jmeter获取web页面文本内容的两种方式
介绍两种jmeter获取页面文本的方式,以我的博客主页为例,我想获取标题“风城烟雨”这几个字

方式一:使用正则表达式提取器
1.在博客主页空白处鼠标右键查看页面源代码,在源代码中找到风城烟雨这几个字的位置,复制整行html代码,如下部分

2.将复制后的代码粘贴到jmeter对应接口的正则表达式提取器里,并使用正则表达式(.*?)替换“风城烟雨”这几个字,替换后内容如下图所示
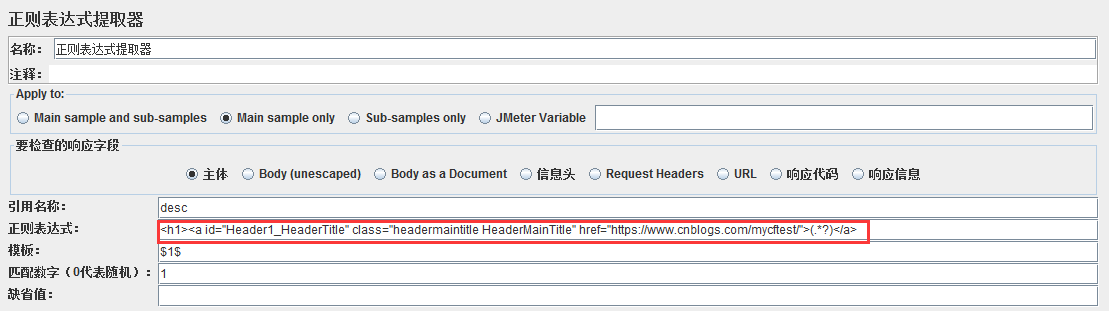
3.随便在添加一个http请求,请求名称设置为${desc}用以验证取值是否正确,执行一下脚本,最终结果如下

方式二:使用Xpath提取器
1.在博客主页按F12打开开发者工具,点击元素定位按钮,定位标题“风城烟雨”,发现标题有个id属性,我们可以通过这个id来定位到标题元素,最终的xpath代码为//*[@id="Header1_HeaderTitle"] (不了解xpath语法的同学可以自行学习一下,链接https://www.w3school.com.cn/xpath/xpath_syntax.asp)

2.在jmeter的接口上创建xpath提取器,内容如下

3.还是随便创建一个http请求,请求名称为${desc},执行一下,结果如下


 浙公网安备 33010602011771号
浙公网安备 33010602011771号