集合容器
容器就是可以装载其他java对象的对象。从jdk1.2开始,Java提供了很多通用的容器。
思考下为什么需要容器呢?
因为很多程序都是在运行时才知道需要创建什么对象、创建多少对象,我们需要在任意时刻任意位置创建任意数量的对象。正是因为它的不确定性,我们必须要动态的创建对象,保存对象(其实是对象的引用)。
Java提供了一套集合类容器,基本类型包括List、Set、Queue和Map。与编译器支持的数组不同,java容器可以动态调节自己的大小,因此编程中可以将任意数量的对象放置到容器中。借助java泛型这个“语法糖”,java容器能够容纳任何类型的对象,总结下容器主要优点有:
- 降低学习难度,降低编程难度
- 提高API间的互操作性
- 降低设计和实现相关API的难度
- 提高程序性能,增加程序重用性
集合类图如下:

图里没包括进去的主要有:
- Queue接口及其实现,包括优先权队列PriorityQueue和各种BlockingQueue
- ConcurrentMap接口及其实现ConcurrentHashMap
- CopyOnWriteArrayList和CopyOnWriteArraySet
- 为使用enum而提供的Set和Map的特殊实现,EnumSet和EnumMap
标红的部分就是接下来重点介绍的实现。
一、迭代器
说具体容器之前,有必要先了解一下迭代器。作为一种设计模式,迭代器给我们提供了遍历容器中元素的方法, Iterator是作为一个接口存在的,它定义了迭代器所具有的功能,接口如下:
package java.util; public interface Iterator<E> { boolean hasNext(); E next(); void remove(); }
迭代器只能通过容器本身得到,每个容器都通过内部类实现了自己的迭代器 。
ArrayList<String> list = new ArrayList<String>(); //省略初始化list…… …… //从list得到其迭代器 Iterator<String> iterator = list.iterator(); while(iterator.hasNext()) { // String element = iterator.next(); System.out.println(element); }
如果只是向前遍历List,并不打算修改List对象本身,使用foreach语法会更加简洁。
for(String e : list){ System.out.println(e); }
二、ArrayList 和 LinkedList
List实现了将元素维护在特定的序列中,有两种类型的List:ArrayList和LinkedList,总体来说,ArrayList的随机访问效率较好,但是插入、删除元素较慢;LinkedList提供了优化的顺序访问,随机访问逊色于ArrayList,但插入、删除的代价较低。
1. ArrayList详解
ArrayList是顺序容器,底层通过数组实现,允许放入null值。每个ArrayList都有一个容量capacity,表示底层实现数组的大小,当添加元素的时候,如果capacity不够,会自动增加数组的大小。
对于ArrayList而言,size(),isEmpty(),get(),set()方法的时间复杂度是常数时间,add()方法开销和插入的位置有关,addAll()方法开销和添加的元素数量成正比,其余方法都是线性时间完成。
(1) get()
public E get(int index) { rangeCheck(index); return (E) elementData[index]; }
该方法根据下标直接从底层数组取出对应的值,rangeCheck方法用来下标越界检查,由于底层数组是Object [],因此返回时要进行类型转换。
(2) set()
public E set(int index, E element) { rangeCheck(index); E oldValue = elementData[index]; elementData[index] = element; return oldValue; }
set方法先从底层数组取出之前的值,然后将新值的引用设置到指定位置,返回结果是set之前的值。
(3) add()
ArrayList末尾添加元素的方法是add(E e),指定位置插入元素的方法是add(int index, E e),在添加的过程中,可能会存在capacity容量不足的问题,在每次添加前都要进行容量检查,如果容量不足,需要使用grow()扩容方法进行自动扩容。
private void grow(int minCapacity) { int oldCapacity = elementData.length; //原来的1.5倍 int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); //扩展空间完成后复制 elementData = Arrays.copyOf(elementData, newCapacity); }
在空间容量足够,或者扩容之后,添加元素的过程很好理解:
add(E e)方法直接在底层数组末尾中添加元素e即可,数组size+1;
add(int index, E e)需要先对插入位置之后的元素进行移动,然后完成插入操作,数组size+1,方法有线性时间复杂度。
(4) addAll()
ArrayList允许一次插入多个元素,在末尾添加的方法是addAll(Collection< ? extends E> c)方法,从指定位置开始添加元素的方法为addAll(int index, Collection< ? extends E> c)方法。其实现思路和add方法类似。时间复杂度和插入位置以及插入的元素数量有关。
(5) remove()
ArrayList的remove也有两个实现方法,remove(int index),该方法删除指定位置的元素,remove(Object o)删除第一个满足o.equals(elementData[index])的元素。
public E remove(int index) { //下标越界检查 rangeCheck(index); modCount++; E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) //生成新的数组 System.arraycopy(elementData, index+1, elementData, index, numMoved); //清除引用,让GC起作用 elementData[--size] = null; //返回删除之前的值 return oldValue; }
2. LinkedList详解
LinkedList实现了List接口,因此它也是一个顺序容器,但是同时也可以将其用作栈、队列或双端队列(实现了Deque接口)。LinkedList底层通过双向链表实现。如图所示:
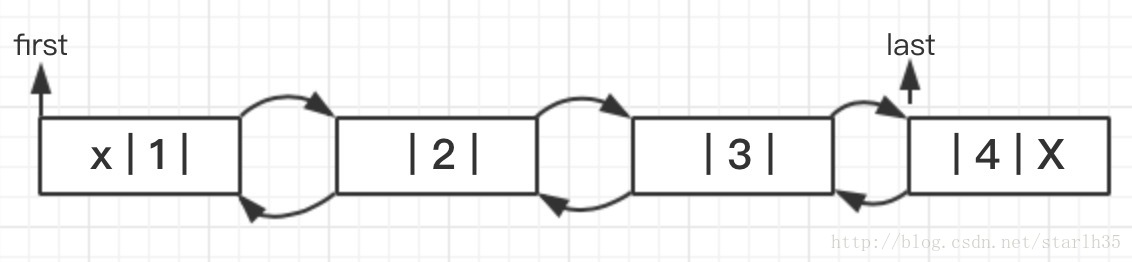
双向链表的实现依赖于内部类Node这个数据结构,源码如下:
private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }
LinkedList的first和last引用分别指向链表的第一个和最后一个元素,链表为空时,first和last指向null。
LinkedList中和下标相关的操作都是线性时间,在头部和尾部删除元素只需要常数时间。
(1) get()
get(int index)返回值的下标处的元素。
public E get(int index) { //下标越界检查 checkElementIndex(index); //返回下标处的值(Node中的item) return node(index).item; }
其中node(int index)函数根据index找到该位置的元素,查找方向取决于index靠近头部还是尾部,判断条件为 index < (size >> 1)。
(2) set()
set(int index, E element)将指定下标处的元素修改成指定值。先利用node(int index)找到下标引用,然后修改Node的item,方法返回修改前的值。
public E set(int index, E element) { checkElementIndex(index); Node<E> x = node(index); E oldVal = x.item; //直接替换新值 x.item = element; return oldVal; }
(3) add()
add()方法包含两个,add(E e)方法在链表末尾插入元素,借助last指针,末尾插入只需常数时间;add(int index, E element)方法在指定下标处插入元素,需要先查找位置再执行插入。
add(E e)方法如图:

借助图理解源码:
public boolean add(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) //若原链表为空,插入的即为第一个元素 first = newNode; else //将last指向新的Node l.next = newNode; size++; return true; }
add(int index, E element)方法如图:
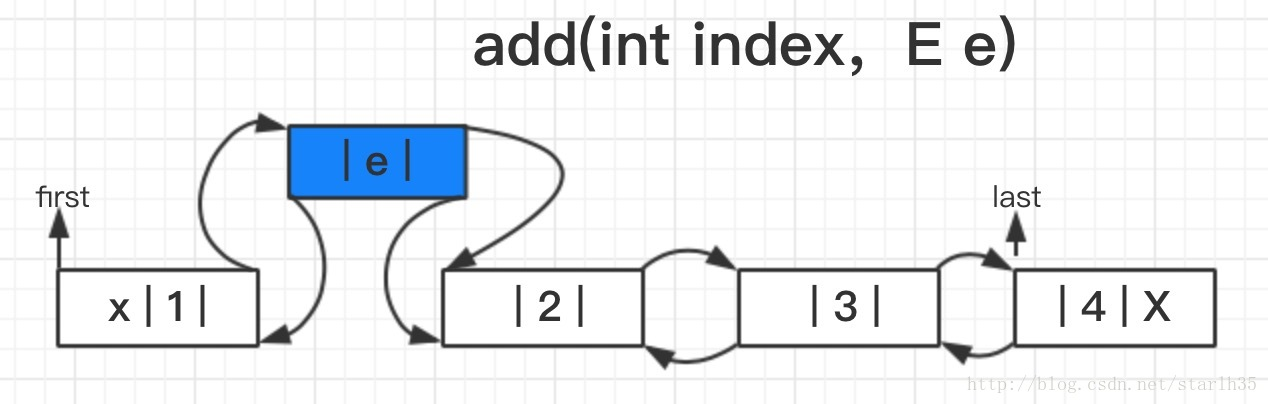
主要比add(E e)多了校验下标和使用node函数查找下标位置,其他的插入实现类似。
public void add(int index, E element) { //下标越界检查(index >= 0 && index <= size) checkPositionIndex(index); if (index == size) //插入位置是末尾,或列表为空 add(element); else{ //先根据index找到要插入的位置 Node<E> succ = node(index); final Node<E> pred = succ.prev; final Node<E> newNode = new Node<>(pred, e, succ); succ.prev = newNode; if (pred == null) first = newNode; else pred.next = newNode; size++; } }
(4) remove()
remove方法包括删除指定下标处的元素remove(int index),和删除与指定元素相等的第一个元素remove(Object o),相等根据o.equals(x.item)判断。其实现基本和add方法相逆,只需要修改链表指针指向要删除的节点的后继节点,并且将后继节点指向删除元素的前驱节点。两种方法都要查找,因此具有线性时间复杂度,remove方法通过unlink(Node< E > x)完成。
E unlink(Node<E> x) { final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev; if (prev == null) {//边界条件1:删除的是第一个元素 first = next; } else { prev.next = next; x.prev = null; } if (next == null) {//边界条件2:删除的是最后一个元素 last = prev; } else { next.prev = prev; x.next = null; } x.item = null;//let GC work size--; return element; }
三、HashMap 和 HashSet
HashMap 和 HashSet的区别并不大,HashSet的实现就是依赖于HashMap,利用适配器模式(HashSet里面包含了一个HashMap)。因此搞清楚HashMap基本也就理解了HashSet。
1. HashMap详解
HashMap实现了Map接口,该容器不保证元素顺序,会根据需要对元素进行重新hash,不同时间对同一个HashMap迭代元素顺序可能会不同。
HashMap的底层实现是数组+链表,借助hash表,处理hash冲突使用的是冲突链表方式(另一种解决冲突方法为开放地址法)。
(jdk1.8对hashmap进行了很多优化,当冲突链表长度大于8时使用红黑树解决冲突,从而在链表过长是提高查找效率)
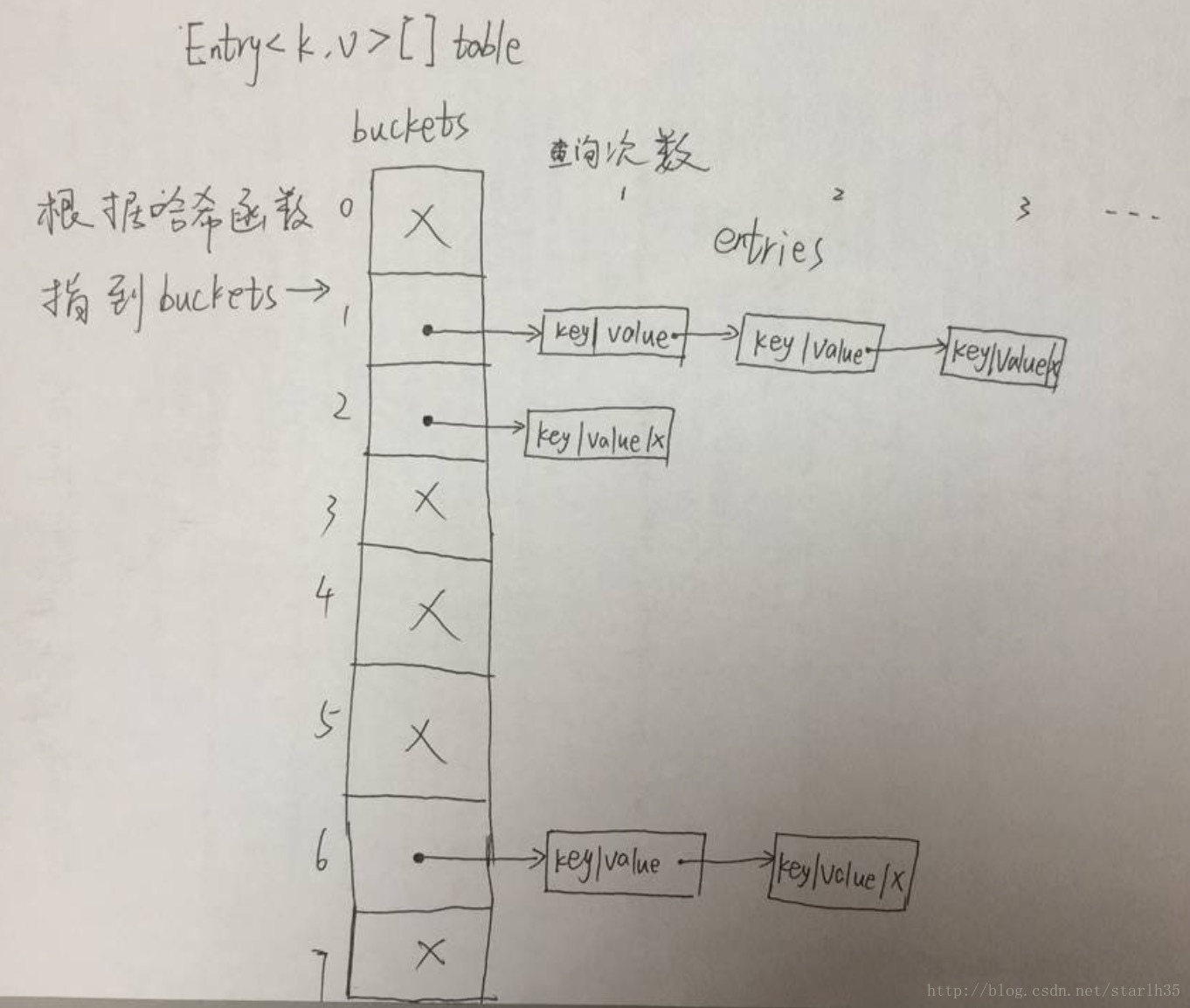
这里的两个关键方法时hashCode()和equals(), hashCode方法决定了对象会被放到哪个bucket,超过一个对象放入相同的bucket时即为冲突,equals方法用于区别冲突链表中的对象是否是同一个。我们可以根据需求自定义这两个方法实现自定义的对象hash。
PS:举个例子,我们在给物品归类的时候,一个好习惯就是把同一类物品(例如都是Cd光盘)放到一个统一的储物盒,这个储物盒就是一个bucket,同一类的判断方法在程序里就是hashCode计算哈希值。这样当我们想找CD的时候,只需要找到CD储物盒(hashCode),然后找到具体的CD(equals)。
根据上图,还可以看出是否产生冲突和选定的hash函数以及HashMap的大小有关系,在对HashMap进行迭代时,首先要对整个table进行遍历找到相应的bucket然后再对整个冲突链表遍历,因此对需要频繁迭代的场景,不宜将HashMap初始大小设置过大。
HashMap有个关键参数,初始容量(inital capacity)、负载因子(load factor),初始容量指定了table的大小,这个参数和哈希函数会影响到冲突的频繁性,负载因子用来指定自动扩容的临界值,当entry(存放键值对的对象)的数量超过capacity*load_factor时,会进行自动扩容和重新哈希。
(1) get()
get(Object key)方法根据key返回对应的value,该方法调用getEntry(Object key)得到对于的entry,然后返回entry.getValue();
上面已经分析过了,基本思想是通过hash函数找到bucket的下标,然后遍历冲突链表使用equals方法找到对应的entry。
final Entry<K,V> getEntry(Object key) { ...... int hash = (key == null) ? 0 : hash(key); for (Entry<K,V> e = table[hash&(table.length-1)];//得到冲突链表 e != null; e = e.next) {//依次遍历冲突链表中的每个entry Object k; //依据equals()方法判断是否相等 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; }
由于HashMap的table的长度是2的指数,所以table.length-1二进制低位全是1,与hash(k)相与等价于取余操作。因此代码里的hash(k)&(table.length-1)等价于hash(k)%(table.length)。
(2) put()
put(K key, V value)方法将指定的键值对添加到map中,方法首先查找原始数组是否已经包含要插入的值(查找过程类似getEntry),如果有,直接返回。如果没有找打,通过addEntry方法插入新的entry。
void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length);//容量不够时自动扩容,并重新哈希 hash = (null != key) ? hash(key) : 0; bucketIndex = hash & (table.length-1);//计算要插入的bucket } //在冲突链表头部插入新的entry(使用头插法) Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<>(hash, key, value, e); size++; }
(3) remove()
put(K key, V value)方法将指定的键值对添加到map中,方法首先查找原始数组是否已经包含要插入的值(查找过程类似getEntry),如果有,直接返回。如果没有找打,通过addEntry方法插入新的entry。remove(Object key)删除key对应的entry,首先查找该entry(查找过程类似getEntry),然后使用removeEntryForKey(Object key)删除。
final Entry<K,V> removeEntryForKey(Object key) { ...... int hash = (key == null) ? 0 : hash(key); int i = indexFor(hash, table.length);//hash&(table.length-1) Entry<K,V> prev = table[i];//得到冲突链表 Entry<K,V> e = prev; while (e != null) {//遍历冲突链表 Entry<K,V> next = e.next; Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) {//找到要删除的entry modCount++; size--; if (prev == e) table[i] = next;//删除的是冲突链表的第一个entry else prev.next = next; return e; } prev = e; e = next; } return e; }
2. HashSet详解
HashSet借助HashMap实现了无重复元素的集合,对HashSet的函数调用本质上是对HashMap调用。
public class HashSet<E> { ...... private transient HashMap<E,Object> map;//HashSet里面有一个HashMap // Dummy value to associate with an Object in the backing Map private static final Object PRESENT = new Object(); public HashSet() { map = new HashMap<>(); } ...... public boolean add(E e) { return map.put(e, PRESENT)==null; } ...... }
我们知道HashMap中的key是肯定唯一的不会重复的,因此HashSet利用了这一特点,在add的时候调用HashMap的put方法,map.put(e, PRESENT)如果有返回值说明HashMap中已经存在该元素,插入失败,如果返回null表明HashMap还没有要插入的元素,因此插入才会成功。
四、LinkedHashMap 和 LinkedHashSet
1. LinkedHashMap
类似HashMap和HashSet,LinkedHashSet的实现也是借助LinkedHashMap使用适配器模式实现的。分析了LinkedHashMap也就理解了LinkedHashSet,LinkedHashMap是HashMap的子类,二者区别在于LinkedHashMap在HashMap的基础上采用双向链表将冲突链表的entry联系起来,这样保证了元素的迭代顺序跟插入顺序相同。LinkedHashMap的图就不画了,大家脑补在HashMap结构图的基础上,冲突链表加入了双向链表的元素(before、after、next,其中next用于保证entry的链表结构,before、after用于完成双向链表的定义),同时引入了header指向双向链表的头部(哑元)。这样LinkedHashMap在遍历的时候不同于HashMap需要先遍历整个table,LinkedHashMap只需要遍历header指向的双向链表即可,因此LinkedHashMap的迭代时间只和entry数量相关。其他的包括初始容量、负载因子以及hashCode、equals方法基本和HashMap一致。
(1) get()
思路同HashMap的get方法。
(2) put()
put(K key,V value)方法插入过程类似HashMap,不同的是这里的插入有两个含义:
- 对于table而言,新的entry插入到指定的bucket时如果产生冲突,使用头插法将entry插入冲突链表头部
- 对于header而言,新的entry需要插入双向链表的尾部(保证迭代顺序)
void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length);// 自动扩容,并重新哈希 hash = (null != key) ? hash(key) : 0; bucketIndex = hash & (table.length-1);/计算要插入的bucket } // 1.在冲突链表头部插入新的entry HashMap.Entry<K,V> old = table[bucketIndex]; Entry<K,V> e = new Entry<>(hash, key, value, old); table[bucketIndex] = e; // 2.在双向链表的尾部插入新的entry e.addBefore(header); size++; }
其中addBefore将新的entry插入到header前,使新Entry成为链表的最后一个元素。
private void addBefore(Entry<K,V> existingEntry) { after = existingEntry; before = existingEntry.before; before.after = this; after.before = this; }
(3) remove()
remove(Object key)删除过程类似HashMap的remove,不同的是这里的删除也有两个含义:
- 对于table来说,删除对应bucket中的entry,然后修改冲突链表引用
- 对于header来说,将entry从双向链表删除,然后修改冲突链表该位置前后元素的引用
final Entry<K,V> removeEntryForKey(Object key) { ...... int hash = (key == null) ? 0 : hash(key); int i = indexFor(hash, table.length);// hash&(table.length-1) Entry<K,V> prev = table[i];// 得到冲突链表 Entry<K,V> e = prev; while (e != null) {// 遍历冲突链表 Entry<K,V> next = e.next; Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) {// 找到要删除的entry modCount++; size--; // 1. 将e从对应bucket的冲突链表中删除 if (prev == e) table[i] = next; else prev.next = next; // 2. 将e从双向链表中删除 e.before.after = e.after; e.after.before = e.before; return e; } prev = e; e = next; } return e; }
2. LinkedHashSet
public class LinkedHashSet<E> extends HashSet<E> implements Set<E>, Cloneable, java.io.Serializable { ...... // LinkedHashSet里面有一个LinkedHashMap public LinkedHashSet(int initialCapacity, float loadFactor) { map = new LinkedHashMap<>(initialCapacity, loadFactor); } ...... public boolean add(E e) {//适配器方法转换 return map.put(e, PRESENT)==null; } ...... }
五、TreeMap 和 TreeSet
1. TreeMap
TreeMap 和 TreeSet是什么关系呢,TreeSet的也是借助TreeMap实现的的适配器模式的体现。TreeMap实现了SortedMap接口,会根据key的大小对Map中的元素进行排序。key的大小判断在没有传入比较器Comparator的情况下通过自身的自然顺序比较。TreeMap底层通过红黑树实现。
红黑树是一颗近似平衡的二叉查找树,任何一个节点的左右子树高度差不会超过二者中较低的那个的一倍,TreeMap的每个节点即为一个键值对,红黑树的特性如下:
- 每个节点要么是黑色,要么是红色
- 根节点必须为黑色
- 红色节点不能连续,即红色节点的孩子和父亲只能是黑色
- 任何节点到树的末端的任何路径包含的黑色节点个数相同
每次对红黑树操作后都要使其满足上述条件,调整红黑树的策略主要是:
- 改变节点颜色;
- 改变树的结构(左旋操作、右旋操作)
根据红黑树的特点,TreeMap的containsKey(),get(),put(),remove()的时间复杂度都为log(n)
(1) get()
get(object key)返回指定key对于的value,该方法调用getEntry的到entry,然后返回entry.value,借助红黑树是二叉查找树,查找过程只需log(n)时间复杂度。
final Entry<K,V> getEntry(Object key) { ...... if (key == null)//不允许key值为null throw new NullPointerException(); Comparable<? super K> k = (Comparable<? super K>) key;//使用元素的自然顺序 Entry<K,V> p = root; while (p != null) { int cmp = k.compareTo(p.key); if (cmp < 0)//向左找 p = p.left; else if (cmp > 0)//向右找 p = p.right; else return p; } return null; }
(2) put()
put(K key, V value)方法将指定的键值对添加到map中,先进行查找(类似getEntry),如果要插入的元素已经存在则直接返回,否则在红黑树中插入entry,插入完成后若是破坏了红黑树约束需要进行调整。
public V put(K key, V value) { ...... int cmp; Entry<K,V> parent; if (key == null) throw new NullPointerException(); Comparable<? super K> k = (Comparable<? super K>) key;//使用元素的自然顺序 do { parent = t; cmp = k.compareTo(t.key); if (cmp < 0) t = t.left;//向左找 else if (cmp > 0) t = t.right;//向右找 else return t.setValue(value); } while (t != null); Entry<K,V> e = new Entry<>(key, value, parent);//创建并插入新的entry if (cmp < 0) parent.left = e; else parent.right = e; fixAfterInsertion(e);//调整 size++; return null; }
fixAfterInsertion具体实现包括颜色改变,左旋函数(rotateLeft),右旋函数(rotateRight)。
(3) remove()
remove(Object key)删除指定key对于的entry,也会先进行查找(getEntry),然后调用deleteEntry(Entry< K,V> entry)删除对应的entry,删除之后破坏红黑树约束时需要调整。
private void deleteEntry(Entry<K,V> p) { modCount++; size--; //若删除点p的左右子树都非空,需要用p的后继节点(大于x的最小的节点)代替p,然后删除 if (p.left != null && p.right != null) { Entry<K,V> s = successor(p);// 后继 p.key = s.key; p.value = s.value; p = s; } Entry<K,V> replacement = (p.left != null ? p.left : p.right); // 若删除点p只有一棵子树非空,用p的后继节点代替p,然后删除 if (replacement != null) { replacement.parent = p.parent; if (p.parent == null) root = replacement; else if (p == p.parent.left) p.parent.left = replacement; else p.parent.right = replacement; p.left = p.right = p.parent = null; if (p.color == BLACK) fixAfterDeletion(replacement);// 调整 } else if (p.parent == null) { root = null; } else { //若删除点p的左右子树都为空,直接删除 if (p.color == BLACK) fixAfterDeletion(p);// 调整 if (p.parent != null) { if (p == p.parent.left) p.parent.left = null; else if (p == p.parent.right) p.parent.right = null; p.parent = null; } } }
其中successor用于计算某节点后继节点,其思路为,如果t的右孩子不空,则t的后继是其右子树中最小的那个元素;如果t的右孩子为空,则t的后继是其第一个向左走的祖先。
static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) { if (t == null) return null; else if (t.right != null) {// t的右孩子不空,则t的后继是其右子树中最小的那个元素 Entry<K,V> p = t.right; while (p.left != null) p = p.left; return p; } else {// t的右孩子为空,则t的后继是其第一个向左走的祖先 Entry<K,V> p = t.parent; Entry<K,V> ch = t; while (p != null && ch == p.right) { ch = p; p = p.parent; } return p; } }
fixAfterDeletion函数用于在删除操作执行后调整红黑树结构。(其实只有在删除点是黑色的时候才会调用调整函数)。
2. TreeSet
public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E>, Cloneable, java.io.Serializable { ...... private transient NavigableMap<E,Object> m; // Dummy value to associate with an Object in the backing Map private static final Object PRESENT = new Object(); public TreeSet() { this.m = new TreeMap<E,Object>();// TreeSet里面有一个TreeMap } //方法适配 ...... public boolean add(E e) { return m.put(e, PRESENT)==null; } ...... }
六、WeakHashMap
WeakHashMap是基于弱引用的HashMap,它里面的entry随时可能被GC,因此对WeakHashMap的调用结果是不确定的,WeakHashMap的使用主要集中在缓存场景。
弱引用区别于强引用,如果一个对象具有弱引用,在GC线程扫描内存区域的过程中,不管当前内存空间足够与否,都会回收内存。如利用jdk中的ThreadLocal就是弱引用的。
七、ConcurrentHashMap
HashMap不是线程安全的,HashTable是线程安全的,但是其安全性由全局锁保证,因此效率很低。而ConcurrentHashMap 是将锁的范围细化来实现高效并发的。 基本策略是将数据结构分为一个一个 Segment(每一个都是一个并发可读的 hash table, 即分段锁)作为一个并发单元。 为了减少开销, 除了一处 Segment 是在构造器初始化的, 其他都延迟初始化。 并使用 volatile 关键字来保证 Segment 延迟初始化的可见性问题。
jdk1.8对ConcurrentHashMap做了一些改进:
改进一:取消segments字段,直接采用transient volatile HashEntry< K,V>[] table保存数据,采用table数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。
改进二:将原先table数组+单向链表的数据结构,变更为table数组+单向链表+红黑树的结构。在冲突链表长度过长的情况,如果还是采用单向链表方式,那么查询某个节点的时间复杂度为O(n);因此,对于个数超过8(默认值)的列表,jdk1.8中采用了红黑树的结构,那么查询的时间复杂度可以降低到O(logN),可以改进性能。
八、集合容器比较

参考
https://blog.csdn.net/starlh35/article/details/79262472
https://blog.csdn.net/P_Doraemon/article/details/80353579

 浙公网安备 33010602011771号
浙公网安备 33010602011771号