
面向对象第三单元总结
一、JML理论基础及应用工具链
(1)、JML理论基础
JML为Java建模语言,是一种行为接口规范语言,用来指定Java模块的行为。通常以//@(行注释)或者/*@ mycode @*/(块注释)两种形式呈现。并且一个JML规格的组成一般分为正常行为和异常行为(异常行为有时可以忽略)。同时在每种行为中,一般有以requires开头的前置条件来规定调用者需要满足的条件,以ensures为开头的表示方法调用后应该满足的条件,有时还可能有以assignable/modifiable开头的表示方法中会修改的变量。同时在异常行为的规格中还会出现以signal开头的表示在异常情况下应该抛出的异常。综上,一个比较全面的规格应该是:
normal_behavior
requires 逻辑表达式
assignable 变量名
ensures 逻辑表达式
also
expcetional_behavior
requires 逻辑表达式
assignable 变量名
ensures 逻辑表达式
signal 抛出异常
另外在JML中常用的原子表达式、量化表达式和操作符有:
1、\result 表示一个非void类型的方法执行后所获得的结果
2、\old(expr)用来表示expr在相应的方法执行前的值。同时注意如果v为Hashmap,且方法只对v进行插入删除操作,那么v.size()和\old(v).size的值相同,因为v的引用地址没有变。
3、\forall用来表示对于给定范围内的元素,每个元素都满足相应的约束。
4、\exists用来表示对于给定范围内的元素,存在某个元素满足相应的约束。
5、推理操作符: b_expr1==>b_expr2 或者 b_expr2<==b_expr1 。对于表达式 b_expr1==>b_expr2 而言,当 b_expr1==false ,或者 b_expr1==true 且 b_expr2==true 时,整个表达式的值为 true 。
6、变量引用操作符:\nothing指示一个空集;\everything指示一个全集。
JML应用工具链使用
通过下载配置相应的jar包,自动生成测试样例检测规格的正确性。
三、JMLUnit
测试文件为自己在Path类中找的比较简单的方法来进行测试,并且对规格进行了一定的修改如nodes.length改为nodes.size()等
package com.company;
import java.util.ArrayList;
public class Main {
public ArrayList<Integer> nodes = new ArrayList<Integer>();
//@ ensures \result == nodes.size();
public /*@pure@*/int size() {
return nodes.size();
}
/*@ requires index >= 0 && index < size();
@ assignable \nothing;
@ ensures \result == nodes.get(index);
@*/
public /*@pure@*/ int getNode(int index) {
return nodes.get(index);
}
//@ ensures \result == (nodes.size() >= 2);
public /*@pure@*/ boolean isValid() {
return nodes.size() >= 2;
}
public static void main(String[] args) {
System.out.print("");
}
}
之后生成测试文件进行编译并运行测试文件得到下图结果(我是在IDEA中运行的测试文件,在Powershell中运行提示找不到主类)
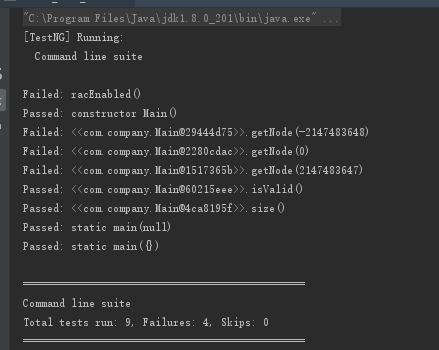
可知,在检测中getNode()的相关方法都出现了问题,分析原因可能是方法执行前并没有对传入的index进行判断。
四、架构设计梳理以及重构
第一次作业:
因为第一次作业没用考虑到代码性能的问题,所以在实现上都选择使用最熟悉的ArrayList作为数据的存储结构,在MyPath中用ArrayList储存路径上的点,在MyPathContainer中用ArrayList储存每条Path和id,导致当路径数比较多时,在进行查找时会发生耗时过长的问题,因此在强测中出现了很多CPU超时的测试点。
private ArrayList<Path> pathList;
private ArrayList<Integer> pidList;
private static int pathID;
第二次作业
第二次作业为了解决第一次作业CPU超时的问题,采用了在查询效率上更优的Hashmap作为存储数据的结构,同时在MyPathContainer中增加了4个新的Hash Map,conList的key为节点ID,value为该节点联通的节点中值最小的节点值,因此判断两个节点是否联通,只需通过key判断在该Hashmap中得到的value是否相同即可,edgeList的可以为节点ID,value为一个储存该节点连接的两条或者一条边上的另一个点的HashMap,dis和mark为计算最短路径时要用到的两个hashMap,即为迪杰斯特拉算法中的距离矩阵和标记矩阵的作用。
private HashMap<Integer,Integer> conList;
private HashMap<Integer,HashMap<Integer,Integer>> edgeList;
private HashMap<Integer,Integer> dis;
private HashMap<Integer,Integer> mark;
第三次作业
因为第三次作业加入了换乘问题,因此此时在不同路径上的同名的点也要看作是不同的点,为了实现这一目的我尝试了很多不同的以Hashmap为基础的储存结构,因为一个点的ID以及它的路径ID确定,那么这个点就可以唯一确定了。所以我首先想到了最简单的键值全是Integer的四层HashMap嵌套来存储边的关系,但是在后面的实现中发现,这种结构每次在遍历时十分麻烦,代码冗长并且出现Nullpointer异常时差错困难,之后又尝试了将HashMap的key使用自己定义的类,在后面的实现中发现,如果不自己重写Hashcode方法,就不能实现对自己类的是否相同进行判断,但是重写Hashcode又会使MyRailwaySystem中所有的HashMap的Hashcode方法改变,因此最后,对于每个点我选择用String来储存,结构为id,路径id,这样减少了HashMap的嵌套问题,同时也利用了Java中对String的方法。并且在边的权值HashMap的value上为一个大小为3的AarryList,分别储存两点间的票价,不满意度,换乘次数等值。第二次作业的结构则保持不变,避免改动影响之前的功能。
private HashMap<Integer,Path> pathLisT;
private static int pathID;
private HashMap<Integer,Integer> conList;
private HashMap<Integer,HashMap<Integer,Integer>> edgeList;
private HashMap<Integer,Integer> dis;
private HashMap<Integer,Integer> mark;
private HashMap<String,HashMap<String,ArrayList<Integer>>> railedge;
private HashMap<String,Integer> railmark;
private HashMap<String,ArrayList<Integer>> rail;
private HashMap<String,Integer> raildis;
private Mymethod mymethod;
五、作业bug和修复
第一次作业:第一次作业的getDistinctNodeCount()函数,对于没有路径时会出现空指针的错误,进行修复不会在方法一开始将随机Path中的随机一点加入arr中。
第二次作业:在第一次提交时,忘记在删除路径的同时对储存边关系的HashMap进行更新,导致在一条路径删除后不应该联通的点,查询结果仍为联通。以及后来发现的,因为在conList中的value为key所连接的点的最小的ID,因此,每加入一条路径,都要对conList进行一次更新,否则可能出现本来应该联通的点查询结果为不联通。
第三次作业:bug的大部分为第四部分中数据结构选择过程中出现的问题,修复的方式为重构了三次代码。最终实现了要求的功能。
六、规格撰写体会
规格为我们更加规范的去描述一个方法的要求和功能提供了一个有力的工具,方便我们进行一系列的测试。同时,也便于别人在不必完全理解我们代码的情况下也能根据规格使用我们的方法或者类。同时,我们在实现代码的时候也要满足规格为我们制定的每一条限定。我们在写规格的时候也要在保证正确性的前提下尽量的简洁。

