
第04章 分布式索引架构
本章内容
如何为集群选择合适的分片数和副本数。
路由是什么以及它对ElasticSearch的意义。
分片分配器是怎样工作的,如何配置它。
怎样调节分片分配机制以满足应用需求。
怎样确定应该在哪个分片上执行指定的操作。
怎样结合我们已有的知识来配置一个真实的集群。
如何应对数据和查询数量的增长。
4.1 选择合适的分片和副本数
简单的计算公式如下:
节点最大数=分片数*(副本数+1)换句话说,如果你计划使用10个分片和2个备份,那么这个设置的最大节点数将会是30.
4.1.2 一个过度分配的正面例子
如果你仔细阅读了本章前面的内容,就会强烈地意识到:我们应该使用最少的分片。 但有时候拥有更多的分片有其便利之处,因为分片事实上是lucene的一个索引。更多的分 片意味着每个在较小的lucene索引上执行的操作会更快(尤其是索引过程)。有时这是一个使用更多分片的很好的理由。当然,将查询分散成对每个分片的请求,然后合并结果。也是有代价的,但这对于使用固定参数来过滤查询的应用程序是可以避免的。有这种现实的案例,例如,那种每个查询都在指定用户的上下文中执行的多租户系统。原理很简单,即把每个用户的数据都索引到一个独立分片中,在查询时只查询那个用户的分片。这时就需要使用路由(我们将在4.2节中详细讨论它)。
4.1.4 副本
分片处理使我们能存储超过单机容量的数据,而使用副本则解决了日渐增长的吞吐量 和数据安全方面的问题。当一个存放主分片的节点失效后,ElasticSearch能够将一个可用的副本升级为新的主分片。默认情况下,ElasticSearch只创建一个副本。然而,不同于分片处理,副本的数量可以通过使用相关API随时更改。该功能让构建应用程序变得非常方便, 因为查询吞吐量会随着用户的增长而增长,而使用副本则可以应对增长的并发查询。使用过多副本的缺点也很明显:各个分片的副本占用了额外的存储空间,主分片及其副本之间的数据拷贝也存在时间开销。
4.2 路由
4.2.1 分片和数据
引言
通常情况下,ElasticSearch将数据分发到哪个分片,以及哪个分片上存放特定的文档 都不重要。查询时,请求会被发送至所有的分片,所以最关键的事情是使用一个能均匀分发数据的算法。而当我们想删除文档或者增加一个文档的新版本时,情况就有些复杂了,ElasticSearch必须知道文档在哪里。实际上,这并不是一个问题,只要分片算法能对同一个文档标识符永远生成相同的值就足够了,如此ElasticSearch在处理文档时就知道该去找对应的分片了。
难道没有一个更智能的方法来决定文档应当储存在哪个分片上吗?举例来说,我们希望将某一类书籍都存在一个特定的分片上,因而在查询这类书时就无需查询多个分片及合并搜索结果。这就是路由要做的事情。它允许我们提供信息给ElasticSearch, 而ElasticSearch根据这个信息来决定用哪个分片来存储文档和执行查询。相同的路由值会指向同一个分片、也就是说“之前你使用某个路由值将文档存放在特定的分片上,那么搜索时,也去相应的分片查找该文档”。
4.2.2 测试路由功能
现在启动两个ElasticSearch节点,然后用下面的命令创建一个索引:
curl -XPUT localhoat:9200/documents -d'{
settings:{
number_of_replicas:0,
number_of_shards:2
}
}'在索引过程中使用路由
我们可以通过路由来控制ElasticSearch将文档发送到哪个分片。路由参数值无关紧要, 可以取任何值。重要的是在将不同文档放到同一个分片上时,需要使用相同的值。
第一种方法:URI参数
向ElasticSearch提供路由信息有多种途径。最简单的办法是在索引文档时加一个URI 参数routing。例如下面的例子:
curl -XPUT localhoat:9200/documents/doc/1?routing=A -d'{
"title":"Document"
}'第二种方法:基于Mapping
另一个选择是在文档里放一个_routing字段,如下所示:
curl -XPUT localhoat:9200/documents/doc/1 -d'{
"title":"Document No. 1",
"_routing":"A"
}'然而这种情况仅在mappings中定义了_routing字段时才会生效。例如:
{
"mappings":{
"doc":{
"_routing":{
"required":true,
"path":"_routing"
},
"properties":{
"title":{
"type":"string"
}
}
}
}
}在这里稍微停顿一下。在这个例子里我们使用了_routing字段,且值得一提的是,path 参数可以指向文档中任意未分词字段。这是一个十分强大的功能,也是路由特性最主要的优势所在。举例来说,如果我们用代表图书所在图书馆的library_id字段扩展文档,那么当基于library_id来设置路由时,有理由认为所有基于图书馆的查询更有效率。
第三种方法:匹配插入指定路由
现在回到定义路由的多种途径上。最后一种方式是在执行批量索引时使用路由。使用 时路由值在每个文档的头部给出,例如:
curl -XPUT localhost:9200/_bul --data-binary '
{
"index":{
"_index":"documents",
"_types":"doc",
"_routing":"A"
}
}
{
"title":"Document No. 1"
}
'4.2.3 索引时使用路由
仍然使用前面的例子,只是这次使用路由。首先要删除旧文档,如果不这么做,那么 使用相同的标识符添加文档时,路由会把相同的文档存放到另一个分片上。因此,我们执行下面的命令从索引中删除所有文档:
curl -XDELETE localhost:9200/documents/_query?q=*:*然后重新索引数据,但是这次添加路由信息。索引文档的命令如下:

标识符优先于路由!
路由参数指示ElasticSearch应该将文档放到哪个分片上。当然,这并不是说拥有不同 路由值的文档就会放到不同的分片上。
查询
路由允许用户构建更有效率的查询,并且用户也可以使用路由。
curl -XGET 'localhost:9200/documents/_search?pretty&q=*:*&routing=A'路由是优化集群的一个很强大的机制。它能让我们根据应用程序的逻辑来部署文档, 从而可以用更少的资源构建更快速的查询。
然而,有件重要的事情需要再强调一下。路由确保了在索引时拥有相同路由值的文档会索引到相同的分片上,但一个给定的分片上可以有很多拥有不同路由值的文档。路由可以限制查询时使用的节点数,但是不能替代过滤功能。这意味着无论一个查询有没有使用路由都应该使用相同的过滤器。
4.2.4 别名
一个简化了的路由功能
让程序员们可以快速地工作而不必关心搜索细节。在理 想的世界里,他们不需要担心路由、分片、副本。而别名就能让我们像使用普通索引那样使用路由。例如,用下面的命令创建一个别名:
curl -XPOST 'http://localhost:9200/_aliases' -d '
{
"actions":[
{
"add":{
"index":"documents",
"alise":"documentsA",
"routing":"A"
}
}
]
}'我们创建了一个叫doucmentsA的虚拟索引(一个别名),用来代表来自doucments索引 的信息。然而,除了这个,查询被限定在路由值A相关的分片上。感谢这个功能,你可以将别名documentsA的信息提供给开发者,并用它进行查询和索引,就像其他索引一样。
4.2.5 多个路由值
就像查询多个索引一样
ElasticSearch允许我们在一次查询中使用多个路由值。文档放置在哪个分片上依赖于 文档的路由值,多路由值查询意味着在一个或多个分片上查询。我们看看下面的查询:
curl -XGET 'localhost:9200/documents/_search?routing=A,B'当然,多路由值也支持别名。下面的例子展示了如何使用这些特性:
curl -XPOST 'http://localhost:9200/_aliases' -d '
{
"actions":[
{
"add":{
"index":"documents",
"alise":"documentsA",
"search_routing":"A,B",
"index_routing":"A"
}
}
]
}'上面的例子里有两个额外的配置参数是我们之前没有提到过的,我们可以为查询和索 引配置不同的路由。例子中,我们定义在查询时(search_routing参数)使用两个路由值(A和B),而索引时(index_routing参数)仅使用了一个路由值(A)。
4.3 调整默认的分片分配行为
ElasticSearch给我们提供了使用特定分片 部署策略来构建先进系统的可能性。在本节中,我们将深人探讨关于分配分片的其他选择。
4.3.1 分片分配器简介
ElasticSearch提供了下面两 种类型的分配器:
- even shard
- balanced(默认)
通过在elasticsearch.yml中设置cluster.rounting.allocation.type属性或者使用设置API 我们可以指定具体的分配器实现。让我们进一步了解前面提到的分配器类型。
4.3.2 even shard
它能确保每个节点上具有相同数 量的分片(当然,并不是总能满足这样的情形),同时也能禁止主分片及其副本存储在同一 节点上。在需要重新分配且使用even shard分片分配器时,ElasticSearch从存储负载最高的节点向存储负载较低的节点移动分片,直到集群完全平衡或者无法移动。需要注意的是,这个分配器并排工作在索引级别。这意味着只要分片及其副本在不同的节点上,分配器就认为工作正常,而不关心来自同一索引的不同分片存放到哪里。
4.3.3 balanced分片分配器
这个分配器是在ElasticSearch 0.90.0版本以后新引人的。它基于一些可控制的权重进 行分配。相比前面讨论过的even shard分片分配器,它通过暴露一些参数而引入调整分配过程的能力,从而使我们可以通过使用集群更新API ( update API)来动态改变这些参数。
可调整的参数如下所示:
- cluster.routing.allocation.balance.shard:默认值为0.45.
- cluster.routing.allocation.balance.index:默认值为0.5.
- cluster.routing.allocation.balance.primary默认值为0.05.
- cluster.routing.allocation.balance.threshold:默认值为1.0.
第一个参数告诉ElasticSearch每个节点都分配数量相近的分片对我们有多么重要。
第二个参数类似,但不是基于所有的分片数,而是基于同一个索引的分片数。
第三个参数告诉ElasticSearch将主分片平均分配到节点有多么重要。
最后,如果所有因子与其权重的乘积的总和大于已定义的阂值,那么这类索引上的分 片就需要重新分配了。而如果出于某些原因,你希望忽略一个或多个因子,只要把它们的权重设为0就可以了。
4.3.5 裁决者
为了理解分片分配器是如何决定分片移动的时机和目标节点,我们需要讨论一下 ElasticSearch内部的裁决者(decider),它们是做出分配决定的大脑。ElasticSearch允许同时使用多个裁决者,而且它们会在决策过程中投票。这里有一个规则共识,例如,如果某裁决者投票反对重新分配一个分片的操作,那么该分片就不能移动。裁决者只有固定的十来个,如果想添加新的决策者,只能通过修改ElasticSearch源码。
-
SameShardAllocationDecider
顾名思义,该裁决者禁止将相同数据的拷贝(分片和其副本)放到相同的节点上。注意属性 cluster.routing.allocation.same_shard.host属性。它控制了ElasticSearch 是否需要考虑分片放到物理机器上的位置。它默认为false,因为许多节点可能运行在同一台运行着多个虚拟机的服务器上。而当设置成true时,这个裁决者会禁止将分片和其副本 放置在同一台物理机器上。 -
ShardsLimitAllocationDecider
ShardsLimitAllocationDecider确保一个给定索引在某节点上的分片不会超过给定 数量。这个数量是由index.routing.allocation.total_ shards_per_node属性控制的,可以在elasticsearch.yml文件中设置,或者通过索引更新API在线更新。属性的默认值是-1,表明没有限制。 -
FiIterAllocationDecider
-
RepIicaAfterPrimaryActiveAllocationDecider
这个裁决者使得ElasticSearch仅在主分片都分配好之后才开始分配副本。 -
ClusterRebalanceAllocationDecider
ClusterRebalanceAllocationDecider允许根据集群的当前状态来改变集群进行重新平衡 的时机。该裁决者可以通过cluster.routing.allocation.allow_rebalance属性来控制,它支持以下这些值:
indices_all_active :这个默认值表明重新平衡仅在集群中所有已存在的分片都分配好后才能进行。
indices_primaries_active:这个设置表明重新平衡只在主分片分配好以后才进行。
always:这个设置表明重新平衡总是可以进行,甚至在主分片和副本还没有分配好 时也可以。注意这些设置在运行时不能更改。
-
ConcurrentRebalanceAllocationDecider
ConcurrentRebalanceAllocationDecider用于调节重新部署操作,并基于cluster.routing. allocation.cluster_concurrent_rebalance属性。在该属性的帮助下,我们可以设置给定集群上可以并发执行的重新部署操作的数量,默认是2个,意味着在集群上只有不超过2个的分片可以同时移动。把这个值设为-1将没有限制。 -
DisabIeAlIocationDecider
DisableAllocationDecider是一个可以调整自身行为来满足应用需求的裁决者。有以下配置
cluster.routing.allocation.disable_allocation:这个设置允许我们禁止所有的分配。
cluster.routing.allocaiotn.disable_new_allocation:这个设置允许我们禁止新主分片的分配。
cluster.routing.allocation.disable_replica_allocation:这个设置允许我们禁止副本的分配。
所有这些设置的默认值都是false。它们在你想要完全控制分配时非常有用。例如,当 你想要快速地重新分配和重新启动一些节点时,便可以禁止重新分配。另外请记住尽管你可以在elasticsearch.yml文件里设置前面提到的那些属性,但这里使用更新API会更有意义。利用该配置可快速重启节点,而不进行分片分配
-
AwarenessAllocationDecider
AwarenessAllocationDecider是用来处理意识部署功能的。无论什么时候使用了cluster. routing.allocation.awareness.attributes设置,它都会起作用。更多关于它是如何工作的信息可参见4.4节内容。 -
ThrottlingAllocationDecider
ThrottlingAllocationDecider与前面讨论过的ConcurrentRebalanceAllocationDecider类 似,该裁决者允许我们限制分配过程产生的负载。我们可以使用下面的属性控制恢复过程:
cluster.routing.allocation.node_initial_primaries_recoveries:参数值默认为4。它描述了单节点所允许的最初始的主分片恢复操作的数量。
cluster.routing.allocation.node_concurrent_recoveries:参数值默认为2。它定义了单节点上并发恢复操作的数量。 -
RebalanceOnlyWhenActiveAllocationDecider
-
DiskThresholdDecider
DiskThresholdDecide:在ElasticSearch的0.90.4版本里引人,它允许我们基于服务器上 的空余磁盘容量来部署分片。默认它是禁用的,因而必须设置cluster.routing.allocation.disk.threshold_enabled属性为true来启用它。该裁决者允许我们配置一些阈值,以决定何时将分片放到某个节点上以及ElasticSearch应该何时将分片迁移到另一个节点上。
cluster.routing.allocation.disk.watermark.low:属性允许我们在分片分配可用时指定一个 阀值或绝对值。例如,默认值是0.7,这告诉Elasticsearch新分片可以分配到一个磁盘使用率低于70%的节点上。
cluster.routing.allocation.disk.watermark.high:属性允许我们在某分片分配器试图将分片 迁移到另一个节点时指定一个阀值或绝对值:‘默认值是0.85,意味着ElasticSearch会在磁盘空间使用率上升到85%时重新分配分片。
cluster.routing.allocation.disk.watermark.low和cluster.routing.allocation.disk.watermark. high这两个属性都可以设置成百分数(如0.7或0.85 ),或者绝对值(如1 OOOmb )。另外,本节提到的所有属性都可以在 elasticsearch.yml里静态设置,或使用ElasticSearch API动态更新。
4.4 调整分片分配
我们的集群由4个节点构成,每个节点都绑定了一个指定的IP地址,而 且都被赋予了一个tag属性和一个group属性(在elasticsearch.yml文件里对应的是node.tag和node.group属性)。这个集群用来展示分片分配的过滤处理是如何工作的。

4.4.1 部署意识
部署意识允许我们使用通用参数来配置分片及其副本的部署。 我们在elasticsearch.yml文 件里加人下列属性:
cluster.routing.allocation.awareness.attributes:group这会告诉ElasticSearch使用node.group属性作为意识参数。
然后,我们先启动前两个节点,即node.group属性值是groupA的那两个。接下来用下 而的命令创建一个常引:
curl -XPOST 'localhoat:9200/mastering' -d '
{
"settings":{
"index":{
"number_of_shards":2,
"number_of_replicas":1
}
}
}'执行前面的命令后,两个节点的集群看起来类似于下面的截图:

如你所见,索引平均部署到了两个节点上。现在我们来看看换成另外两个节点时会发 生什么(node.group设置成groupB的那两个):

换成另外两个节点意思应该是启动另外两个节点。
请注意区别:主分片没有从原来部署的节点上移动,但是副本分片却移动到了有不同 node.group值的节点上。这恰恰是对的。当使用分片部署意识的时候,ElasticSearch不会将分片和副本放到拥有相同属性值(用来决定部署意识,如例子中的node.group)的节点上。 例如从虚拟机或物理位置的角度分割集群的拓扑结构,以确保不会有单点故障。
在使用部署意识的时候,分片不会被部署到没有设定指定属性的节点上所以对我 们的例子来说,一个没有设置node.group属性的节点是不会被部署机制考虑的。
4.4.2 过滤
ElasticSearch允许我们在整个集群或是索引的级别来配置分片的分配。其中在集群的 级别上我们可以使用带有下面前缀的属性:
cluster.routing.allocation.include
cluster.routing.allocation.require
cluster.routing.allocation.exclude而处理索引级分配时,将上述cluster字段换成index即可。
上述前缀可以与我们在elasticsearch.yml文件里定义的属性一起使用(tag属性和group属性)。只需使用一个名为_ip的特殊属性,就可以使用IP地址来进行包含或排除特定的节点。例如:
cluster.routing.allocation.include._ip:192.168.2.1如果希望包含一组group属性是groupA的节点,应该设置下面的属性:
cluster.routing.allocation.include.group:groupA这些属性意味着什么
- include:这种类型会包含所有定义了某参数的节点。 拥有include参数类型的节点,ElasticSearch在选 择放置分片的节点时会加以考虑,但这并不意味着ElasticSearch一定会把分片放到这些节点上。
- require:它要求所有 节点都必须拥有和这个属性值相匹配的值。
- exclude :这个属性允许我们在分片分配过程中排除具有特定属性的节点。
属性值可以使用简单的通配符。
4.4.3 运行时更新分配策略
除了在elasticsearch.yml文件里设置我们讨论过的那些属性外,在集群已经启动运行 后,也可以通过更新API来实时更新这些设置。
索引级更新
为了更新一个给定索引(如mastering索引)的设置,我们执行下面的命令:
curl -XPUT 'localhost:9200/mastering/_settings' -d '{
"index.routing.allocation.require.group":"groupA"
}'集群级更新
临时更新
为了更新整个集群的设置,我们执行下面的命令,(重启集群后失效):
curl -XPUT 'localhost:9200/_cluster/settings' -d '{
"transient":{
"cluster.routing.allocation.require.group":"groupA"
}
}'永久更新
用persistent属性替换上述transient属性 即可。
4.4.4 确定每个节点允许的总分片数
除了前面提到的属性,我们还能定义每个节点可分配给索引的分片总数(主分片和副 本)。为了实现该目的,我们需要给index.routing.allocation.total_shards_per_node属性设置一个期望值。例如在elasticsearch.yml文件里做如下设置:
index.routing.allocation.total_shards_per_node:4这样,单个节点上最多会为同一个索引分配4个分片。
这个属性同样可以在一个运行中的集群上使用更新API来改变,例如:
curl -XPUT 'localhost:9200/mastering/_settings -d '{
"index.routing.allocation.total_shards_per_node":"4"
}'4.4.5 更多的分片分配属性
- cluster.routing.allocation.allow_rebalance:这个属性允许我们基于集群中所有分片的 状态来控制执行再平衡(rebanlance)的时机。可选的值包括:always、indices_primaries_active 、indices_all_active (默认)。
- cluster.routing.allocation.cluster concurrent_rebanlance:这个属性控制我们的集群内有多少分片可以并发参与再平衡处理,默认值为2。
- cluster.routing.allocation.node_initial_primaries_recoveries:这个属性指定了每个节 点可以并发恢复的主分片数量。基于主分片恢复通常比较快,即使把属性值设置得较大,也不会给节点本身带来过多的压力。这个属性的默认值为4.
- cluster.routing.allocation.node_concurrent_recoveries:这个属性指定了每个节点允 许的最大并发恢复分片数,默认值是2。
- cluster.routing.allocation.disable_new_allocaiton:默认值是false。该属性用来控制是否禁止为新创建的索引分配新分片(包括主分片和副本分片)。
- cluster.routing.allocation.disable_allocation:默认值是false。该属性用来控制是否禁 止针对已创建的主分片和副本分片的分配。请注意,将一个副本分片提升为主分片(如果主分片不存在)的行为不算分配。
- cluster.routing.allocation.disable_replica_allocation:这个属性默认是false。当它设 为true时,将会禁止将副本分片分配到节点。
前面所有的属性既可以在elasticsearch.yml文件里设置,也可以通过更新API来设置。然而在实践中,通常只使用更新API来配置一些属性,如cluster.routing.allocation.disable_new_allocation、cluster.routing.allocation.disable_allocation、cluster.routing.allocation. disable_replica_allocation.
4.5 查询执行偏好
除了ElasticSearch允许我们设置分片和副本 的那些技巧以外,我们还能够指定查询(以及其他操作,如实时获取)在哪里执行。
介绍preference参数
为了控制我们所发送查询(和其他操作)执行的地点,可以使用preference参数,它可 以取下面这些值:
- _primary:使用这个属性,发送的操作仅会在主分片上执行。
- _primary_first:这个属性的行为很像primary,但它有一个自动故障恢复机制。 该选项与primary非常相似,只是当主分片由于某些原因不可用时可以转而使用其 副本。
- _local:ElasticSearch在可能的情况下会优先在本地节点上执行操作。 这在最小化网络延时时尤为有用,当使用local时,确保尽可能(如从本地节点发起的客户端连接或向某节点发送查询)地在本地执行查询。
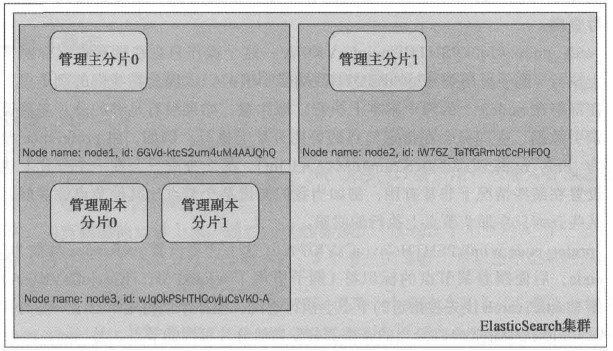
- _only_node:wJqOkPSHTHCovjuCsVKO-A:这个操作只会在拥有指定标识符的节点上执行(例子里用了wJqOkPSHTHCovjuCsVKO-A )。因此在我们的例子里,查询会在部署在node3上的两个副本上执行。请注意,如果没有足够的分片来覆盖所有的索引数据,查询只会在指定节点的可用分片上执行。例如当我们知道某个节点比其他节点性能好,且希望 某些查询只在那个节点上执行的时候。
- _prefer_node:wJqOkPSHTHCovjuCsVKO-A:与_only_node选项类 似,_prefer_node可以用来选择一个特定的节点,只是当特定节点不可用时可以转而使用其他节点。
- _shards:0,1:这个preference参数值既指定了操作将在哪个分片上执行。是唯一一个可 以和其他选项值组合的preference参数值。例如,为了在本地的0和1分片上执行查询,我们用分号连接0,1和_local,最终preference参数看起来就像是这样:0,1;_local。对调试来说,允许我们在一个分片上执行查询非常有用。
- custom:这是一个自定义值,它确保了具有相同值的查询会在相同的分片上执行。 例如,发送一个preference参数值为mastering_ elasticsearch的查询,那么查询会在名称是nodel和node2的节点的主分片上执行。如果我们发送另一个具有相同preference参数值的查询,那么该查询将在相同的分片上执行。这个功能在需要有不同的刷新频率,并且不希望用户在重复查询时看到不同结果的时候尤为有用。
- 默认行为。ElasticSearch默认会在分片和副本之间随机执 行操作。如果我们发送大量的请求,那么最终每个分片和副本上将会执行相同(或者几乎相同)数量的查询。
4.6 应用我们的知识
性能测试开源工具
- ApacheJMeter
- ActionGenerator
- ElasticSearch paramedic的插件
- ElasticSearch BigDesk的插件
避免单个节点上运行多个ElasticSearch实例
将node.max_local_storage_nodes属性值设为1,是为了避免单个节点上运行多个ElasticSearch实例。
发现
在发现模块的配置中,我们仅仅设置了一个属性,即设置discovery.zen.minimum_master_nodes的属性值为3。它能指定组成集群所需的且可以成为主节点的最小节点数,取值至少是集群节点数的一半加1.
记录慢查询
协同ElasticSearch工作时,有件事情非常重要:记录那些执行时间大于等于某个阈值的查询。请注意,这个日志记录的不是查询的全部执行时间,而是查询在每个分片上执行的时间,这意味着日志记录的只是执行时间的一部分。
在例子里,我们想使用INFO级日志记录执行超过500毫秒的查询和执行超过1秒的实时读取操作。对于调试级日志,这里分别设置为100毫秒和200毫秒。下面是这部分内容的配置片段:
index.search.slowlog.threshold.query.info:500ms
index.search.slowlog.threshold.query.debug:100ms
index.search.slowlog.threshold.fetch.info:1s
index.search.slowlog.threshold.fetch.debug:200ms记录垃圾回收器的工作情况
最后,由于我们在没有监控的情况下就开始了,因而想看看垃圾回收器表现如何。例如,想要搞清楚是否以及何时垃圾回收器消耗了太多的时间。为了实现这个目的,我们在elasticsearch.yml文件里加人下面几行内容:
monitor.jvm.gc.ParNew.info:700ms
monitor‘jvm.gc.ParNew.debug:400ms
monitor.jvm.gc.ConcurrentMarkSweep.info:5s
monitor.jvm.gc.ConcurrentMarkSweep.debug:2s通过使用INFO级日志,当并发标记清除(concurrent mark sweep)执行等于或超过5秒时,以及新生代收集(younger generation collection)执行超过700毫秒时,ElasticSearch会记录垃圾回收器工作超时的信息。同时也加上了DEBUG级日志,用来应对我们想要调试或者修复问题的情况。
内存设置
通常的建议是不要使Java虚拟机堆的大小超过可用内存总量的50%。
在前面所展示的配置中,我们设置了ElasticSearch记录垃圾回收器的信息,然而为了长期监控,你可能还需要使用类似SPM ( http://sematext.com/spm/index.html)或Munin(http://munin-monitoring.org/)的监控工具。
参考资料
BigDesk
ApacheJMeter
SPM
Munin

