记录服务上线一年来的点点滴滴
2015年12月,也就是在一年前,开发了半年的云存储服务上线。这对于付出了半年努力的我们来说,是一件鼓舞人心的事件。因为这个服务在我们手上经历了从0到1的过程。这是我们自己的一小步,却是整个云存储服务的一大步。
我们开发的是一款视频监控类的软件,分为视频采集端跟观看端。采集端可以是专业摄像头,手机,无人机等各类智能设备,观看端一般是手机或者电脑。最基础的功能,就是视频观看,采集端实时采集图像,编码,传输,观看端进行点播服务。同时采集端可以监测视频画面的运动幅度,然后触发报警,并且会录制报警视频。我们的云存储服务就是将录制的报警视频上传到云端,并且在观看端提供查看功能
2.0 石器时代
第一个版本叫2.0,至于为什么叫2.0,或许这只是一个代号而已。
整个系统的框架如下:

整个系统由客户端, web服务器, 数据库, 文件存储服务器构成。文件服务器使用的是亚马逊的S3,对于小公司来说,选择亚马逊比自建存储的成本要低得多。
我们要求系统要尽可能及时的上传报警视频。一个报警视频大概录制30s,及时意味着报警一旦触发就要开始上传,而不是等报警视频录制结束了再上传录制下来的报警文件。而且在有些设备上,如摄像头,是可以没有存储卡的,但是也得能上传,所以选择上传报警视频文件的方式就不可取了。而在s3服务使用的是http协议上传文件,必须在上传文件之前告诉服务器文件的大小,即http头里面的content-length信息。为了解决这个问题,我们使用了分片上传的方式。就是首先根据视频的分辨率大小,计算出一个文件size,这个大约能存储10s左右的视频。在上传过程中,计算已经上传的数据量大小,当一个分片存储满之后,再开始另一个分片。在最后一个分片时,可能报警视频已经录制结束了,但是分片还没存满,这时候就用空数据填充。当然空数据的位置也得记录下来,这样观看端在播放时,就不至于把空数据当作正常数据,导致播放失败。除了正常的视频数据,在每段报警视频的最后还得记录视频中的I帧位置信息,主要是用于在播放时拖动,寻找位置信息。这一点是参考mp4文件的录制方式,由于我们使用的并不是标准的mp4格式,所以在上传视频的过程中,得将I帧的位置信息记录下来,待整个视频上传结束后,将位置信息存储在视频的尾部,最后不足一个分片的部分,再用空数据填上。
整个采集端来说,上传文件到亚马逊S3的过程就是如此,那么跟web服务器又是怎么交互的呢?
第一步,采集端在触发了一个报警时,要向web服务器申请一个EVENTID,作为这个报警事件的唯一标识,在之后上传文件都跟这个EVENTID绑定。观看端在播放时,根据这个EVENTID查到它对应的视频文件,然后去亚马逊S3上下载播放。
第二步,当采集端向亚马逊上传一个分片文件时,需要生成一个uri,然后才能向这个uri PUT数据。uri的生成,采集端可以直接向亚马逊申请,但是考虑到申请uri需要携带亚马逊的账户秘钥,放在客户端做不安全,所以申请uri还是放在web服务器上。当采集端需要上传文件,向web服务器去申请。每次采集端申请uri时,带上EVENTID,以及一个分片index,即告诉web服务器你要申请的是哪个eventid的第一个分片。生成的uri格式如下
http://xxxxxxxxxxxxxxxxxxxxxxxx/eventid/index.avi。前面的xxxx表示你在 s3上面创建的存储桶,index即是第几个文件, avi是文件的后缀名(这里是一个假设,叫什么都可以)。每开始一个新的分片,index自动加1,这样在只需要记录一个最终的index即可。下载时,根据最终的index大小,就可以把所有的文件都下载下来。当申请到uri之后,采集端就可以通过http协议向这个uri上传数据了。
第三步,在每个uri上传结束之后,向web服务器report一次 event信息。这个event信息,即是第一步开始时申请的eventid。汇报的信息,包括这个event 的触发时间,类型,视频时长,视频分辨率,音频的采样率,以及index。可以看到,每个uri上传结束都汇报一次的信息,其实也只有index的值不同,其他的值都一样。本来是可以等到在一个视频完全上传结束之后,一次性汇报一次event信息就OK了。但是考虑到,当一个视频正在上传的过程中,采集端软件crash了,或者小偷进来后里面将监控设备砸了,所以要每上传一个分片都要汇报一次。这样,观看端查看时,就可以看到一个未完成的视频了。除了这点外,也要注意到可能一个分片都没上传上去,就发生意外,所以我们在每次报警一触发,就立即抓一幅图片,上传到S3上。
上面基本就是整个系统上传部分的流程。web服务器负责生成eventid, 申请uri,以及写数据库。数据库只要存储一张event表项就可以了,表项里面记录了这个event 的详细信息。
在2.0版本中,虽然使用了redis缓存,用来降低mysql的访问压力,但是缓存的使用很简单,仅仅存储了一个采集端每天的event个数。这样观看端查询时,可以一次性获取到最近30天,每天的event个数。因为我们只给用户保留最近30天的数据,在redis上做了个数统计,就不用再去数据库读表统计了。
接下来再说说观看端的查询流程
首先,就是去查询采集端最近一个月每天的event个数。
然后,再具体查看某一天的报警时,带上日期,起 始时间段,去服务器查询event列表。在返回结果之后,将event信息作本地缓存。如果下次再查询,先查看本地缓存中是否存在,如果有就直接返回。
最后,根据web服务器返回的event信息,包括了这个event对应着亚马逊服务器上的uri,通过uri下载视频数据播放。同时也将视频数据缓存到本地文件中,供下次查看时使用。
3.0 青铜时代
2.0版本完成了0到1 的跨越,但是整个系统与服务还处于初级阶段。在刚上线之后,就开始了3.0的开发工作。
3.0版本的主要目的是完成视频数据与事件的分离。在2.0 版本中,我们以事件为单位,向AWS 上传文件,这种业务模型有着一定局限性,文件数据强依赖事件。理想的状态应该是,文件数据应该是一个整体,而不应该按照事件来划分。事件只需要记录,其对应的文件数据即可。对于一个事件,我们只需要在数据库保存它的一些基本信息(比如时间,类型等等),然后记录下这个事件对应的数据在云端的位置。这样做有两个好处:
1 数据与事件解耦,云端存储的只是一堆文件,易于维护
2 数据可以复用,比如两个事件发生的时间有重叠,在2.0版本,重叠的数据就要上传两次,浪费了存储空间
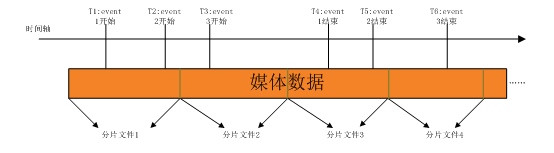
如图所示,我们在上传本地数据文件时,依然使用分片方式上传。每读取一帧数据,判断一下数据的时间戳有没有到达事件的开始时间。如果到达,那么就向web服务器汇报一次事件信息,并且记录下这个事件的开始在该分片文件中所处的位置。同样,判断当前正在处理的事件,比较时间戳,是否已经达到结束时间。如果已经结束,同样记录一个结束位置。一个分片文件可能对应多个event,有些event在这个分片文件的某个地方开始,有些event在这个分片文件的某个地方结束,还有些event可能占有整个分片文件。当一个分片文件上传结束时,需要向web服务器汇报分片文件信息,包括一些基本信息(大小,媒体参数,以及文件的uri等),以及分片文件与event的映射关系,即event的位置信息。在数据库的设计中,event存储一个表项,分片文件存储一个表项,映射关系存储一个表项。
关系如下图所示:

在event与file的映射表项中,存储了event与file id,以及这个event的开始位于file的位置(start_pos)以及结束位置file中的位置(end_pos)。如果这个event不在这个file中开始,也不在这个file中结束,那么说明这个file处于这个event的中间,既不是第一个分片,也不是最后一个分片,那么start_pos就是0,end_pos就是分片文件大小,即分片的结束。index就是这个分片文件是该event的第几个分片文件。
当我们观看某个云视频时,只需要在数据库中按照event进行查找,即可以返回这个event的所有分片文件。观看端拿到这些分片文件信息去亚马逊S3下载,就行播放。
对于数据库的影响:
2.0版本中,对于一个event在上传一个分片文件之后,就要向web服务器汇报一次。web服务器判断该event是否是第一次汇报,如果是在数据库插入一行新的表项;如果不是,则要更新之前插入的表项
3.0版本中,分片文件每次汇报,只需要插入表项即可,没有更新操作。event信息在开始的时候汇报一次,在结束的时候需要更新一次。
整体来说,3.0版本中减少了数据库的update操作。搞过数据库的人都知道,更新操作比插入对数据库的消耗大得多,从某种意义上来说也变相减轻了数据库的负载。
在3.0版本中,我们修改了redis的使用策略。2.0版本仅仅用redis来统计每天的event数量,但是其实在查询的时候,我们并不需要关心有多个数量。移动端查询时,是按业来查询的,每次查询10个,每次向下翻页就再查询10个,无法再翻页时,就说明已经查询出当天所有数据了。为了提高查询性能,我们将event的信息存储在redis里面。包括event 的触发时间,时长,icon信息。按照日期+cid(采集端的id,唯一标识)+type(event类型)作为key, value是一个list类型的值,保存当天所有的event id信息。然后再用eventid作key, value保存event的详细信息。这样在查询时,先按照cid+日期+类型找到列表key,从里面读取一页的数据。然后再根据这一页的数据,去查询里面每个event的详细信息。这样在查询列表时就不要再访问数据库了。
浓缩视频,压倒数据库的最后一根稻草
3.0版本上线三个月之后,系统运行的还算良好,但是我们发现数据库表项在飞速膨胀。我们的云服务用户已经有几万个,每个采集端每天平均都要上传几十条视频,所以按照这种速度,单表记录很快就来到了将近1000w。在mysql上,1000万几乎就是单表记录上限了。搞web的兄弟发现这一趋势后,做了分表方案。按照采集端的cid尾数 即(0-9),将event,file,以及映射表分成了10张表。虽然是解决了存储方面的问题,但是随着使用云服务的用户在不断增加,数据库的访问压力也在渐增。在3.0版本,我们新增了浓缩视频功能,就是将一天中的视频变化压缩成很短的几分钟。由于短视频每天才产生一个,所以我们在当天录制完之后,第二天的0点之后开始上传前一天产生的浓缩视频。这个功能在3.0版本上运行了一段时间,刚开始没有问题。但是在不知不觉中,却为自己刨了一个大坑。那段时间运营部门搞促销活动,用户登录送积分,用积分赠送云服务。突然有一天,测试人员早上过来后发现前一天的浓缩视频没有上传,翻开采集端日志一看,在凌晨0点之后那段时间,所有的web请求全部失败了。让运维同学查看了下凌晨那段时间发生了啥,一看惊呆了,在0点0分0秒那一刻,瞬间涌入了上万的请求。web服务器还好,有负载均衡,但是数据库只有一台,1s之内成千上万的请求,数据库不死才怪。由于在采集端做了失败重试,请求失败之后又会接着再次请求,数据库几乎一直在"卧倒"状态。幸好的是,采集端做了重试次数限制,所以基本在凌晨1点之后请求数也就慢慢降下来了。而这一切,都是由于浓缩视频集中在凌晨那段时间上传导致的。做促销活动的那几天,每天都会送出1w多的云服务,一下子就把数据库压垮了。其实解决这个问题的方法很简单,对于浓缩视频来说,我们只要保证上传了就可以,没必要非得全部挤在0点这个时间。我们把上传的时间随机延长至0~5点之间任何一个时间点,保证用户在早上起来后能查看到即可。很快就出了更新版本,服务器的访问压力随即降了下来,服务也回归正常。但是还是有一种隐约的不安,因为用户还在快速增长,不知道哪一天服务器又会遇到类似的问题。
4.0 火炮时代
3.0版本告一段落之后,随即开始了4.0版本的规划。4.0版本主要要解决的,就是服务器的访问压力,包括web服务器以及数据库。主要的性能瓶颈还在数据库上, web服务器作水平扩容很简单,因为在web服务器前面有nginx作为接入层做负载均衡,新增一台web服务器直接在nginx上加个配置就行了。但是数据库因为还没有做分库,所以只能先优化单台数据库的性能。使用Innodb引擎写性能每秒几百个,还能再撑一段时间。运行云存储服务的采集端大约有几万台,每秒钟的并发请求量还没那么大。但是数据量增长太快却是一个问题,虽然已经按照采集端的cid做了分表,但是表项的数据按照现在的增长速度很快又会到千万。分表也不可能这样无限制的做下去,但是分表策略却是可以调整的。其实我们的云服务有一个特点,就是数据只保存30天,查询的时候也是按天来查询,所以优先应该选择按天来分表才对。30天过后,直接删除掉老的表项,这样数据就不会无限量的膨胀。每天建一张表,数据量也不会达到单表上限。仅仅是这样实现一下其实也不复杂,但是考虑到版本兼容就没那么简单了。数据库还是只有一台,用户如果还是使用3.0的版本,我们也得按照新的分表方式来写表。这样就带来一个问题,即按时间分表,到底是按照event的触发时间来分表,还是按照event的上传时间来分表?这到底有什么区别呢。一般情况下,采集端在触发报警时,要立马上传视频。但是如果当时断网了,我们也会缓存在本地,等到网络恢复了再上传。所以有可能在当天触发的报警视频在第二天才能上传,也有可能更晚。刚开始想按照event的上传时间来做分表,这样做只要在服务器端判断下当前时间,将请求直接插入到对应日期的表项中就行了。但是这种做法,查询性能就比较差了。查询的时候按日期查询,这个日期是event的触发时间。我们并不能确切地知道这一天的报警视频到底被存储在哪些表项当中。只能遍历这一天的前后几张表,都查询一遍。很显然这会影响到查询性能。于是就考虑按照event的触发时间来做分表。但是又有另外一个问题,每个event在刚开始上传时,需要向web服务器汇报一次event信息,结束时要再汇报一次,更新event的上传状态和总时长。在开始汇报时,带了event的触发时间信息,但是在结束汇报时并没有带时间信息,只有event id。因为在3.0版本中,是根据cid来分表的,在结束汇报时带了cid信息。但是按照4.0版本的分表方式,老版本的采集端在结束时汇报,紧靠cid信息就不知道到哪张表里去更新了。简单的方法就是从当天的表项,往前遍历,直到查到为止。但是这样效率就很低了,更新一次带来的性能压力太大。后来想到了利用redis缓存,其实在event第一次汇报信息时,我们就已经将这些信息记录在redis里面了,所以只要根据eventid 在redis里面查到event的触发时间,然后就可以直接插入到数据库中。这是为了兼容3.0版本的策略,但是在4.0版本中,我们直接在申请eventid时,就带上了日期信息,保证获取到的eventid的前面几位就是event的触发时间日期。这样根据eventid就可以知道分表信息了,省略了查询缓存的过程。4.0版本的优化大概就是这样了。但是这还远未结束,仅仅的分表策略终究是有它的极限的,单台数据库的读写性能就摆在那里,下一步要做分库才行。为了提高性能,还可以使用异步化写入,即数据先保存到缓存中,然后批量写数据库,降低数据库的峰值压力。
总结:
很多时候, 我们谈到高并发 高负载,就会想到集群 ,分布式等一些高大上的名词。但是如果连单机性能都没有做好,谈那些也就是空中楼阁了。记得之前看到,说访问量排名全世界前20的网站stackoverflow,只有区区20多台服务器,而且用的是.net。可见对业务本身的优化,比基础设施的建设更加重要。业务优化应该达到两个目的:第一,使你的代码运行性能更高;第二,使得整体的业务架构易于扩展。谈集群,分布式部署,也不是一蹴而就。在开发代码时,就要考虑到能够水平扩展等因素。这样在未来,扩展集群时,便也轻松了许多

 浙公网安备 33010602011771号
浙公网安备 33010602011771号