第01章 ElasticSearch简介
本章内容
Apache Lucene是什么。
Lucene的整体架构。
文本分析过程是如何实现的。
Apache Lucene的查询语言及其使用方法。
ElasticSearch的基本概念。
ELasticSearch内部是如何通信的。
1.1 Apache Lucene简介
1.1.2 Lucene的总体架构
Lucene一些概念:
- 文档(document):索引与搜索的主要数据载体,它包含一个或多个字段,存放将要写入索引或将从索引搜索出来的数据。
- 字段(field ):文档的一个片段,它包括两个部分:字段的名称和内容。
- 词项(term ):搜索时的一个单位,代表文本中的某个词。
- 词条(token ):词项在字段中的一次出现,包括词项的文本、开始和结束的位移以及类型。
索引示意图
Segment
每个索引由多个段(segment )组成,每个段只会被创建一次但会被查询多次。索引期间,段经创建就不会再被修改。例如,文档被删除以后,删除信息被单独保存在一个文件中,而段本身并没有修改。
为什么要合并段
多个段会在一个叫作段合并(segments merge)的阶段被合并在一起,而且要么强制执行,要么由Lucene的内在机制决定在某个时刻执行,合并后段的数量更少,但是更大。段合并非常耗I/O,且合并期间有些不再使用的信息也将被清理掉,例如,被删除的文档。对于容纳相同数据的索引,段的数量较少时,搜索速度更快。
1.1.3 分析你的数据
文本分析由分析器来执行,而分析器由分词器(tokenizer)、过滤器(filter)和字符映射器组成(character mapper)。
一些过滤器的例子:
- 小写过滤器:将所有词条转化为小写。
- ASCII过滤器:移除词条中所有非ASCII字符。
- 同义词过滤器:根据同义词规则,将一个词条转化为另一个词条。
- 多语言词干还原过滤器:将词条的文本部分归约到它们的词根形式,即词干还原。
1.2 ElasticSearch简介
1.2.1 ElasticSearch基本概念
-
分片
除了ElasticSearch本身自动进行分片处理外,用户为具体的应用进行参数调优也是至关重要的,因为分片的数量在索引创建时就已经配置好,而且之后无法改变,至少对目前的版本是这样的。 -
副本
支持在任意时间点添加或移除副本,所以一旦有需要可随时调整副本的数量。 -
网关
在ElasticSearch的工作过程中,关于集群状态,索引设置的各种信息都会被收集起来,并在网关(gateway)中被持久化。
1.2.2 ElasticSearch架构背后的关键概念
ElasticSearch主要特征:
- 合理的默认配置。使得用户在简单安装以后能直接使用ElasticSearch而不需要任何额外的调试,这包括内置的发现(如字段类型检测)和自动配置功能。
- 默认的分布式工作模式。每个节点总是假定自己是某个集群的一部分或将是某个集群的一部分,一旦工作启动节点便会加人某个集群。
- 对等架构(P2P)可以避免单点故障( SPOF )。节点会自动连接到集群中的其他节点,进行相互的数据交换和监控操作。这其中就包括索引分片的自动复制。
- 易于向集群扩充新节点,不论是从数据容量的角度还是数量角度。
- ElasticSearch没有对索引中的数据结构强加任何限制,从而允许用户调整现有的数据模型。
- 准实时(Near Real Time , NRT)搜索和版本同步(versioning )。考虑到ElasticSearch的分布式特性,查询延迟和节点之间临时的数据不同步是难以避免的。ElasticSearch尝试消除这些问题并且提供额外的机制用于版本同步。
1.2.3 ElasticSearch的工作流程
启动过程
当ElasticSearch节点启动时,它使用广播技术(也可配置为单播)来发现同一个集群中的其他节点(这里的关键是配置文件中的集群名称)并与它们连接。
集群中会有一个节点被选为管理节点(master node)。该节点负责集群的状态管理以及在集群拓扑变化时做出反应,分发索引分片至集群的相应节点上。
Note
请记住,从用户的角度来看,ElasticSearch中的管理节点并不比其他节点重要,这与其他某些分布式系统不同(如数据库)。实际上,你不需要知道哪个节点是管理节点,所有操作可以发送至任意节点,ElasticSearch内部会自行处理这些不可思议的事情。如果有需要,任意节点可以并行发送子查询给其他节点,并合并搜索结果,然后返回给用户。所有这些操作并不需要经过管理节点处理(请记住,ElasticSearch是基于对等架构的)。
管理节点读取集群的状态信息,并在必要时进行恢复处理。在该阶段,管理节点会检查所有索引分片并决定哪些分片将用于主分片。然后,整个集群进人黄色状态。这意味着集群可以执行查询,但是系统的吞吐量以及各种可能的状况是未知的,因而接下来就是要寻找到冗余的分片并用作副本。
故障检测
管理节点会发送ping请求至其他节点,然后等待响应。如果没有响应,则该节点会从集群中移除。
与ElasticSearch通信
索引数据
ElasticSearch提供了四种方式来创建索引。
-XPUT
最简单的方式是使用索引API,它允许用户发送一个文档至特定的索引。例如,使用curl工具,并用如下命令创建一个文档:
![]()
- bulk API(UDP bulk API)
第二种或第三种方式允许用户通过bulk API或UDP bulk API来一次性发送多个文档至集群。两者的区别在于网络连接方式,前者使用HTTP协议,后者使用UDP协议,且后者速度快,但是不可靠。 - river
第四种方式使用插件发送数据,称为河流(river ),河流运行在ElasticSearch节点上,能够从外部系统获取数据。

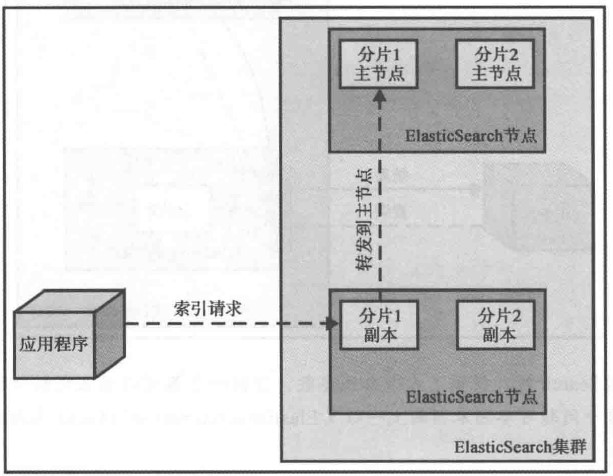
有一件事情需要记住,建索引操作只会发生在主分片上,而不是副本上。当把一个索引请求发送至某节点时,如果该节点没有对应的主分片或者只有副本,那么这个请求会被转发到拥有正确的主分片的节点(如下图所示)。
查询数据
查询API占据了ElasticSearch API的大部分内容。使用查询DSL(基于JSON的可用于构建复杂查询的语言),我们可以做下面这些事情:
- 使用各种查询类型,包括:简单的词项查询、短语查询、范围查询、布尔查询、模糊查询、区间查询、通配符查询、空间查询等。
- 组合简单查询构建复杂查询。
- 文档过滤,在不影响评分的前提下抛弃那些不满足特定查询条件的文档。
- 查找与特定文档相似的文档。
- 查找特定短语的查询建议和拼写检查。
- 使用切面构建动态导航和计算各种统计量。
- 使用预搜索(prospective search)并查找与指定文档匹配的query集合。
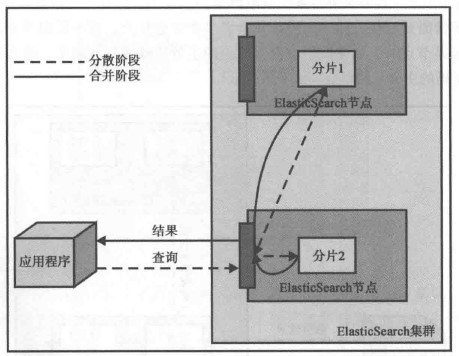
对于查询操作,读者应该要重点了解:查询并不是一个简单的、单步骤的操作。一般来说,查询分为两个阶段:分散阶段(scatter phase)和合并阶段(gather phase)。分散阶段将query分发到包含相关文档的多个分片中去执行查询,合并阶段则从众多分片中收集返回结果,然后对它们进行合并、排序、后续处理,然后返回给客户端。该机制可以由下图描述。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号