

如何免费创建云端爬虫集群
在线体验
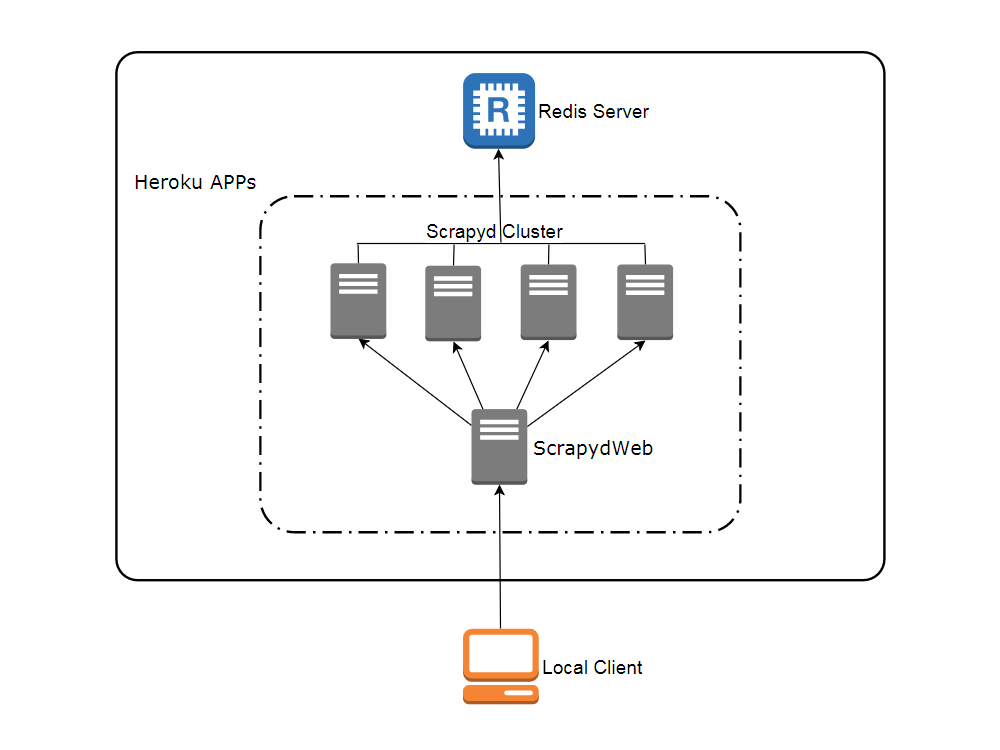
网络拓扑图

注册帐号
- Heroku
访问 heroku.com 注册免费账号(注册页面需要调用 google recaptcha 人机验证,登录页面也需要科学地进行上网,访问 app 运行页面则没有该问题),免费账号最多可以创建和运行5个 app。
- Redis Labs(可选)
访问 redislabs.com 注册免费账号,提供30MB 存储空间,用于下文通过 scrapy-redis 实现分布式爬虫。

通过浏览器部署 Heroku app
- 访问 my8100/scrapyd-cluster-on-heroku-scrapyd-app 一键部署 Scrapyd app。(注意更新页面表单中 Redis 服务器的主机,端口和密码)
- 重复第1步完成4个 Scrapyd app 的部署,假设应用名称为 svr-1 , svr-2 , svr-3 和 svr-4
- 访问 my8100/scrapyd-cluster-on-heroku-scrapydweb-app 一键部署 ScrapydWeb app,取名 myscrapydweb
- (可选)点击 dashboard.heroku.com/apps/myscrapydweb/settings 页面中的 Reveal Config Vars 按钮相应添加更多 Scrapyd server,例如 KEY 为 SCRAPYD_SERVER_2 , VALUE 为 svr-2.herokuapp.com:80#group2
- 访问 myscrapydweb.herokuapp.com
- 跳转 部署和运行分布式爬虫 章节继续阅读。
自定义部署
安装工具
- Git
- Heroku CLI
- Python client for Redis:运行 pip install redis 命令即可。
下载配置文件
新开一个命令行提示符:
git clone https://github.com/my8100/scrapyd-cluster-on-heroku cd scrapyd-cluster-on-heroku
登录 Heroku
heroku login # outputs: # heroku: Press any key to open up the browser to login or q to exit: # Opening browser to https://cli-auth.heroku.com/auth/browser/12345-abcde # Logging in... done # Logged in as username@gmail.com
创建 Scrapyd 集群
- 新建 Git 仓库
cd scrapyd git init # explore and update the files if needed git status git add . git commit -a -m "first commit" git status
- 部署 Scrapyd app
heroku apps:create svr-1 heroku git:remote -a svr-1 git remote -v git push heroku master heroku logs --tail # Press ctrl+c to stop logs outputting # Visit https://svr-1.herokuapp.com
-
添加环境变量
- 设置时区
# python -c "import tzlocal; print(tzlocal.get_localzone())" heroku config:set TZ=Asia/Shanghai # heroku config:get TZ
- 添加 Redis 账号(可选,详见 scrapy_redis_demo_project.zip 中的 settings.py)
heroku config:set REDIS_HOST=your-redis-host heroku config:set REDIS_PORT=your-redis-port heroku config:set REDIS_PASSWORD=your-redis-password
-
重复上述第2步和第3步完成余下三个 Scrapyd app 的部署和配置: svr-2 , svr-3 和 svr-4
创建 ScrapydWeb app
- 新建 Git 仓库
cd .. cd scrapydweb git init # explore and update the files if needed git status git add . git commit -a -m "first commit" git status
- 部署 ScrapydWeb app
heroku apps:create myscrapydweb heroku git:remote -a myscrapydweb git remote -v git push heroku master
-
添加环境变量
- 设置时区
heroku config:set TZ=Asia/Shanghai
- 添加 Scrapyd server(详见 scrapydweb 目录下的 scrapydweb_settings_v8.py)
heroku config:set SCRAPYD_SERVER_1=svr-1.herokuapp.com:80 heroku config:set SCRAPYD_SERVER_2=svr-2.herokuapp.com:80#group1 heroku config:set SCRAPYD_SERVER_3=svr-3.herokuapp.com:80#group1 heroku config:set SCRAPYD_SERVER_4=svr-4.herokuapp.com:80#group2
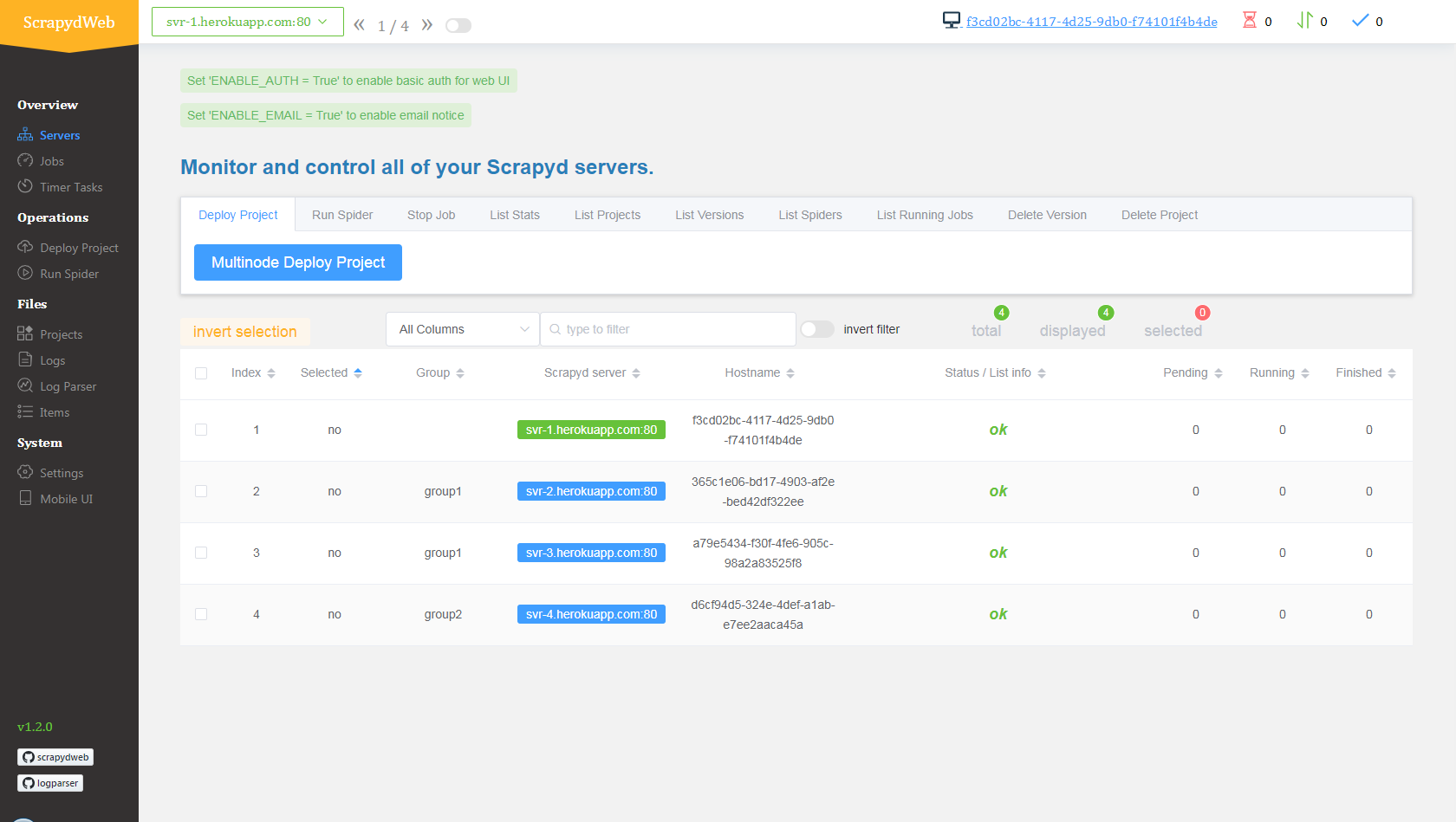
部署和运行分布式爬虫
- 上传 demo 项目,即 scrapyd-cluster-on-heroku 目录下的压缩文档 scrapy_redis_demo_project.zip
- 将种子请求推入 mycrawler:start_urls 触发爬虫并查看结果
In [1]: import redis # pip install redis In [2]: r = redis.Redis(host='your-redis-host', port=your-redis-port, password='your-redis-password') In [3]: r.delete('mycrawler_redis:requests', 'mycrawler_redis:dupefilter', 'mycrawler_redis:items') Out[3]: 0 In [4]: r.lpush('mycrawler:start_urls', 'http://books.toscrape.com', 'http://quotes.toscrape.com') Out[4]: 2 # wait for a minute In [5]: r.lrange('mycrawler_redis:items', 0, 1) Out[5]: [b'{"url": "http://quotes.toscrape.com/", "title": "Quotes to Scrape", "hostname": "d6cf94d5-324e-4def-a1ab-e7ee2aaca45a", "crawled": "2019-04-02 03:42:37", "spider": "mycrawler_redis"}', b'{"url": "http://books.toscrape.com/index.html", "title": "All products | Books to Scrape - Sandbox", "hostname": "d6cf94d5-324e-4def-a1ab-e7ee2aaca45a", "crawled": "2019-04-02 03:42:37", "spider": "mycrawler_redis"}']

总结
- 优点
- 免费
- 可以爬 Google 等外网
- 可扩展(借助于 ScrapydWeb)
- 缺点
- 注册和登录需要科学地进行上网
- Heroku app 每天至少自动重启一次并且重置所有文件,因此需要外接数据库保存数据,详见 devcenter.heroku.com
GitHub 开源
my8100/scrapyd-cluster-on-heroku
