看触发cacheBlock和uncacheBlock的场景,通过函数调用关系容易看到缓存和置换的触发场景都比较简单。
(1)cacheBlock:唯一的入口是从ANN(HA Active NameNode)下发的指令;
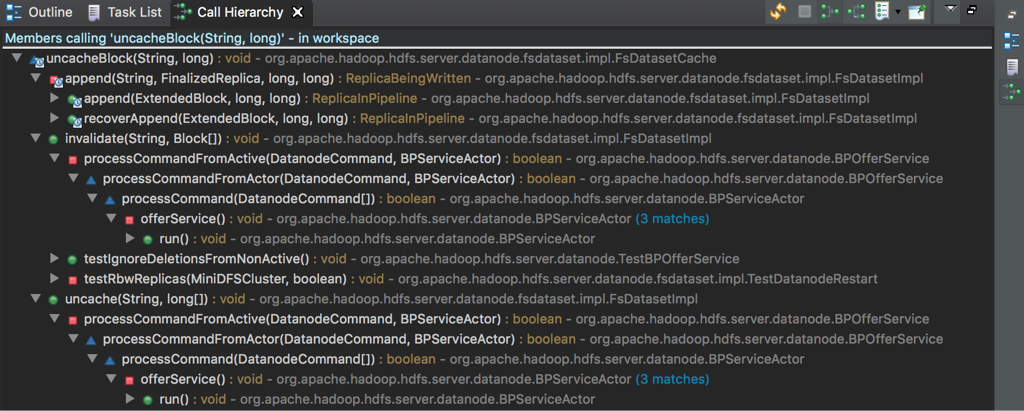
(2)uncacheBlock:与cacheBlock不同,uncacheBlock存在三个入口:append,invalidate和uncache。其中uncache也是来自ANN下发的指令;append和invalidate触发uncacheBlock的原因是:append会导致数据发生变化,缓存失效需要清理后重新缓存,invalidate来自删除操作,缓存同样失效需要清理。
DataNode的处理逻辑比较简单,到这里整个实现的主路径基本梳理完成。
3.3 NameNode
相比DataNode的实现逻辑,NameNode侧要复杂的多,缓存管理继承了NameNode一贯的模块化思路,通过CacheManager实现了整个集中式缓存在管理端的复杂处理逻辑。
CacheManager通过几个关键数据结构组织对数据缓存的实现。
CacheManager.javagithub
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
|
通过上述的几个核心集合类数据结构,很容易实现用户层对缓存数据/缓存池的增删改查功能调用的支持。
虽然上述的几个核心集合类数据结构能够容易支持用户对相关接口的调用,但是从整个集中式缓存全局来看,并没有将用户调用接口对目录/文件的缓存同DataNode实际数据缓存建立起有效连接。CacheReplicationMonitor发挥的即是这种作用,CacheReplicationMonitor使得缓存接口调用、核心数据结构以及数据缓存真正有序流动起来。
如果对BlockManager#ReplicationMonitor比较熟悉的话,可以发现CacheReplicationMonitor的工作模式几乎从ReplicationMonitor复制而来,CacheReplicationMonitor本质上也是一个定时线程,与ReplicationMonitor稍微不同的是,CacheReplicationMonitor除了定时触发外用户的缓存调用也会触发。其核心是其rescan方法,具体来看主要做三个具体工作:
(1)resetStatistics:对CacheManager从CacheDirective和CachePool两个维度对统计信息进行更新;
(2)rescanCacheDirectives:顺序扫描CacheManager#directivesById数据结构(与CacheManager#directivesByPath实际上等价),检查哪些CacheDirective(目录或文件)需要进行cache处理,一旦发现有文件需要进行缓存,立即将该文件的所有Block加入到CacheReplicationMonitor#cachedBlocks(GSet<CachedBlock, CachedBlock> cachedBlocks)中,后续工作由rescanCachedBlockMap接着进行;
(3)rescanCachedBlockMap:顺序扫描CacheReplicationMonitor#cachedBlocks的所有CacheBlock,由于CacheBlock也有副本个数的概念,rescanCachedBlockMap在扫描的过程中会发现实际缓存的Block副本数与预设的缓存副本有差异,比如新增缓存请求/节点宕机/心跳异常/节点下线等等导致Cache Block副本数与期望值之间产生差异,所以需要CacheReplicationMonitor进行周期检查和修复,根据差异多少关系将对应的CacheBlock加入到DatanodeManager管理的对应DatanodeDescriptor#{pendingCached,pendingUncached}数据结构中,待对应的DataNode心跳过来后将其转化成对应的执行指令下发给DataNode实际执行。关于心跳与指令下发的细节已经在之前文章中多处提到,这里不再展开。
这里还遗留一个问题,由于Block与CacheBlock均存在多副本的关系,如何选择具体的DataNode执行缓存或置换。
(1)uncacheBlock:uncacheBlock选择对应的DataNode其实比较简单,顺序遍历所有已经缓存了该Block的DataNode,为其准备uncacheBlock指令,直到缓存副本达到预期即可;
(2)cacheBlock:cacheBlock稍微复杂,先从Block副本所在的所有DataNode集合中排除DecommissionInProgress/Decommissioned/CorruptBlock所在DataNode/已经缓存了该Block的DataNode之后,在剩下的DataNode集合中随机进行选择即可。
DataNode实际执行完成NameNode下发的cacheBlock/uncacheBlock指令后,在下次cacheReport(默认时间间隔10s)汇报给NameNode,CacheManager根据汇报情况对缓存执行情况对CacheManager#cachedBlocks进行更新。
至此,NameNode端的集中式缓存逻辑形成了合理有效的闭环,基本实现了设计目标。
3.3 DFSClient
客户端本身的读数据逻辑基本没有变化,与传统的读模式区别在于,当客户端向DataNode发出REQUEST_SHORT_CIRCUIT_FDS请求到达DataNode后,DataNode会首先判断数据是否被缓存,如果数据已经缓存,将缓存信息返回到客户端后续直接进行内存数据的ZeroCopy;如果数据没有缓存采用传统方式进行ShortCircuit-Read。
四、总结
通过前述分析,可以看到HDFS集中式缓存优势非常明显:
1、显著提升数据读性能;
2、提升集群内存利用率;
虽然优势明显,但是HDFS集中式缓存目前还有一些不足:
1、内存置换策略(LRU/LFU/etc.)尚不支持,如果内存资源不足,缓存会失败;
2、集中式缓存与Balancer之间还不能很好的兼容,大量的Block迁移会造成频繁内存数据交换;
3、缓存能力仅对读有效,对写来说其实存在副作用,尤其是Append;
4、与Federation的兼容非常不友好;
总之,内存模式在存储和计算的多个方向上已经成为业界广泛关注的方向和趋势,Hadoop社区也在投入精力持续在内存上发力,从集中式缓存来看,收益非常明显,但是还存在一些小问题,在实际应用过程中还需要优化和改进。
#创建缓存组,默认为cache_data
hdfs cacheadmin -addPool cache_data -mode 0777
Successfully added cache pool cache_data.
#生成一个1GB大小的文件
dd if=/dev/zero of=/tmp/test.zero bs=1M count=1024
+0 records in
+0 records out
24 bytes (1.1 GB) copied, 1.25545 s, 855 MB/s
hdfs dfs -put /tmp/test.zero /data
#生成缓存指令
hdfs cacheadmin -addDirective -path /data -pool cache_data -ttl 1d
Added cache directive 1
#显示缓存池的信息
hdfs cacheadmin -listPools -stats cache_data
Found 1 result.
NAME OWNER GROUP MODE LIMIT MAXTTL BYTES_NEEDED BYTES_CACHED BYTES_OVERLIMIT FILES_NEEDED FILES_CACHED
cache_data hdfs hdfs rwxrwxrwx unlimited never 1073741824 1073741824 0 1 1
#统计信息,显示EXP Date
hdfs cacheadmin -listDirectives -path /data
Found 1 entry
ID POOL REPL EXPIRY PATH
cache_data 1 2014-12-22T15:38:31+0800 /data
#删除缓存指令和缓存池
hdfs cacheadmin -removeDirectives -path /data
Removed cache directive 1
Removed every cache directive with path /data
hdfs cacheadmin -removePool cache_data
Successfully removed cache pool cache_data.
