KafKa介绍
一、什么是Kafka
Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。无论是kafka集群,还是consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
二、优点(相比较于Flume)
在企业中必须要清楚流式数据采集框架flume和kafka的定位是什么:
flume:★ 适合多个生产者;适合下游数据消费者不多的情况;适合数据安全性要求不高的操作;适合与Hadoop生态圈对接的操作。为什么只适合多个生产者,适合下游不多的消费者呢?因为,有多个消费者则就会有多个channel,而channel一般都是内存channel,这样所占资源很大。
kafka:适合数据下游消费众多的情况;适合数据安全性要求较高的操作,支持replication。为什么适合数据下游消费众多?因为有就算有多个消费者,kafka里面存的数据是一样的,不会再增加副本。
因此我们常用的一种模型是:线上数据 --> flume --> kafka --> HDFS:所以一般情况下,企业用flume收集日志数据,然后下游sink选择kafka。
三、Kafka架构
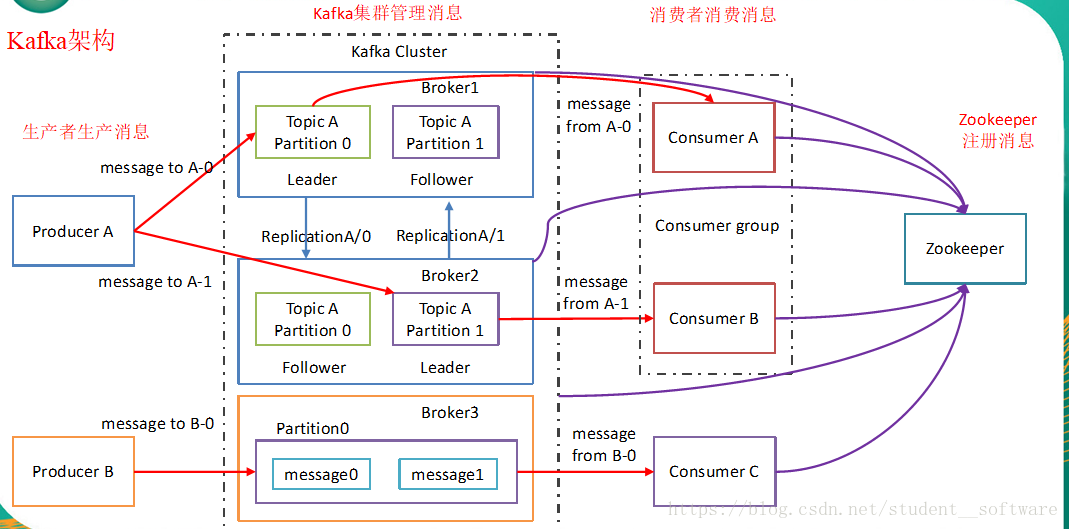
名词解释
① Producer :消息生产者,就是向kafka broker发消息的客户端;
② Consumer :消息消费者,向kafka broker取消息的客户端;
③ Topic :可以理解为一个队列;
④ Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic;
⑤ Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic;
⑥ Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序;
⑦ Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka。
内部结构注意
① 消费者和生产者能操作的最小单元是分区,也就是不可能只消费一条数据。
② 消费者组是逻辑概念,只是一个标记而已,具体的修改在config的server.properties中的设置int类型的broker_id。
③ ★同一个消费者组里面不能是同时消费者消费消息,只能有一个消费者去消费,第二,同一个消费者组里面是不会重复消费消息的,第三,同一个消费者组的一个消费者不是以一条一条数据为单元的,是以分区为单元,就相当于消费者和分区建立某种socket,进行传输数据,所以,一旦建立这个关系,这个分区的内容只能是由这个消费者消费。
④ Zookeeper保存kafka的集群状态信息的,包括每个broker,为什么?,因为zk和broker建立监听,一旦有一个broker宕机了,另一个备份就可以变为领导,第二,zk保存消费者的消费信息,为什么要保存?就是为了消费者下一次再次消费可以得知offset这个偏移量,consumer信息高版本在本地维护
⑤ ★为什么说kafka是分布式模型呢?首先,同一个kafka集群有共同拥有一个topic, 而同一个topic又拥有不同的分区,不同的分区可以分布在不同的borker上也就是不同的机子上,所以,分区是分布式的,则数据也是分布式的,kafka就是分布式。
⑥ 在不加上leader和fllower的概念的前提下,kafka的同一个topic里的分区号是不同,一定不能重复。
⑦ 除了分区是分布式的,还有消费者也是分布式的,比如,消费者组里的消费者可以在不同的机器上,有什么好处?消费的方式可以是存储可以是计算,如果是放在一台机子上,IO等压力很大,
⑧ kafka上面的所有想到的角色都是分布式的,不管是消费者还是生产者还是分区,他们之间沟通的唯一桥梁就是zookeeper 。
⑨ ★强调:kafka分区内有序,整体不一定有序。
⑩ 消费者组的概念很重要,下图解释和同一组和不同组的使用情景:
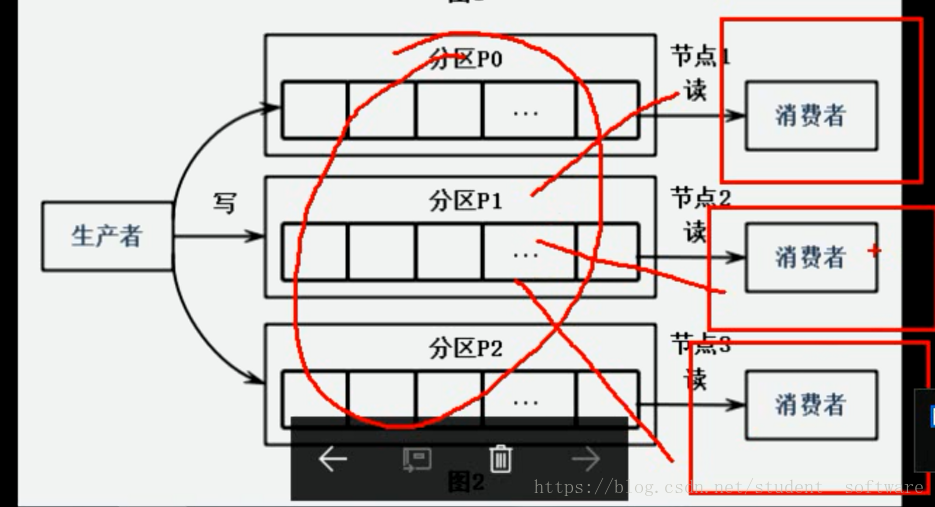
怎么实现消费者消费不同的数据? 将消费者放在同一组,但是生产环境一般要求消费者消费的数据一样且多个,比如一个写到hdfs,一个放到spark计算,这样就得要求不同的消费者在不同的消费者组里。
简单的说就是队列里面的数据,如果想让不同的消费者读不同的数据,就把他们放在同一个组里,否则放在不同组。
转自:https://blog.csdn.net/student__software/article/details/81486431

