为什么Deep Deterministic Policy Gradient(DDPG)是Deterministic的?到底哪里体现了?和PPO什么区别?
Deep Deterministic Policy Gradient (DDPG) 是“Deterministic”(确定性)的,因为它使用了一个确定性策略网络,而不是像传统的强化学习算法(例如,基于策略梯度的算法)那样使用随机策略网络。
具体来说,DDPG 使用的是一个确定性策略函数,通常表示为 𝜇(𝑠),它在给定状态 𝑠时输出一个具体的动作 𝑎,而不是一个动作的概率分布(像策略梯度方法中那样)。这意味着对于每个状态,DDPG 只会选择一个确定的动作,而不是从动作分布中随机抽取动作。
为什么是确定性的?
1、策略定义:在 DDPG 中,策略被定义为一个确定性映射。即,给定一个状态,策略会输出一个具体的动作:
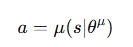
其中 \(𝜇(𝑠∣𝜃^\mu)\)是由神经网络定义的,给定输入状态 𝑠后直接输出一个确定的动作。
2、动作选择:DDPG 使用的 Actor-Critic 架构中的 Actor 部分通过确定性策略生成动作,而 Critic 网络则估计动作值函数(Q-value)。
3、动作探索:虽然 DDPG 本身是基于确定性策略的,但为了在训练时进行探索,DDPG 会通过向输出动作添加噪声(通常是 Ornstein-Uhlenbeck 噪声)来引入一定程度的随机性。这个噪声帮助智能体探索环境,但本质上,策略本身仍然是确定性的。
DDPG与随机策略的区别:
随机策略:在其他强化学习算法(例如$ REINFORCE $或 \(PPO\))中,策略网络通常会输出一个动作的概率分布,智能体从这个分布中采样动作。这意味着在相同的状态下,可能会选择不同的动作,每次选择都是随机的。
确定性策略:在 DDPG 中,策略网络输出的是一个特定的动作(而不是概率分布),因此对于相同的状态,智能体总是选择相同的动作。
这种确定性策略的好处是,DDPG 在连续动作空间中的应用效率较高,尤其是在像机器人控制或自动驾驶等任务中,选择一个精确的动作是非常重要的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号