Python爬虫之利用BeautifulSoup爬取豆瓣小说(二)——回车分段打印小说信息
在上一篇文章中,我主要是设置了代理IP,虽然得到了相关的信息,但是打印出来的信息量有点多,要知道每打印一页,15个小说的信息全部会显示而过,有时因为屏幕太小,无法显示全所有的小说信息,那么,在这篇文章中,我主要想通过设置回车来控制每一条小说信息的输出,当我按下回车时,会显示下一条小说的信息,按“Q”时,会退出程序,同时,这个方法还会根据包含小说信息的页面数量来决定是否加载新的一页。
首先,我们导入一些模块,定义一个类,初始化方法,定义一些变量:
self.Novels里存放的是小说信息的变量,每一个元素是每一页的小说信息们
self.load决定程序是否继续运行的变量
1 #-*-coding:utf-8-*- 2 import urllib2 3 from bs4 import BeautifulSoup 4 5 class dbxs: 6 7 def __init__(self): 8 self.pageIndex = 0 9 self.Novels = [] 10 self.load = False
然后,我们获得html页面的内容,在这里,我们为了能够得到信息,而不让豆瓣服务器查封我们的IP,我们设置了请求的头部信息headers和代理IP。
1 def getPage(self, pageIndex): 2 #设置代理IP 3 enable_proxy = True 4 proxy_handler = urllib2.ProxyHandler({'Http': '116.30.251.210:8118'}) 5 null_proxy_handler = urllib2.ProxyHandler({}) 6 if enable_proxy: 7 opener = urllib2.build_opener(proxy_handler) 8 else: 9 opener = urllib2.build_opener(null_proxy_handler) 10 urllib2.install_opener(opener) 11 12 #设置headers,模拟浏览器登录 13 try: 14 url = 'https://www.douban.com/tag/%E5%B0%8F%E8%AF%B4/book' +'?start=' + str(pageIndex) 15 my_headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:55.0)'} 16 request = urllib2.Request(url, headers = my_headers) 17 response = urllib2.urlopen(request) 18 return response.read() 19 except urllib2.URLError, e: 20 if hasattr(e, "code"): 21 print e.code 22 if hasattr(e, "reason"): 23 print e.reason 24 return None
我们获得的是html源码,源码里有包含我们想要的元素,但是为了方便抓取数据,利用BeautifulSoup解析文档,这里我们用的解析器是html.parser。
这里的pageNovels是一个列表,存放的是每一页的所有小说信息,当某一小说信息没有rate一项时,这一条小说信息没有rates。
1 def getPageItems(self, pageIndex): 2 pageCode = self.getPage(pageIndex) 3 soup = BeautifulSoup(pageCode, 'html.parser') 4 contents = soup.find_all('dd') 5 pageNovels = [] 6 if contents: 7 for item in contents: 8 title = item.find(class_ = 'title').string 9 info = item.find(class_ = 'desc').string.strip() 10 rate = item.find(class_ = 'rating_nums') #这里不能加string,如果rate不存在,那么程序会报错:NoneType没有.string属性 11 if rate: 12 rates = rate.string 13 pageNovels.append([title, info, rates]) 14 else: 15 pageNovels.append([title, info]) 16 return pageNovels 17 else: 18 pageNovels.append('end') 19 return pageNovels
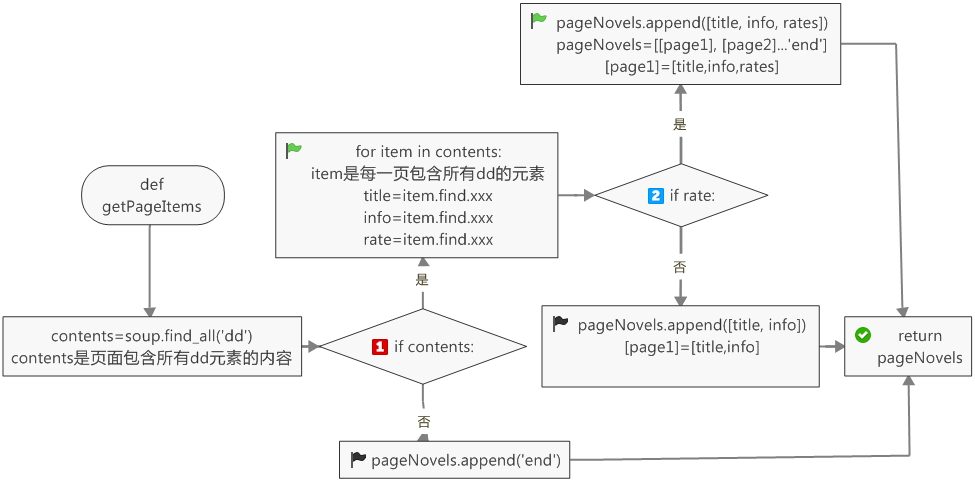
需要定义一个加载页,当self.Novels里的页数小于2,则程序加载下一页
1 def loadPage(self): 2 if self.load == True: 3 if len(self.Novels) < 2: 4 pageNovels = self.getPageItems(self.pageIndex) 5 if pageNovels: 6 self.Novels.append(pageNovels) 7 self.pageIndex += 15
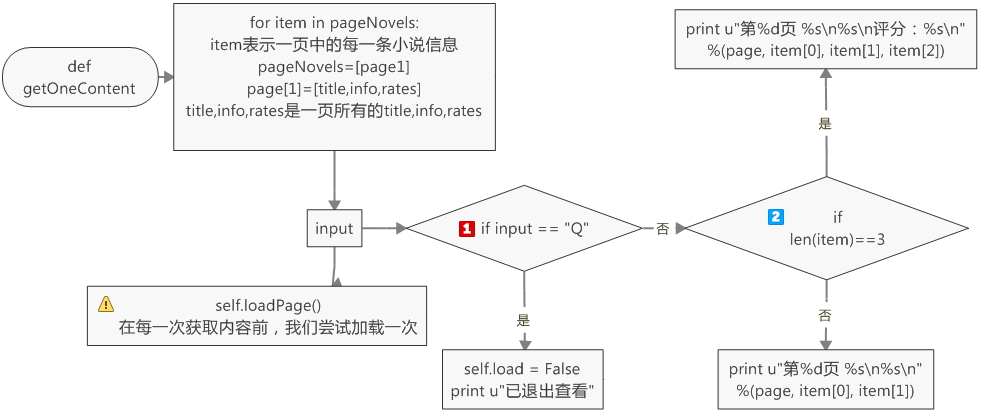
为了获得每一页的每一条小说信息,我们需要定义一个getOneContent的方法
1 def getOneContent(self, pageNovels, page): 2 for item in pageNovels: 3 input = raw_input() 4 self.loadPage() 5 if input == "Q": 6 self.load = False 7 print u"已退出查看" 8 return None 9 #if item[2]: #这里不能用if itme[2],当item[2]不存在时,会报错 10 if len(item) == 3: 11 print u"第%d页 %s\n%s\n评分:%s\n" %(page, item[0], item[1], item[2]) 12 else: 13 print u"第%d页 %s\n%s\n" %(page, item[0], item[1])
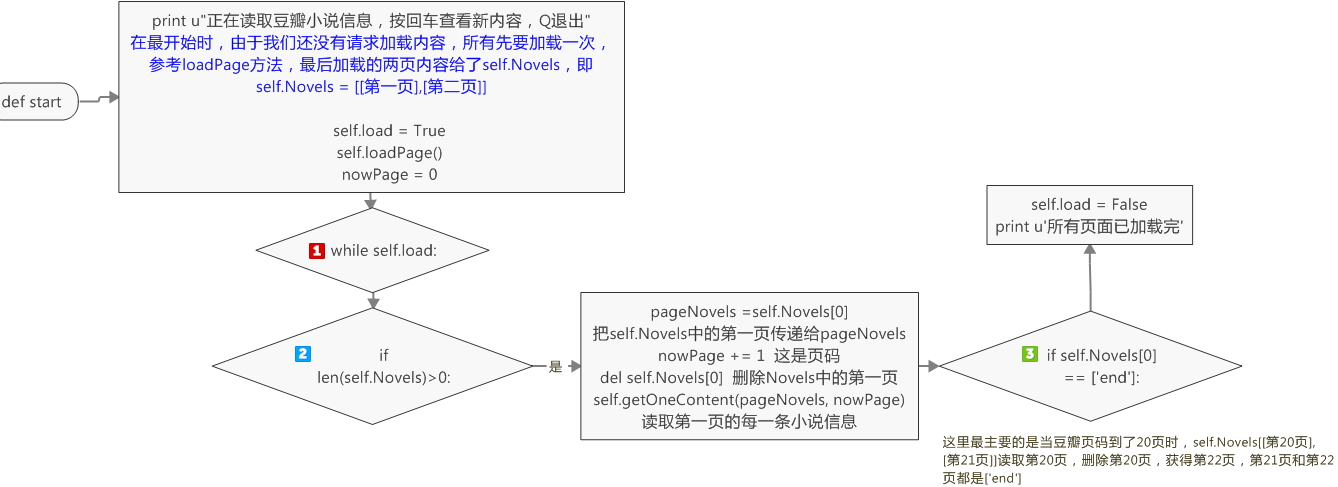
最后,我们得定义一个开始方法
1 def start(self): 2 print u"正在读取豆瓣小说信息,按回车查看新内容,Q退出" 3 self.load = True 4 self.loadPage() 5 nowPage = 0 6 while self.load: 7 if len(self.Novels) > 0: 8 pageNovels = self.Novels[0] 9 nowPage += 1 10 del self.Novels[0] 11 self.getOneContent(pageNovels, nowPage) 12 if self.Novels[0] == ['end']: 13 self.load = False 14 print u'所有页面已加载完'
整理一下,最后的总代码:
1 #-*-coding:utf-8-*- 2 import urllib2 3 from bs4 import BeautifulSoup 4 import time 5 import random 6 7 class dbxs: 8 9 def __init__(self): 10 self.pageIndex = 0 11 self.Novels = [] 12 self.load = False 13 14 15 #获取html页面的内容 16 def getPage(self, pageIndex): 17 #设置代理ip 18 enable_proxy = True 19 proxy_handler = urllib2.ProxyHandler({'Http': '116.30.251.210:8118'}) 20 null_proxy_handler = urllib2.ProxyHandler({}) 21 if enable_proxy: 22 opener = urllib2.build_opener(proxy_handler) 23 else: 24 opener = urllib2.build_opener(null_proxy_handler) 25 urllib2.install_opener(opener) 26 try: 27 url = 'https://www.douban.com/tag/%E5%B0%8F%E8%AF%B4/book' + "?start=" + str(pageIndex) 28 #设置请求头部信息,模拟浏览器的行为 29 my_headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:55.0)'} 30 request = urllib2.Request(url, headers = my_headers) 31 response = urllib2.urlopen(request) 32 return response.read() 33 except urllib2.URLError, e: 34 if hasattr(e, "code"): 35 print e.code 36 if hasattr(e, "reason"): 37 print e.reason 38 return None 39 40 def getPageItems(self, pageIndex): 41 pageCode = self.getPage(pageIndex) 42 soup = BeautifulSoup(pageCode, 'html.parser') 43 contents = soup.find_all('dd') 44 pageNovels = [] 45 if contents: 46 for item in contents: 47 title = item.find(class_ = 'title').string 48 info = item.find(class_ = 'desc').string.strip() 49 rate = item.find(class_ = 'rating_nums') #这里不能加string,如果rate不存在,那么程序会报错:NoneType没有.string属性 50 if rate: 51 rates = rate.string 52 pageNovels.append([title, info, rates]) 53 else: 54 pageNovels.append([title, info]) 55 return pageNovels 56 else: 57 pageNovels.append('end') 58 return pageNovels 59 60 61 def loadPage(self): 62 if self.load == True: 63 if len(self.Novels) < 2: 64 pageNovels = self.getPageItems(self.pageIndex) 65 if pageNovels: 66 self.Novels.append(pageNovels) 67 self.pageIndex += 15 68 69 70 71 #打印每一个小说的信息 72 def getOneContent(self, pageNovels, page): 73 for item in pageNovels: 74 input = raw_input() 75 self.loadPage() 76 if input == "Q": 77 self.load = False 78 print u"已退出查看" 79 return None 80 #if item[2]: #这里不能用if itme[2],当item[2]不存在时,会报错 81 if len(item) == 3: 82 print u"第%d页 %s\n%s\n评分:%s\n" %(page, item[0], item[1], item[2]) 83 else: 84 print u"第%d页 %s\n%s\n" %(page, item[0], item[1]) 85 86 87 88 #创建一个开始方法 89 def start(self): 90 print u"正在读取豆瓣小说信息,按回车查看新内容,Q退出" 91 self.load = True 92 self.loadPage() 93 nowPage = 0 94 while self.load: 95 if len(self.Novels) > 0: 96 pageNovels = self.Novels[0] 97 nowPage += 1 98 del self.Novels[0] 99 self.getOneContent(pageNovels, nowPage) 100 if self.Novels[0] == ['end']: 101 self.load = False 102 print u'所有页面已加载完' 103 104 105 106 DBXS = dbxs() 107 DBXS.start()
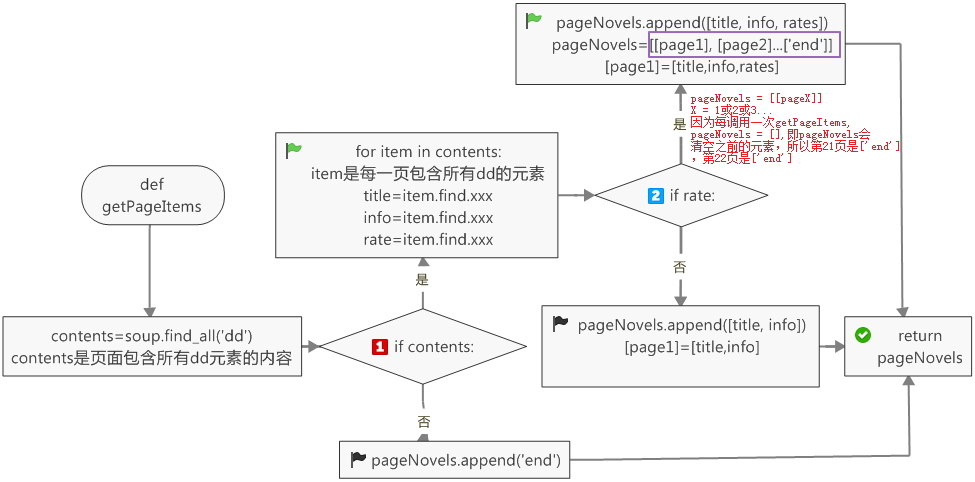
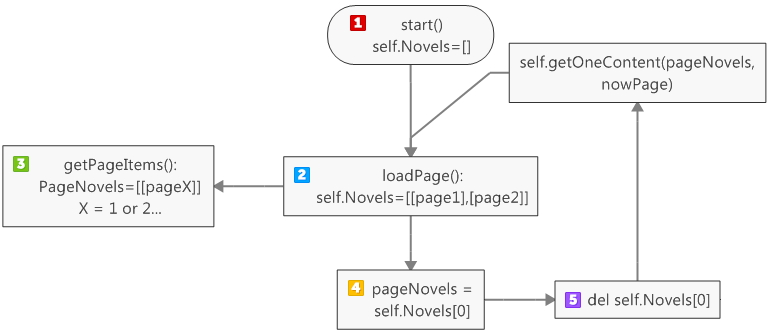
有必要解释一下self.Novels和PageNovels

 浙公网安备 33010602011771号
浙公网安备 33010602011771号