Zookeeper简介
百度百科的介绍:ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
我们还是通俗地来认识Zookeeper吧。
先看看我们的12306,前两年,我们会发现,平时使用时基本上没什么问题,但是一到春运,12306就会很卡,网站甚至崩溃,因为流量太大,一台服务器扛不住这么大的压力,毕竟一台服务器的资源是有限的。怎么解决这个问题呢,后人想了很多办法,分布式是其中最有效的一个,既然一台服务器不够,那就两台,三台,甚至更多,这样多个服务器就形成了一个集群,虽然解决了网站的流量压力,但是是却增加了维护的难度,比如这个集群有100台服务器,如果我们要修改其中一个配置,难道我们就要去每台服务器上去改么?当然要另辟新径。Zookeeper是一个分布式的协调服务,它可以很好的解决这样的问题。
一、Zookeeper集群
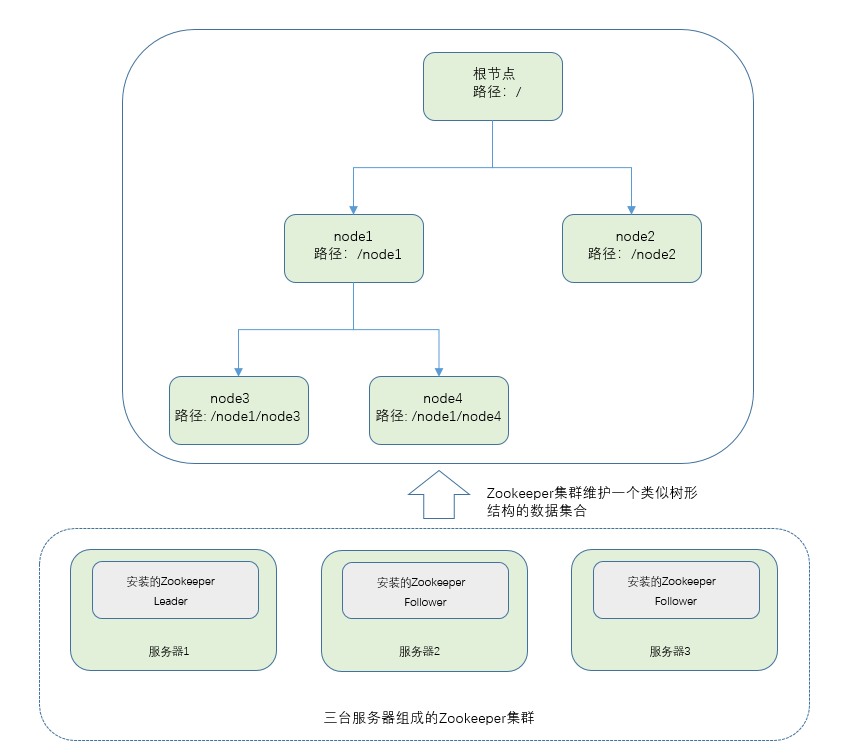
既然是分布式,必然我们需要多台服务器(当然也可以一台服务器开不同的端口,或者使用虚拟技术,或者使用docker之类的容器),最好是同一网段下,方便服务器之间要可以相互访问。然后在每个服务器上安装Zookeeper,并进行相关配置,这样,这些就形成了一个Zookeeper集群,集群节点之间可以相互连接访问。Zookeeper集群可以进行分布式数据同步,你通过集群的某个节点写入数据,Zookeeper会自动将数据同步到其他节点。
Leader和Follower
假如我们有一个Zookeeper集群,集群中有三台服务器,如果这三台是一样的拥有读写权限,那么会导致读写并发的问题(因为Zookeeper节点数据会同步,假如A、B两节点同时写入,那么C节点是同步取A的数据还是B的数据),因此Zookeeper规定,集群中只能有一个节点拥有写权限,这个节点就是Leader节点,其他的全部都是Follower节点,Follower节点只拥有读权限,而Leader节点拥有读写权限,因此如果应用通过Follower节点写入数据,Follower节点会先将数据转发到Leader节点,再由Leader节点写入。如果集群中没有Leader节点或者Leader节点故障了,那么集群内部会自动通过选举确定新Leader节点(选举算法主要有三个:leaderElection、AuthFastLeaderElection、FastLeaderElection,其中FastLeaderElection 是zookeeper 默认的一种算法)。

Zookeeper节点状态一般认为有4个:
- LOOKING:表示正在进行选举的节点,处于该状态需要进入选举流程
- LEADING:领导者状态,处于该状态的节点说明是角色已经是Leader
- FOLLOWING:跟随者状态,表示Leader已经选举出来,当前节点角色是follower
- OBSERVER:观察者状态,表明当前节点角色是observer,observer表示不会进入选举,仅仅只是接受选举结果,也就是说不会成为Leader节点,但是是follower节点一样提供服务。
Zookeeper集群中可以是一个节点或者两个节点,但是一般认为,Zookeeper集群中至少需要3个节点,这是因为Zookeeper规定,当集群中达到一半的节点故障时,就表示集群出现故障,将不再对外服务,当正常服务节点超过一半时又会自动恢复服务状态。
- 一台服务器体现不出Zookeeper的优势,如果故障了,就表示集群故障了
- 二台服务器时,如果一台发生故障,则故障节点数达到了集群节点数据的一半,也就表示集群故障了
- 三台服务器时,当两个节点故障时才表示集群故障
- 四台服务器时,当两个节点故障时才表示集群故障
于是乎,一个节点和两个节点的集群是不允许有故障节点的,而三个和四个节点的集群最多都是只能运行一个节点故障。
一般认为,Zookeeper集群中的节点是奇数,因为2n-1个节点的集群和2n个节点的集群运行的故障节点数都是n,这样2n个节点的集群就可以节省一个节点的开销了。
Znode
Zookeeper维护一个树形结构的数据集合,这个与我们的文件系统路径相似,这个树形结构中的每个节点称为znode节点,从根节点(/)开始,默认情况下,znode节点可以拥有子节点,而且每个znode节点可以保存数据,因此我们开发者可以认为,对Zookeeper的操作其实就是对znode的读写操作。
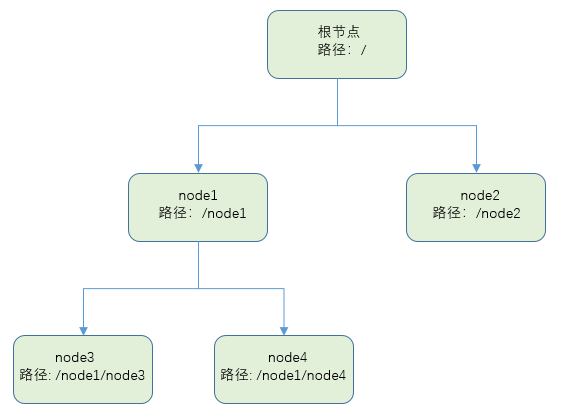
znode节点可以分为三种:
- PERSISTENT:持久节点,即使在创建该特定znode的客户端断开连接后,持久节点仍然存在。默认情况下,除非另有说明,否则所有znode都是持久的。
- SEQUENTIAL:临时节点,客户端是连接状态时,临时节点就是有效的。当客户端与ZooKeeper集合断开连接时,临时节点会自动删除。临时节点不允许有子节点。临时节点在leader选举中起着重要作用。
- EPHEMERAL:顺序节点,可以是持久的或临时的。当一个新的znode被创建为一个顺序节点时,ZooKeeper通过将10位的序列号附加到原始名称来设置znode的路径,顺序节点在锁定和同步中起重要作用。
或者说znode节点有四种:
- PERSISTENT:持久节点
- PERSISTENT_EPHEMERAL:持久顺序节点
- SEQUENTIAL:临时节点
- SEQUENTIAL_EPHEMERAL:临时顺序节点
每个znode都维护着一个 stat 结构。一个stat仅提供一个znode的元数据。它由版本号,操作控制列表(ACL),时间戳和数据长度组成,也就是记录znode节点的状态等等信息。
1)版本号:每个znode都有版本号,这意味着每当与znode相关联的数据发生变化时,其对应的版本号也会增加。当多个zookeeper客户端尝试在同一znode上执行操作时,版本号的使用就很重要。
2)操作控制列表(ACL):ACL基本上是访问znode的认证机制。它管理所有znode读取和写入操作。
3)时间戳:时间戳表示创建和修改znode所经过的时间。它通常以毫秒为单位。
4)数据长度:存储在znode中的数据总量是数据长度。你最多可以存储1MB的数据。
Watcher
Zookeeper允许客户当往znode中注册watcher,当对znode进行修改删除,或者对znode的子节点进行修改删除时,会通过注册的watcher通知客户端。
watcher只会触发一次,如果需要再次触发,则需要再次注册watcher。
另外,当客户端连接断开时,watcher将自动被删除。
二、总结
① 结构
② 操作


