【转帖】数据迁移之Kettle的使用小结
数据迁移之Kettle的使用小结
场景
有五个数据库,其中两个SQL Server还有三个是Oracle10G。
目标
将两个SQL Server中的业务数据分别依照特定的逻辑迁移到三个Oracle数据库中。
Kettle的使用(基础)
Kettle的安装和配置
- 关于Kettle的安装可以直接到官网上去下载。
- 对于Kettle的配置需要有一个数据库,Kettle的数据库负责存储Kettle自身需要的元数据描述、任务、转换等,Kettle默认的登陆信息是admin/admin。
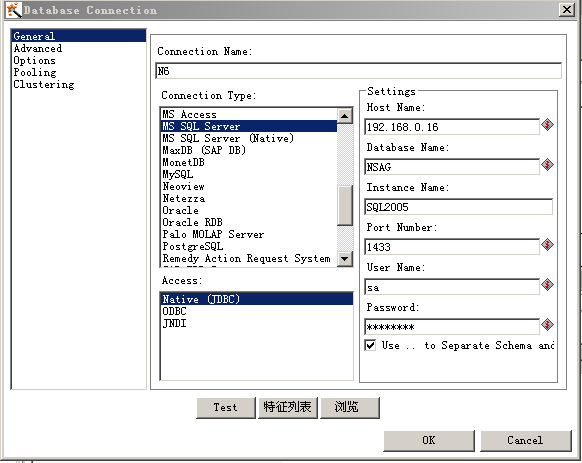
- 创建Oracle数据库连接直接依照提示输入即可,下图例出了SQL Server的连接。
SQL Server的连接注意区分Database Name和Instance Name。
|
|
Kettle的基础概念
- 作业,负责将[转换]组织在一起进而完成某一块工作,通常我们需要把一个大的任务分解成几个逻辑上隔离的作业,当这几个作业都完成了,也就说明这项任务完成了。
- 转换,定义对数据操作的容器,数据操作就是数据从输入到输出的一个过程,可以理解为比作业粒度更小一级的容器,我们将任务分解成作业,然后需要将作业分解成一个或多个转换,每个转换只完成一部分工作。
Kettle使用基础示例
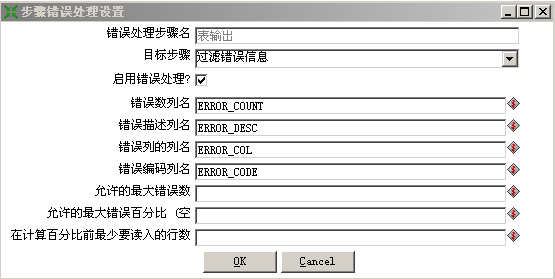
- Kettle的错误处理,有很多场景需要用到错误日志记录,如迁移过程中提示数据自身的问题、主/外键错误、违反约束等都要将当前场景记录到一个地方供后续特殊处理。
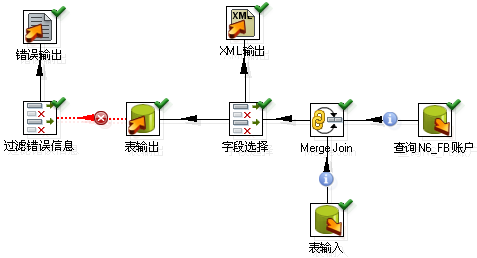
示例
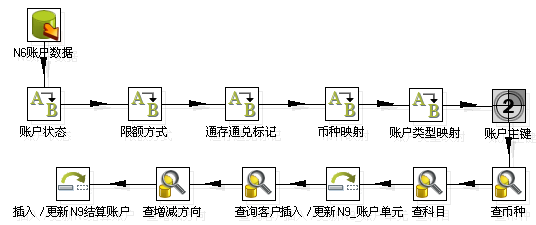
主要流程
错误信息配置
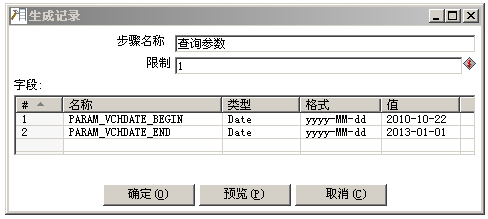
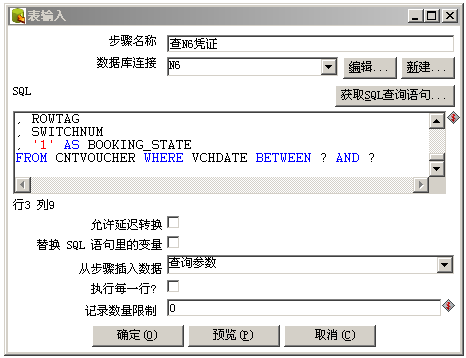
- 数据量很大的情况可以加上过滤参数处理
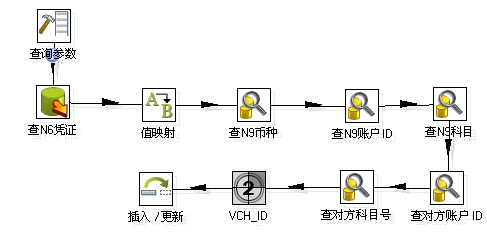
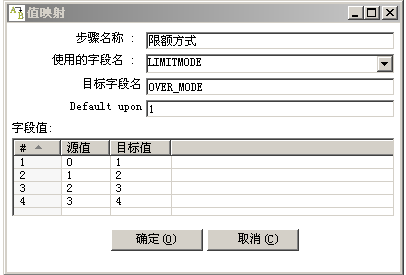
- 值的映射
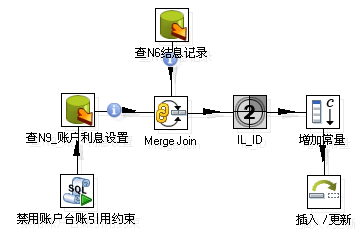
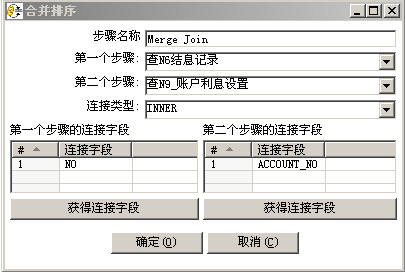
- 连接
这块要注意到连接所用到的原始数据一定是排过序的
参考资料
SpagoBI中文社区,致力于国际优秀开源BI套件SpagoBI在中国的普通推广;
联系我们QQ群:275725345

 浙公网安备 33010602011771号
浙公网安备 33010602011771号