
https://docs.trafficserver.apache.org/en/6.2.x/developer-guide/architecture/architecture.en.html?highlight=cachevc
http://blog.csdn.net/larryliuqing/article/details/7695944
http://blog.chinaunix.net/uid-23242010-id-2182847.html
http://blog.chinaunix.net/uid-23242010-id-147401.html
http://www.cnblogs.com/my_life/articles/6395022.html
https://docs.trafficserver.apache.org/en/6.2.x/developer-guide/architecture/architecture.en.html
https://github.com/portl4t/trafficserver-doc-zh/blob/master/arch/cache/cache-arch.md 中文版
l 裸盘:ats的cache支持硬件存储,不但支持文件系统的文件,还支持裸盘。裸盘支持在Linux中有被移除的可能,因为直接访问磁盘可以通过O_DIRECT替代。裸盘其实就是不使用文件系统的磁盘,由于没有文件系统自然也没有文件的概念。在内核中是直接走sd驱动,电梯层,到scsi到磁盘的,不需要走文件系统层和缓存层。O_DIRECT也是一样。
l cache span:一块连续的物理存储空间,一般是一个磁盘。
l cache volumn:一个逻辑和业务上的存储空间,可以横跨多个cache span。这就像lvm横跨多个物理磁盘划分的逻辑分区。
l cache strip:位于cache span(volumn)上的一条一条的存储带。数据都是组织在cache strip中。
l cache ID、cache key:cache key唯一的标示一个缓存对象,一般以url表示,cache ID则是从cache key计算得来的128位的MD5值。
l directory:在cache strip中的数据是由directory组织的。一个cache strip中有多个directory,每个directory中有多个条目。
每一个directory都对应一个cache,由cache id索引 (讲的不太准确,见下文分析)。(Directory在物理上按顺序包含三部分内容,分别是header,索引区Dir,footer。这里把Directory结构和Dir结构搞的有点混乱了)
每一个directory Dir都对应一个cache,由cache id索引
但directory Dir只是cache的一个索引,通过directory-->Dir可以找到cache在磁盘中的信息和实体。
而所有的directory Dir都是加载到内存的(其实Directory只有两个,Directory内部包含了Dir),所以如果一次cache查询结果是miss,就不需要磁盘(通过url计算得到cache id,但是查询内存发现该cache id没有对应directory Dir),就可以返回。
所以directory的存在让miss过程加速,但是如果找到了directory,每一个cache查询都需要接下来读取磁盘。值得注意的是,内存中只有directory,不包含实体,并且directory的大小是固定的,磁盘大小也是固定的,只要程序启动就会尽可能多的创建最多的directory,所以程序运行的过程中ats的内存需求是不会增加的(因为可以支持的缓存数是固定的,每条缓存在内存中的记录大小也是固定的)。
l segment、bucket: 并不是strip下面就是并排的一片directory dir,这些directory dir也是组织的。4个directory dir是一个bucket,多个bucket是一个segment。
在每个strip的头部都有一个空闲列表,里面是每个segment的directory dir空闲列表,也就是说有多少个segment在strip的头部就有多少个列表。
事实上,cache ID定位的并不是directory dir,而是bucket,strip的free list也不包含每个bucket的第一个directory,而是顺序的包含第4个、第3个、第2个。
如此,来了一个cache object的cache ID(128位),就可以定位到某个bucket,然后查看该bucket的第一个directory dir是不是used,如果used说明整个bucket都满了(只有后面3个都用完了才会用第1个),这个cache object就添加失败了。否则就会顺序的从4/3/2/1开始使用。
所以,综上可以看出,bucket实际上是一个哈希桶,用来处理哈希函数的碰撞情况,只给出了4个,说明只能处理4个cache ID一致的情况。所以segment和bucket这两种组织结构的引入,是为了解决管理问题。
l content:我们知道directory只是元数据,是要常驻内存的,存储了cache的索引。所以可以根据directory判断一个cache是否存在。如果发现了对应的directory,就得去取directory对应的cache的真实内容,这个内容就是放在content里的,位置由directory指明。directory的数目是动态计算出来的,总大小除以平均一个对象的大小就可以获得,平均一个对象的大小可以通过proxy.config.cache.min_average_object_size进行设置,从而控制directory的数目。content的大小是动态的,也是有限的,所以当content满的时候会自动从开头开始覆盖。但是并不会更新directory。直到下一次读取到directory的时候才会发现内容不存在,从而更新directory。这里可以带来的一个问题是,通过查看directory的统计值得到的结果是不准确的,并且一旦跑满数据量一直满的。
l fragment(分片):由于ats的并行性,不可能一下子存储太多的连续数据。所以大文件必然要分片(分成多个fragment)(否则并发的来很多大文件缓存请求将无法应对)。我们知道directory里面会指出数据在content中的位置,这里指出的只是该cache的第一个fragment,在这个fragment的头部又很多信息,包括其他的fragment到哪里去找,还包括其他的同名版本的存储directory(例如同一个url的png、jpg版本)
l SPDY:用户与同一个IP的http通信,无论是不是同一个网站,都复用一个tcp连接。这在大部分情况下是没用的,但是在用户使用的代理的时候就用处大了。因为用户的所有http请求都是发到代理去的,使用这个协议可以一整天都只使用一个tcp连接跑http,每个网战的http流只是tcp流里面的一个stream。这对提供代理效率和减轻代理和客户端负担有很大的提高。
================================================
http://itoedr.blog.163.com/blog/static/120284297201322211552355/
trafficserver的cache层包含两层,它在内存中维护了一个ram cache,缓存热点数据,该层的具体描述见这里,与此同时ts提供了磁盘一级的存储。
对比了一下trafficserver的cache存储系统与squid的coss文件系统,不难发现,它们的本质都是将cache看作是一个ring buffer,对这个buffer顺序写数据,当buffer满后回到首部继续顺序写入数据。在buffer满后,循环写入的机制不可避免会产生新写入的内容覆盖掉原来的内容而造成数据丢失。在web cache这种应用场景,这种实现方式是可行的,因为web cache的应用场景是在用户层与源服务器层之间加了一层存储做web加速之用,所以如果web cache上没有用户请求的数据,它会回源服务器请求数据,在取得源服务器的响应提供给用户端的同时,会把内容本地保存下来,下次用户请求相同的数据时,如果数据没有失效,也没有被覆盖,就可以直接从cache取出提供给用户服务,从而起到web加速的目的。
ts的存储系统支持任意大小的object读写,在ts安装好后,ts通过storage.config文件配置ts的存储路径,存储路径可以是一个文件,也可以直接是裸设备。
ts将用户配置的物理存储空间,逻辑上看作是一个个大文件,每个大文件视为一个ring buffer。通过向一个大文件写和读数据,从而避免了频繁调用open()与unlink()的系统开销。
当然,此ring buffer非内存中维护的ring buffer,它涉及到磁盘的写与读。当stop ts时候,缓存内容是持久化保存在磁盘上的,而当start ts时候,需要从磁盘上快速查找到用户查询的object。所以与传统文件系统如ext等一样,ts的cache系统需要对这个逻辑上视为一个大文件的disk空间进行格式化操作,以及索引的建立等操作。
Disk layout
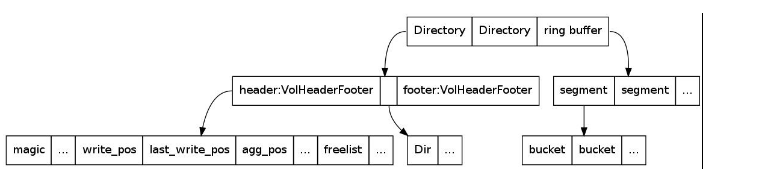
如图所示,ts将整个disk逻辑上分为3个部分,前面两个Directory,维护的是整个disk的索引区,在ts启动后,会将Directory加载到内存中,以加快cache查找速度。同时CacheSync这个Continuation会定期将Directory信息flush到磁盘上去。ts使用数据结构Dir代表索引区中的每个索引。ts将剩余的disk空间看作一个ring buffer,用于读写数据。
ts是以理想模型来建立disk layout的。在理想状态下,ring buffer中存储的是相同大小的object。在此条件下,对ring buffer进行逻辑分段,并对每一段进一步分桶,每个桶只保存4个object,一个object的元信息保存在一个索引Dir中。基于此,只要知道一个disk空间的大小,就可以计算出一个disk需要多少索引。对于不同的应用场景,通过估算最坏情况下object的最小平均大小,就可以估算出一个应用场景最多需要多少索引。这个最小平均object大小是可以配置的,在records.config文件中,通过修改变量proxy.config.cache.min_average_object_size可以调整值的大小,默认为1M。
在实际实现上,ts存储一个segment中所有object的索引,维护了一个链表freelist。freelist将所有未使用的Dir构成一个双向链表,当向磁盘上写object时,从freelist中取出一个Dir,当删除一个object时,则回收对应的Dir至freelist上。由于一个segment包含很多bucket,以segment为单位对索引构造一个freelist,就避开了理想模型中一个bucket只能包含4个Dir的限制(但从源码上可以看到,ts规定一个bucket最多包含100个Dir)。
在web应用中,ts根据用户请求的url,计算出这个object对应的key值,该值是一个由2个64位整数构成的数组,也就是4个32位的整数。ts通过对第一个32位整数做hash映射查找到object对应的Dir所在的segment,再通过第二个32位的整数做hash找到对应的bucket,最后在这个bucket上找到第一个没有使用的Dir,由此就得到了该object对应的索引。如果计算object的key值的算法足够高效,且每一级映射也足够高效,则正如理想模型所示,每个bucket中object数目为4个,在桶中查找一个未被使用的索引速度就会很快。
索引的格式
Directory在物理上按顺序包含三部分内容,分别是header,索引区Dir,footer。
header与footer对应的内存数据结构为VolHeaderFooter,它包含了很多维护索引区以及读写操作的元信息。这里,最重要的数据结构就是每一个segment对应的freelist的首节点元素构成的数组,由此就把整个索引区串了起来。
每个索引对应的内存数据结构为Dir,这是一个由5个16位的整数构成的数组,共10个字节。这些字节维护了一个object保存在磁盘上的所有元信息。
iocore/cache/P_CacheDir.h中提供了很多宏用于操作Dir。比如,宏dir_set_offset用来将一个object在磁盘上的位置信息保存下来,它使用Dir的第一个,第五个的所有16位,以及第二个元素的低八位,共40位,存储一个object在disk上的位置。
object的存储格式
数据结构Doc对应的是一个object在磁盘上的格式。

作为一个web cache,它实际上保存的就是源服务器对一个http请求的http响应,它包含head和body两个部分,对应上图中的hdr与data。
ts以一个fragment(分片)为单位,如果一个http响应,也就是一个object的大小小于一个fragment,则视它为一个小文件,否则,ts认为它是一个大文件。(分片的原因见上文)
这个fragment的大小是可配置的,在records.config文件中通过修改proxy.config.cache.target_fragment_size即可,默认为1M。
如果一个http响应作为一个object是一个小文件,ts是使用一个Doc完全保存该object的内容。这时,hdr保存响应头,data保存响应体。
如果一个http响应是一个大文件,这时ts首先单独使用一个Doc保存响应头的内容,而对于响应体,根据fragment的大小,会被切分为好几个fragment,每个fragment使用一个Doc保存。在响应头的head中,frags数组维护的是每个fragment在整个http响应内容中的位置信息。
对于小文件,该object生成的key值保存在first_key中。而对于一个大文件,整个http响应作为一个object生成的key值保存在first_key中,这个key值由响应头对应的Doc使用,由此在cache查找时,首先找到的就是一个http响应的头部。响应头的Doc的元素key保存的是第一个fragment的key值。而对于每个fragment,第一个fragment通过随机算法生成一个随机数作为一个key值保存在其对应的key中,后续的每个fragment的key值都是以前一个fragment的key值为种子随机生成的。
通过随机算法计算每个fragment使用的key值,这样做的好处是使得所获取的key值尽可能离散,从而映射到索引区的不同bucket中,避免了一个bucket不会维护太长的Dir链表。
下图描述各个fragment是如何通过随机数算法联系起来的:

第一个fragment的key值需要保证不和first_key冲突,否则重新随机生成一个,直到不冲突为止。
http://www.cnblogs.com/my_life/articles/7366455.html
- struct VolHeaderFooter
- {
- off_t write_pos; //当前磁盘写位置
- off_t last_write_pos; //上次磁盘写位置
- uint32_t sync_serial; //索引写回磁盘时,++sync_serial
- uint32_t write_serial; //写agg_buffer至磁盘时,++write_serial
- };
CacheKey

输入是url,包括scheme,user,password,host,path,params,query;
根据url生成md5值
proxy/hdrs/URL.cc:url_MD5_get_general)
md5是一种常见的信息摘要算法,md5的计算结果是16个字节;
md5计算分为三部分:MD5_Init(MD5_CTX *c);MD5_Update(MD5_CTX *c, const void *data, size_t len);MD5_Final(unsigned char *md, MD5_CTX *c);
md5_update的输入参数是(buffer内容):
保存object key
在proxy/hdrs/HTTP.h中,有如下函数:
inline void
HTTPInfo::object_key_set(INK_MD5 & md5)
{
int32_t* pi = reinterpret_cast(&md5);
m_alt->m_object_key[0] = pi[0];
m_alt->m_object_key[1] = pi[1];
m_alt->m_object_key[2] = pi[2];
m_alt->m_object_key[3] = pi[3];
}
这个函数就是将url的md5值保存为object的key;由于md5值有16个字节,m_object_key[4]数组有4个元素,每个元素保存4个字节;
Dir
由五个十六位构成的数组;总共10个字节;这五个数据主要是保存object在磁盘上的位置信息;
每个索引对应内存数据结构为Dir,是一个由5个16位的整数构成的数组,共10个字节。这些字节维护了一个object保存在磁盘上的所有元信息
它使用Dir的第一个,第五个的所有16位,以及第二个元素的低八位,共40位,存储一个object在disk上的位置。
struct Dir//保存的是索引
{
….
uint16_t w[5];
};
VolHeaderFooter
索引维护在磁盘的Directory中,其中header与footer保存的是索引元信息以及cache读写行为的信息,而位于它们之间的就是实际索引存储区。header与footer都是同一个数据结构类型VolHeaderFooter,这个结构中与本文相关的信息如下:
struct VolHeaderFooter//其中header与footer保存的是索引元信息以及cache读写行为的信息
{
unsigned int magic;
VersionNumber version; //版本号;
time_t create_time;
off_t write_pos; //写入到哪个位置 当前磁盘写的位置
off_t last_write_pos; //上次写入的位置
off_t agg_pos; //agg buffer的位置
uint32_t generation; // token generation (vary), this cannot be 0
uint32_t phase;
uint32_t cycle;
uint32_t sync_serial;//索引写到磁盘时,++1;
uint32_t write_serial;//agg数据写到磁盘时,++1;
uint32_t dirty;
uint32_t sector_size;
uint32_t unused; // pad out to 8 byte boundary
#if TS_USE_INTERIM_CACHE == 1
InterimVolHeaderFooter interim_header[8];
#endif
uint16_t freelist[1];
};
object的存储格式
数据结构Doc对应的是一个object在磁盘上的格式
作为一个web cache,它实际上保存的就是源服务器对一个http请求的http响应,它包含head和body两个部分,对应上图中的hdr与data。
ts以一个fragment为单位,如果一个http响应,也就是一个object的大小小于一个fragment,则视它为一个小文件,否则,ts认为它是一个大文件。这个fragment的大小是可配置的,在records.config文件中通过修改proxy.config.cache.target_fragment_size即可,默认为1M
如果一个http响应作为一个object是一个小文件,ts是使用一个Doc完全保存该object的内容。这时,hdr保存响应头,data保存响应体
如果一个http响应是一个大文件,这时ts首先单独使用一个Doc保存响应头的内容,而对于响应体,根据fragment的大小,会被切分为好几个fragment,每个fragment使用一个Doc保存。在响应头的head中,frags数组维护的是每个fragment在整个http响应内容中的位置信息。
对于小文件,该object生成的key值保存在first_key中。而对于一个大文件,整个http响应作为一个object生成的key值保存在first_key中,这个key值由响应头对应的Doc使用,由此在cache查找时,首先找到的就是一个http响应的头部。响应头的Doc的元素key保存的是第一个fragment的key值。而对于每个fragment,第一个fragment通过随机算法生成一个随机数作为一个key值保存在其对应的key中,后续的每个fragment的key值都是以前一个fragment的key值为种子随机生成的。
通过随机算法计算每个fragment使用的key值,这样做的好处是使得所获取的key值尽可能离散,从而映射到索引区的不同bucket中,避免了一个bucket不会维护太长的Dir链表。
下图描述各个fragment是如何通过随机数算法联系起来的:

第一个fragment的key值需要保证不和first_key冲突,否则重新随机生成一个,直到不冲突为止。
bucket存储OpenDirEntry
DLL bucket[OPEN_DIR_BUCKETS];
#define OPEN_DIR_BUCKETS 256
使用bucket存储所有的od(OpenDirEntry的对象);通过对key的前32位进行hash取模(模为OPEN_DIR_BUCKETS),定位od在bucket的索引位置,然后遍历bucket[b]的list,检查每一个元素的first_key是否等于key,如果等于则返回;
在OpenDir::open_write中首先遍历bucket[b]中的OpenDirEntry元素,如果proxy.config.cache.enable_read_while_writer设置为1并且first_key和当前cacheVc的first_key相同,则表示已经有相同的写操作,则将cacheVc插入writes,并且cachevc的od赋值为这个bucket中的od;如果bucket[b]对应的list是空,则新建一个OpenDirEntry,初始化,并且添加到bucket中。
在OpenDir::close_write将od从bucket中删除;调用OpenDir::close_write操作会将cacheVc对象从writes中删除,如果writes对象是空,则删除od;
每次有写操作的时候都会触发上述两个函数;
Bucket主要是记录当前读写操作的行为,记录当前有多少读操作,有多少写操作;如果读写操作完成,则会从bucket中删除;如果增加一个http write,则添加到wirtes,如果有相同的写,则od不需要重建,如果不是相同的写,则需要新建od;
Continuation
Continuation 是一个通用类,可以用于实现事件驱动的状态机。
通过包括其他状态和方法,Continuation 可以将状态与控制流结合,通常这样的设计用于支持分阶段,事件驱动的控制流程。
一定程度上来讲Continuation是整个异步回调机制的多线程事件编程基础。
在ATS中,Continuation是一个最最基础的抽象结构,后续的所有高级结构,如Action Event VC等都封装Continuation数据结构。
在学术上,这种以Continuation为底层的设计(编程)模型叫做Continuation的编程模型(方法)
这个技术相当古老
后来微软围绕这个方案,改进出了coroutine的编程模型(方法)

==================
This storage organized into a set of cache volumes which are defined in volume.config. These are the units that are used for all other administator level configuration.
span 被划分成volume,volume才是管理员所接触的配置单元
volume按百分比或绝对值来配置
The intersection of a cache volume and a cache span is a cache stripe. Each cache span is divided into cache stripes and each cache volume is a collection of those stripes.
cache strip是volume和span直接的联系纽带, span已stripe为单位进行划分,一些列的strip被组织成volume

 浙公网安备 33010602011771号
浙公网安备 33010602011771号