分区取模分库分表策略:多表事务分库内闭环解决方案
一 前言
技术同学都知道,当表数据超过一定量级,我们就需要通过分表来解决单表的性能瓶颈问题;当数据库负载超过一定水平线,我们就需要通过分库来解决单库的连接数、性能负载的瓶颈问题。
本文主要阐述在同时满足以下业务场景:
-
分表分库存储
-
需要对分表数量不同的表进行同事务操作
-
这些表的分库分表策略依赖的Sharding业务ID一致
等情况下,让这些不同数量级表,在同一个业务ID的事务操作路由到同一分库中的方案,省去解决垮库事务的烦恼。
二 案例
1 背景
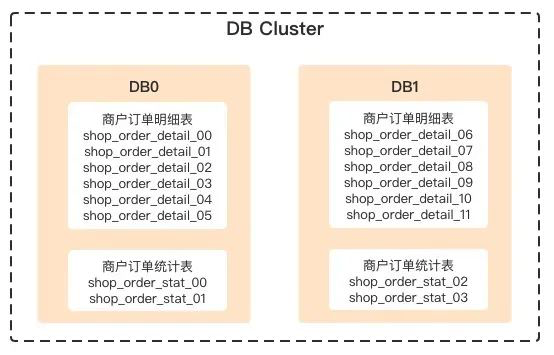
假设有2个数据库实例,需要保存商家订单明细和汇总2张表的数据,这2张表的 分库分表策略都用shop_id取模策略,按单表数据500w的原则进行分表分库:
(1)shop_order_detail 商家订单明细表,日均数据6000w
| 分表数量 | 6000w / 500w = 12张表 |
| 分表策略 | shop_id % 12 |
| 分库策略 | shop_id % 12 / 2 |
| 单库表数量 | 12 / 2 = 6张表 |
(2)shop_order_stat 商家订单统计表,日均数据2000w
| 分表数量 | 2000w / 500w = 4张表 |
| 分表策略 | shop_id % 4 |
| 分库策略 | shop_id % 4 / 2 |
| 单库表数量 | 4 / 2 = 2张表 |
配置完成后生成的库表:
然后我们要做这么一件事情:在同一个事务中,新增用户订单明细成功后,更新用户订单统计数据:

2 问题
此时,我要处理一笔 user_id = 3 的订单数据:
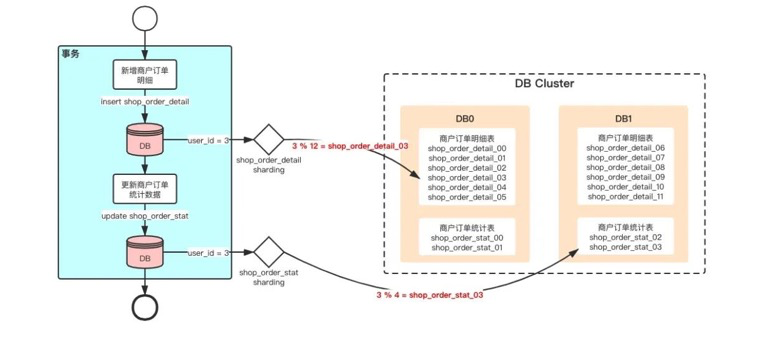
如图,执行新增shop_order_detail表操作的时候,操作被路由到了DB0中;执行更新shop_order_stat表操作的时候,操作被路由到了DB1。这时候 这两个操作跨库了,无法在同一个事务中执行, 流程异常中断。
如果用TDDL组件的话就会报这样的错:
### Cause: ERR-CODE: [TDDL-4603][ERR_ACCROSS_DB_TRANSACTION] Transaction accross db is not supported in current transaction policy三 解决方案
解决多表跨库事务的方案有很多,本文阐述的是如下解决方案:
将shop_order_stat作为shop_order_detail的映射基础表,调整shop_order_detail的分表策略,让shop_order_detail和shop_order_stat的数据都路由到同一个库中。
但该方案的前提是目标表的表数量是映射基础表表数量的N倍数。比如shop_order_stat的总表数量是4,shop_order_detail的总表数量是12,故shop_order_detail的总表数是shop_order_stat总表数的3倍。
shop_order_detail新分表分库策略的推导思路如下:
1 调整分库策略
首先,我们看shop_id在0~11范围内,用shop_id % 4分库分表策略shop_order_stat的sharding分布图:

用shop_id % 12分库分表策略shop_order_detail的sharding分布图:

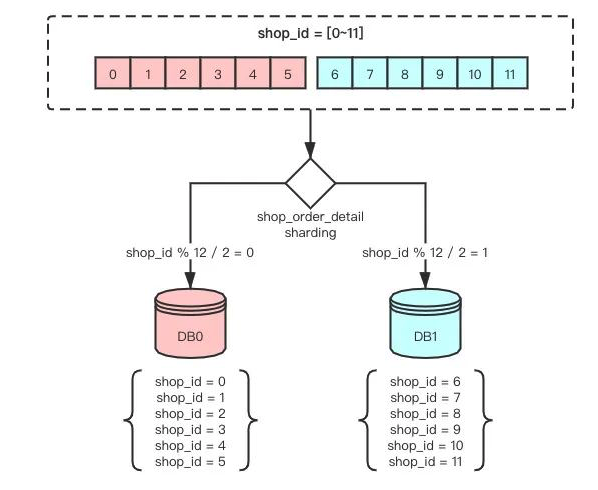
图中看出,两张表都是根据shop_id做sharding,但现有同一个shop_id有可能会被路由到不同的库中,导致跨库操作。
此时,我只需要把shop_order_detail的分库策略调整为跟shop_order_stat一致,保证同一个shop_id能路由到同一个DB分片中就能解决这个问题。调整后的sharding分布图:
但调整完分库策略后,原本的表映射策略就失效了:
原本的shop_id = 5数据可以通过shop % 12 = 5的取模策略映射到DB0的shop_order_detail_05表上。调整完分库策略后,shop_id = 9被路由到了DB0中,通过shop % 12 = 9的取模策略会映射到shop_order_detail_09这张表上,但shop_order_detail_09这张表不在DB0中,所以操作失败了。
这时候,我们需要调整分表策略,把shop_id = 9的数据既映射到DB0中的shop_order_detail_05表中。
2 分区取模策略
首先,以shop_order_stat的单库表数量2作为分块大小,总表数量4作为分区大小,对shop_id=[0~11]进行分区操作,并且将shop_id根据分块大小取模:
当前分库数量为2,shop_order_stat的单库表数量为6,计算出跨库步长=分库下标*单库表数量:
根据分区下标和分块大小,计算出分区步长=分区下标*分块大小,最后根据分块取模数+跨库步长+分区步长就能定位到最终的分表下标了:
这样就完成了把shop_id = 9的数据既映射到DB0中的shop_order_detail_05表中的工作。
四 计算公式
分表下标路由策略计算公式:
分表下标 = 业务ID取模 % 分块大小 + 业务ID取模 / 分块大小 * 单库表数量 + 业务ID取模 / 分区大小 * 分块大小
-
业务ID取模 = 业务ID % 总表数量
-
分区大小 = 目标映射表的总表数量
-
分块大小 = 目标映射表的单库表数量
以上面的案例为例,调整shop_order_detail的分库分表路由策略:
(1)shop_order_stat 商家订单统计表
| 分表数量 | 4张表 |
| 分表策略 | shop_id % 4 |
| 分库策略 | shop_id % 4 / 2 |
| 单库表数量 | 4 / 2 = 2张表 |
(2)shop_order_detail 商家订单明细表
| 分表数量 | 12张表 |
| 分表策略 |
// 总表数取模 |
| 分库策略 | shop_id % 4 / 2 |
| 单库表数量 | 12 / 2 = 6张表 |
TDDL sharding-rule配置代码示例:
<bean id="shop_order_stat" class="com.taobao.tddl.rule.TableRule"><property name="dbNamePattern" value="{0000}"/><property name="dbRuleArray" value="(#shop_id,1,4#.longValue() % 4).intdiv(2)" /><property name="tbNamePattern" value="shop_order_stat_{0000}"/><property name="tbRuleArray" value="#shop_id,1,4#.longValue() % 4" /></bean><bean id="shop_order_detail" class="com.taobao.tddl.rule.TableRule"><property name="dbNamePattern" value="{0000}"/><property name="dbRuleArray" value="(#shop_id,1,4#.longValue() % 4).intdiv(2)" /><property name="tbNamePattern" value="shop_order_detail_{0000}"/><property name="tbRuleArray"><value>def index =return index % 2 + (index % 4).intdiv(2) * 6 + index.intdiv(4) * 2</value></property><property name="allowFullTableScan" value="true"/></bean>
Java代码示例:
long shopId = 9;int dbs = 2;int tables = 12;int oneDbTables = 6;int partitionSize = 4;int blockSize = 2;int sharding = (int) (shopId % tables);// 目标分库int dbIndex = (int) (shopId % partitionSize / dbs);// 目标分表int tableIndex = sharding % blockSize + sharding % partitionSize / blockSize * oneDbTables + sharding / partitionSize * blockSize;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号