集群模式详解
我这里搭建演示的版本是redis-5.0.5,这个版本对于集群搭建会有很大的简化,比如最常用的redis-trib.rb脚本功能已经集成到redis-cli工具中了,具体下面会详细介绍。
一、为什么需要集群
①、并发量
通常来说,单台Redis能够执行10万/秒的命令,这个并发基本上能够满足我们所有需求了,但有时候比如做离线计算,为了更快的得出结果,有时候我们希望超过这个并发,那这个时候单机就不满足我们需求了,就需要集群了.
②、数据量
通常来说,单台服务器的内存大概在16G-256G之间,前面我们说Redis数据量都是存在内存中的,那如果实际业务要保存在Redis的数据量超过了单台机器的内存,这个时候最简单的方法是增加服务器内存,但是单台服务器内存不可能无限制的增加,纵向扩展不了了,便想到如何进行横向扩展.这时候我们就会想将这些业务数据分散存储在多台Redis服务器中,但是要保证多台Redis服务器能够无障碍的进行内存数据沟通,这也就是Redis集群.
二、数据分区方式
对于集群来说,如何将原来单台机器上的数据拆分,然后尽量均匀的分布到多台机器上,这是我们创建集群首先要考虑的一个问题,通常来说,有如下两种数据分区方式。
顺序分布
比如我们有100W条数据,有3台服务器,我们可以将100W/3的结果分别存储到三台服务器上,如下所示:
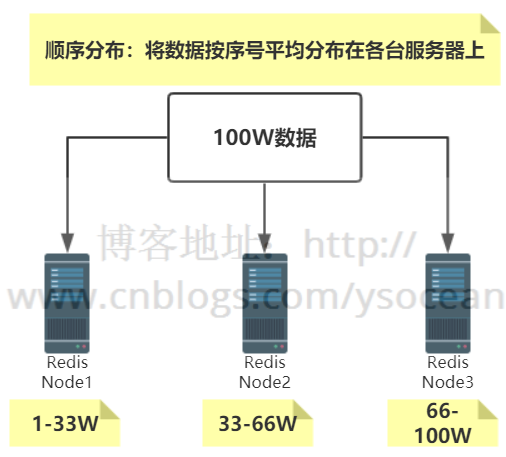
特点:键值业务相关;数据分散,但是容易造成访问倾斜;支持顺序访问;支持批量操作。
哈希分布
同样是100W条数据,有3台服务器,通过自定义一个哈希函数,比如节点取余的方法,余数为0的存在第一台服务器,余数为1的存在第二台服务器,余数为2的存储在第三台服务器.如下所示:
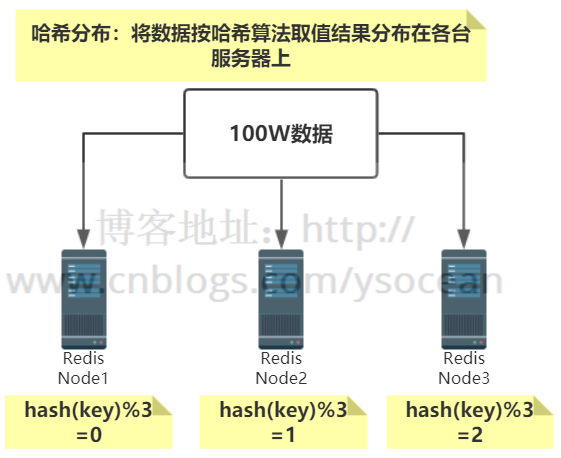
特点:数据分散度高;键值分布与业务无关;不支持顺序访问;支持批量操作。
三、一致性哈希分布
问题:对于上面介绍的哈希分布,大家可以想一下,如果向集群中增加节点,或者集群中有节点宕机,这个时候应该怎么处理?
① 增加节点
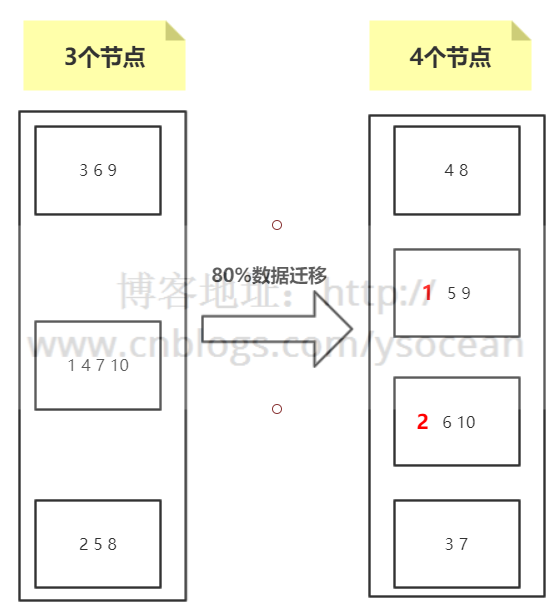
如上图所示,总共10个数据通过节点取余hash(key)%/3 的方式分布到3个节点,这时候由于访问量变大,要进行扩容,由 3 个节点变为 4 个节点。
我们发现,如图所示,数据除了标红的1 2 没有进行迁移,别的数据都要进行变动,达到了80%,如果这时候并发很高,80%的数据都要从下层节点(比如数据库)获取,会给下层节点造成很大的访问压力,这是不能接受的。
即使我们进行翻倍扩容,从3个节点增加到6个节点,其数据迁移也在50%左右。
② 删除节点
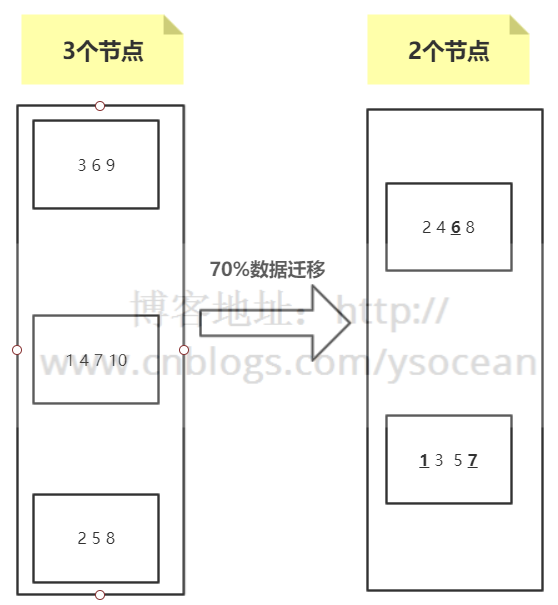
上图其实不管是哪一个节点宕机,其数据迁移量都会超过50%。基本上也是我们所不能接受的。
那么如何使得集群中新增节点或者删除节点时,数据迁移量最少?——一致性哈希算法诞生。

假设有一个哈希环,从0到2的32次方,均匀的分成三份,中间存放三个节点,沿着顺时针旋转,从Node1到Node2之间的数据,存放在Node2节点上;从Node2到Node3之间的数据,存放在Node3节点上,依次类推。
假设Node1节点宕机,那么原来Node3到Node1之间的数据这时候改为存放到Node2节点上,Node2到Node3之间数据保持不变,原来Node1到Node2之间的数据还是存放在Node2上,也就是只影响三分之一的数据,节点越多,影响数据越少。
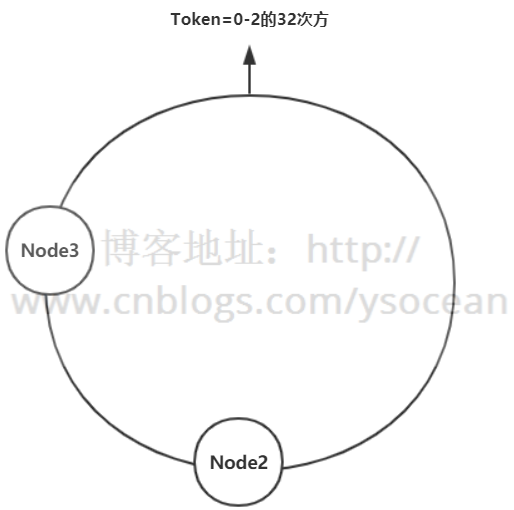
同理,假设增加一个节点,影响的数据甚至更少。

当然,实际业务中并不是你节点均匀分布,访问就会很平均,这时候容易造成访问倾斜的问题,这里就会引出虚拟节点的定义。
四、Redis Cluster虚拟槽分区
Redis集群数据分布没有使用一致性哈希分布,而是使用虚拟槽分区概念。
Redis内部内置了序号 0-16383 个槽位,每个槽位可以用来存储一个数据集合,将这些槽位按顺序分配到集群中的各个节点。每次新的数据到来,会通过哈希函数 CRC16(key) 算出将要存储的槽位下标,然后通过该下标找到前面分配的Redis节点,最后将数据存储到该节点中。
具体情况如下图:(以集群有3个节点为例)

至于为什么Redis不使用一致性哈希分布,而是虚拟槽分区。因为虚拟槽分区虽然没有一致性哈希那么灵活,但是CRC16(key)%16384 已经分布很均匀了,并且对于后面节点增删操作起来也很方便。
转自:https://www.cnblogs.com/ysocean/archive/2004/01/13/12328088.html

