Python爬虫之编写一个可复用的下载模块
看用python写网络爬虫第一课之编写可复用的下载模块的视频,发现和《用Python写网络爬虫》一书很像,写了点笔记:
1 #-*-coding:utf-8-*- 2 3 import urllib2 4 5 #下载时遇到的错误经常是临时性的,比如服务器过载时返回的 503 Service Unavailable错误。对于此类错误,我们可以尝试重新下载 6 8 def download(url, num_retries = 2): #默认重试次数为2次 9 print "Downloading:", url 10 try: 11 request = urllib2.Request(url) 12 response = urllib2.urlopen(url) 13 html = response.read() 14 except urllib2.URLError as e: 15 print "Download error:", e.reason #打印报错的原因 16 html = None 17 if num_retries > 0: 18 if hasattr(e, 'code') and 500 <= e.code < 600: #错误码500-600是服务器端错误 19 return download(url, num_retries - 1) #当download函数遇到5xx错误码时,将会递归调用函数自身进行重试,此时重试次数-1 20 return html 21 22 download('http://httpstat.us/500') #如果想改变重试此时,可以写成download('http://httpstat.us/500', 1) ,此时将会重试一次
运行结果:
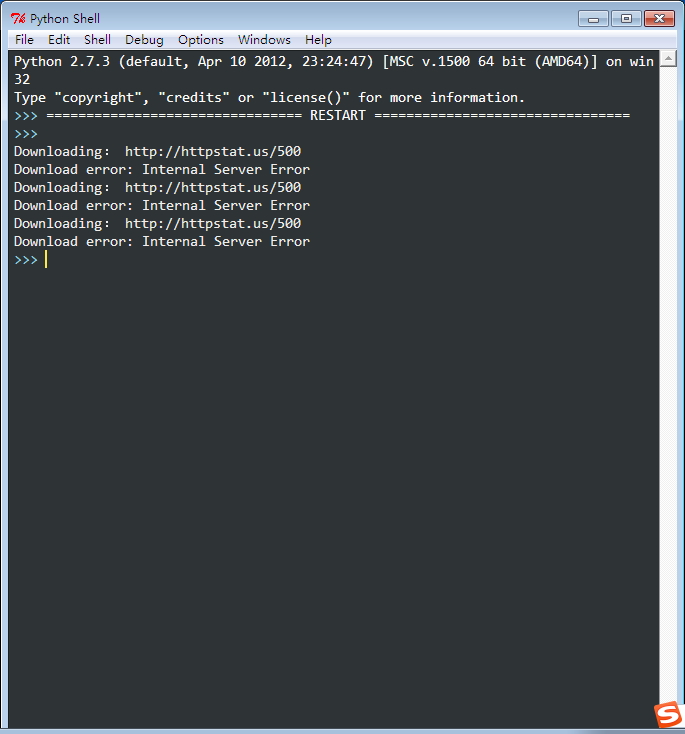
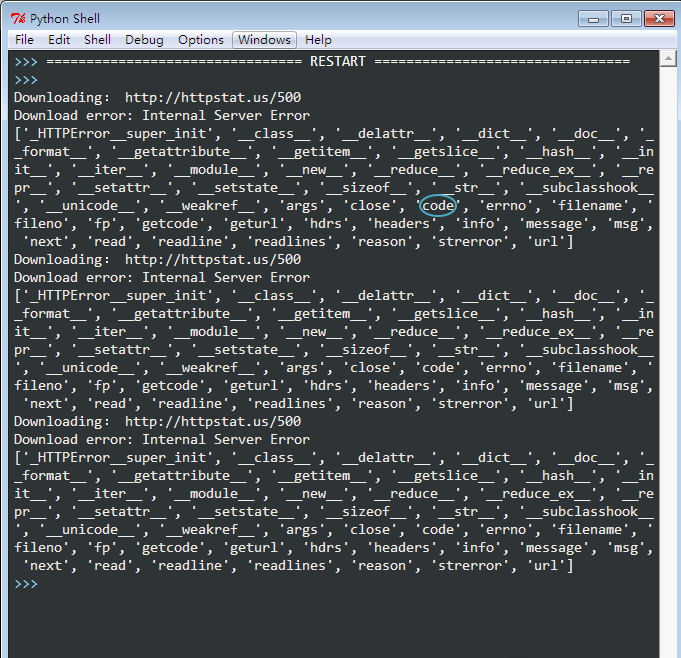
我们也可以加一个print dir(e)来查看e中的内容,e中的确包含着code

 浙公网安备 33010602011771号
浙公网安备 33010602011771号