TinkerPop中的遍历:图的遍历步骤(2/3)
24 Group Step
有时,所运行的实际路径或当前运行位置不是计算的最终输出,而是遍历的一些其他表示。group()步骤(map / sideEffect)是根据对象的某些功能组织对象的一个方法。
比如:
gremlin> g.V().group().by(label)
==>[software:[v[3],v[5]],person:[v[1],v[2],v[4],v[6]]]
gremlin> g.V().group().by(label).by('name')
==>[software:[lop,ripple],person:[marko,vadas,josh,peter]]
gremlin> g.V().group().by(label).by(count())
==>[software:2,person:4]
25 GroupCount Step
groupCount()分组统计,是(map/sideEffect)类型的步骤。
gremlin> g.V().hasLabel('person').values('age').groupCount() //
==>[32:1,35:1,27:1,29:1]
gremlin> g.V().hasLabel('person').groupCount().by('age') //
==>[32:1,35:1,27:1,29:1]
注意不能使用以下方式:
~~gremlin> g.V().hasLabel('person').by('age').groupCount()~~
26 Has Step
可以使用has()步骤(filter)根据其属性来过滤顶点,边和顶点属性。 它有很多变体,包括:
has(key,value)
has(label, key, value)
has(key,predicate)
hasLabel(labels…)
hasId(ids…)
hasKey(keys…)
hasValue(values…)
has(key)
hasNot(key)
has(key, traversal)
27 Id Step
id()步骤(map)取一个Element并从中提取它的标识符。
gremlin> g.V().id() //所有顶底的ID
gremlin> g.V(1).outE().id() // 节点1发出的所有边的ID
gremlin> g.V(1).properties().id() //节点1的所有属性的ID
28 Inject Step
inject()步骤(sideEffect)使得可以将对象任意插入到遍历流中。
gremlin> g.V(4).out().values('name')
==>ripple
==>lop
gremlin> g.V(4).out().values('name').inject('daniel')
==>daniel
==>ripple
==>lop
gremlin> g.V(4).out().values('name')
==>ripple
==>lop
29 Is Step
可以使用is()步骤(filter)来过滤标量值。
gremlin> g.V().values('age').is(32)
==>32
gremlin> g.V().values('age').is(lte(30))
==>29
==>27
30 Label Step
label()步骤(map)取一个Element并从中提取它的标签。
gremlin> g.V().label() //所有顶点的标签
gremlin> g.V(1).outE().label() //节点1出发的所有边的标签
gremlin> g.V(1).properties().label() //节点1的所有属性的标签
31 Key Step
key()步骤(map)取一个Property并从中提取该键。
gremlin> g.V(1).properties().key() //节点1的所有属性的key
gremlin> g.V(1).properties().properties().key() //节点1的所有元属性的key
32 Limit Step
limit() 步骤类似于range()步骤下限范围设置为0的情况。
gremlin> g.V().limit(2)
==>v[1]
==>v[2]
gremlin> g.V().range(0, 2)
==>v[1]
==>v[2]
limit()也可以应用于 ,在这种情况下,它会对传入的集合进行操作。
gremlin> g.V().valueMap().limit(local, 1) //对集合的操作
==>[name:[marko]]
==>[name:[vadas]]
==>[name:[lop]]
==>[name:[josh]]
==>[name:[ripple]]
==>[name:[peter]]
gremlin> g.V().valueMap().limit(1) //只取一个值
==>[name:[marko],age:[29]]
Note
注意,上述 local是静态引入的Scope.local。
33 Local Step
GraphTraversal对连续的对象流进行操作。在许多情况下,重要的是在该流中的单个元素上进行操作。要做这样的对象局部遍历计算,local()步骤(branch)因此而生。
比较以下遍历:
gremlin> g.V().as('person').
properties('location').order().by('startTime',incr).limit(2).value().as('location').
select('person','location').by('name').by()
==>[person:daniel,location:spremberg]
==>[person:stephen,location:centreville]
gremlin> g.V().as('person').
local(properties('location').order().by('startTime',incr).limit(2)).value().as('location').
select('person','location').by('name').by()
==>[person:marko,location:san diego]
==>[person:marko,location:santa cruz]
==>[person:stephen,location:centreville]
==>[person:stephen,location:dulles]
==>[person:matthias,location:bremen]
==>[person:matthias,location:baltimore]
==>[person:daniel,location:spremberg]
==>[person:daniel,location:kaiserslautern]
上面的遍历,根据最具历史地理位置的开始时间,获取前两个人及其各自的位置。
下面的遍历,对于每一个人来说,都有两个历史最悠久的地方。
上述遍历使用Crew图,该图结构如下所示:
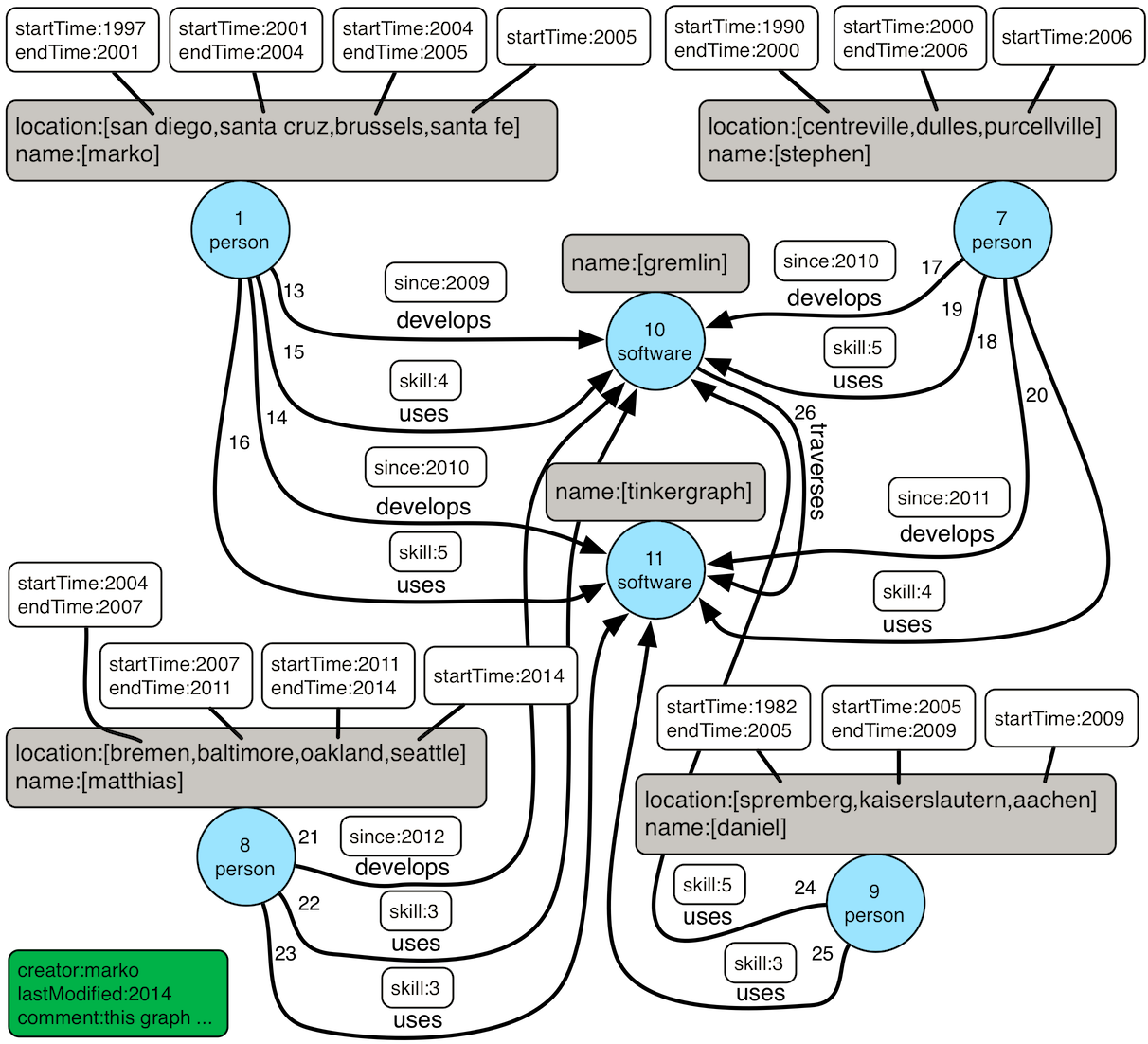
local()与flatMap()
local()步骤在功能上与flatMap()步骤非常相似,通常可能会使其混淆。local()通过内部遍历传播遍历器,而不会拆分/克隆它。因此,它在本地处理“全局遍历”。
gremlin> g.V().both().barrier().flatMap(groupCount().by("name"))
==>[lop:1]
==>[lop:1]
==>[lop:1]
==>[vadas:1]
==>[josh:1]
==>[josh:1]
==>[josh:1]
==>[marko:1]
==>[marko:1]
==>[marko:1]
==>[peter:1]
==>[ripple:1]
gremlin> g.V().both().barrier().local(groupCount().by("name"))
==>[lop:3]
==>[vadas:1]
==>[josh:3]
==>[marko:3]
==>[peter:1]
==>[ripple:1]
34 Loops Step
loops()步骤(map)提取Traverser经过当前循环的次数。
35 Match Step
match()步骤(map)基于模式匹配的概念提供了一种更具声明性的图形查询形式。
"Who created a project named 'lop' that was also created by someone who is 29 years old? Return the two creators."
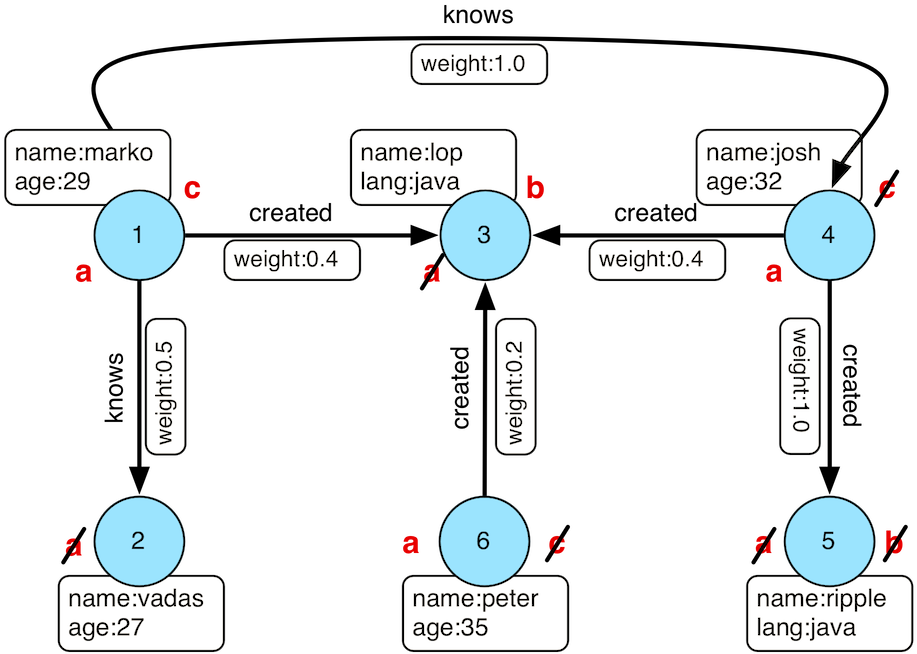
gremlin> g.V().match(
__.as('creators').out('created').has('name', 'lop').as('projects'), //1
__.as('projects').in('created').has('age', 29).as('cocreators')). //2
select('creators','cocreators').by('name') //3
==>[creators:marko,cocreators:marko]
==>[creators:josh,cocreators:marko]
==>[creators:peter,cocreators:marko]
1: 找到创建了其他节点的节点,并将这些节点标记为“creators”,然后找出由“creators”创建的名为“lop”的节点,并将这些顶点匹配为“projects”。
2: 从这些“projects”顶点找出创建它们的节点,并过滤出其中年龄为29岁的节点,并将其记作“cocreators”。
3: 返回“creators”和“cocreators”的名称。
使用where
Match通常与select()和where()(在此呈现)结合使用。 where()步骤允许用户进一步限制由match()提供的结果集。
如使用where去掉creators和cocreators相同的元素:
g.V().match(
__.as('creators').out('created').has('name', 'lop').as('projects'),
__.as('projects').in('created').has('age', 29).as('cocreators')).
where('creators',neq('cocreators')).
select('creators','cocreators').by('name')
36 Max Step
max()步骤(map)对数字流进行操作,并确定流中最大的数字。
gremlin> g.V().values('age').max()
==>35
37 Mean Step
mean() 步骤(map)对数字流进行操作,并确定这些数字的平均值。
gremlin> g.V().values('age').mean()
==>30.75
38 Min Step
min()步骤(map)对数字流进行操作,并确定流中最小的数字。
gremlin> g.V().values('age').min()
==>27
39 Not Step
取反操作,属于filter步骤。
示例:
gremlin> g.V().not(hasLabel('person')).valueMap()
==>[name:[lop],lang:[java]]
==>[name:[ripple],lang:[java]]
40 Option Step
branch() or choose()的选项。参考相应的遍历步骤。
41 Optional Step
optional()步骤(map)在遍历产生一个结果时返回相应结果,否则返回调用元素。
如下:
gremlin> g.V(1).optional(out('knows')) //1
==>v[2]
==>v[4]
gremlin> g.V(2).optional(out('knows')) //2
==>v[2]
1:当节点1具有向外的边“knows”,则返回向外的边指向的元素;
2:当节点2没有向外的边“knows”,则 返回节点2本身;
42 Or Step
or()步骤(filter)确保至少一个所提供的遍历产生结果。
比如,只要符合具有发出“created”边 或者 有进入“created”边且进入边的总数大于1 这两个条件之一的遍历结果就可以返回:
gremlin> g.V().or(
__.outE('created'), //有发出“created”边
__.inE('created').count().is(gt(1))). //有进入“created”边且进入边的总数大于1
values('name')
==>marko //符合第1个条件
==>lop //符合第2个条件
==>josh //符合第1个条件
==>peter //符合第1个条件
需要注意的是,若遍历对象流符合or()步骤中的多个条件,那么结果并不会重复。如下:
gremlin> g.V().or(
__.outE('created'),
__.hasLabel('person')).
values('name')
==>marko
==>vadas
==>josh
==>peter
都不符合提供的条件时,不返回结果。如下:
gremlin> g.V().or(
__.outE('created-err'),
__.inE('created-err').count().is(gt(1))).
values('name')
43 Order Step
当遍历流的对象需要排序时,可以利用order()步骤(map)。
gremlin> g.V().values('name') //不指定排序
==>marko
==>vadas
==>lop
==>josh
==>ripple
==>peter
gremlin> g.V().values('name').order() //默认升序
==>josh
==>lop
==>marko
==>peter
==>ripple
==>vadas
gremlin> g.V().values('name').order().by(decr) //声明为降序
==>vadas
==>ripple
==>peter
==>marko
==>lop
==>josh
gremlin> g.V().values('name').order().by(shuffle) //乱序
==>ripple
==>marko
==>peter
==>vadas
==>lop
==>josh
gremlin> g.V().values('name').order().by(shuffle) //乱序
==>josh
==>ripple
==>vadas
==>lop
==>peter
==>marko
Note
shuffle来自静态引入的Order.shuffle。
可在by()中指定排序的元素,如:
gremlin> g.V().order().by('name',decr).values('name')
==>vadas
==>ripple
==>peter
==>marko
==>lop
==>josh
44 PageRank Step
pageRank()步骤(map/sideEffect)使用PageRankVertexProgram计算PageRank。
如下,计算Modern图中的各节点的PageRank值:
gremlin> graph = TinkerFactory.createModern()
==>tinkergraph[vertices:6 edges:6]
gremlin> g = graph.traversal().withComputer()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], graphcomputer]
gremlin> g.V().pageRank().by('pageRank').valueMap('name','pageRank')
==>[name:[josh],pageRank:[0.19250000000000003]]
==>[name:[lop],pageRank:[0.4018125]]
==>[name:[vadas],pageRank:[0.19250000000000003]]
==>[name:[marko],pageRank:[0.15000000000000002]]
==>[name:[ripple],pageRank:[0.23181250000000003]]
==>[name:[peter],pageRank:[0.15000000000000002]]
Note:
pageRank()步骤是一个VertexComputing步骤,因此只能用于支持GraphComputer(OLAP)的图形。
45 Path Step
path()步骤用来(map)检查遍历器的历史路径。
如发现
gremlin> g.V().out().out().values('name')
==>ripple
==>lop
gremlin> g.V().out().out().values('name').path()
==>[v[1],v[4],v[5],ripple]
==>[v[1],v[4],v[3],lop]
如果路径中需要边缘,那么请确保明确地遍历这些边。
gremlin> g.V().outE().inV().outE().inV().path()
==>[v[1],e[8][1-knows->4],v[4],e[10][4-created->5],v[5]]
==>[v[1],e[8][1-knows->4],v[4],e[11][4-created->3],v[3]]
Note
注意out()与outV()区别。g.V().out()直接指向“箭头指向的节点”,而outV()则是“发出箭头的节点”。如:
gremlin> g.V(1).outE().outV().values('name')
==>marko
==>marko
==>marko
gremlin> g.V(1).out().out().values('name')
==>lop
==>ripple
//以下语法效果是相等的
gremlin> g.V(1).out('knows').values('name')
==>vadas
==>josh
gremlin> g.V(1).outE('knows').inV().values('name')
==>josh
==>vadas
46 PeerPressure Step
peerPressure()步骤(map/sideEffect)使用PeerPressureVertexProgram对顶点进行聚类。
gremlin> g.V().peerPressure().by('cluster').group().by('cluster').by('name')
==>[1:[marko,vadas,lop,josh,ripple],6:[peter]]
Note
peerPressure()步骤是一个VertexComputing步骤,因此只能用于支持GraphComputer(OLAP)的图。
47 Profile Step
profile()步骤(sideEffect)允许开发人员对其遍历进行剖析,以确定统计信息,如步骤运行时间,计数等。
gremlin> g.V().out().out().has('name','lop').values('name').profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
GraphStep(vertex,[]) 6 6 0.057 59.90
VertexStep(OUT,vertex) 6 4 0.019 20.88
VertexStep(OUT,vertex) 2 2 0.009 9.48
HasStep([name.eq(lop)]) 1 1 0.006 6.75
PropertiesStep([name],value) 1 1 0.002 2.99
>TOTAL - - 0.095 -
该步骤生成包含以下信息的TraversalMetrics sideEffect对象:
- 步骤(Step):遍历内的一个步骤。
- 计数(Count):通过步骤的表示的遍历器的数量。
- 遍历(Traversers):遍历步骤的遍历数。
- 时间(Time/ms):步骤主动执行其行为的总时间。
- %Dur:在步骤中花费的总时间的百分比。
当第一次遍历加入条件‘knows’,情况就不相同,注意Count与Traversers的值:
gremlin> g.V().out('knows').out().has('name','lop').values('name').profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
GraphStep(vertex,[]) 6 6 0.024 42.90
VertexStep(OUT,[knows],vertex) 2 2 0.015 27.27
VertexStep(OUT,vertex) 2 2 0.013 24.46
HasStep([name.eq(lop)]) 1 1 0.001 2.95
PropertiesStep([name],value) 1 1 0.001 2.42
>TOTAL - - 0.056 -
注意Count与Traversers的区别:
- 遍历器可以合并,因此当两个遍历器“相同”时,它们可以聚合成单个遍历器。
- 新的遍历器具有Traverser.bulk(),它是两个遍历器的总和。
- Count表示所有Traverser.bulk()结果的总和,因此展现的是“呈现(represented)”(非枚举(not enumerated))遍历器的数量。
- Traversers总是小于Count。
Note
Count与Traversers的区别需要更多的了解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号