python并发编程实战(四):使用多线程,python爬虫被加速10倍
1|0python创建多线程的方法

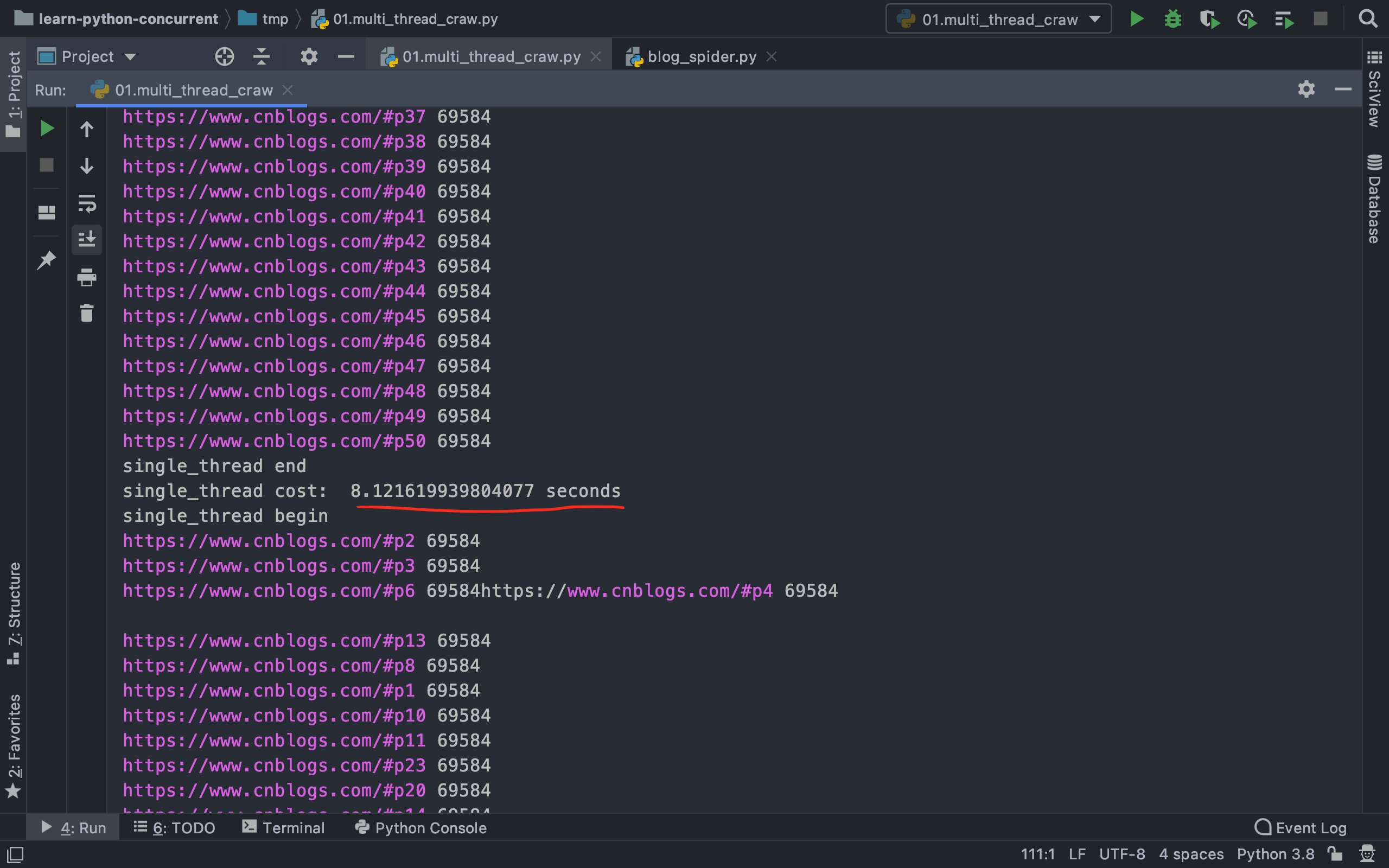
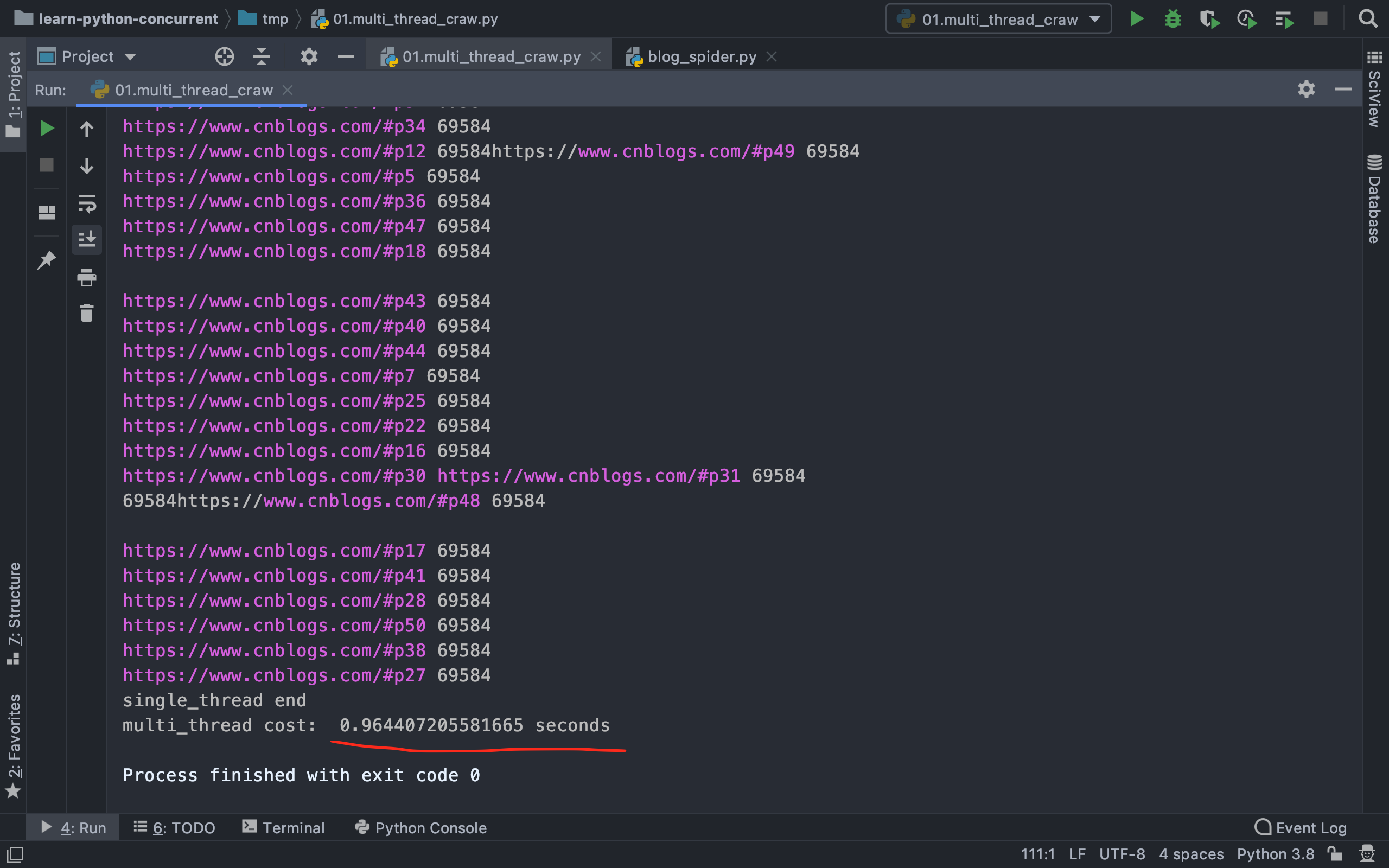
2|0单线程、多线程爬取博客园速度对比
tmp/blog_spider.py
01.multi_thread_craw.py
爬取速度对比
可以看到,速度足足提高了8倍,当然和电脑的性能也有关系
单线程
多线程
__EOF__

本文作者:cnhkzyy
本文链接:https://www.cnblogs.com/my_captain/p/16437989.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
本文链接:https://www.cnblogs.com/my_captain/p/16437989.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
分类:
并发编程


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?
2018-07-02 显性等待的另一种写法
2018-07-02 selenium定位多个嵌套iframe
2017-07-02 《Advanced Bash-scripting Guide》学习(十一):shift的用法
2017-07-02 《Advanced Bash-scripting Guide》学习(十):利用whois查询域名信息