摘要:
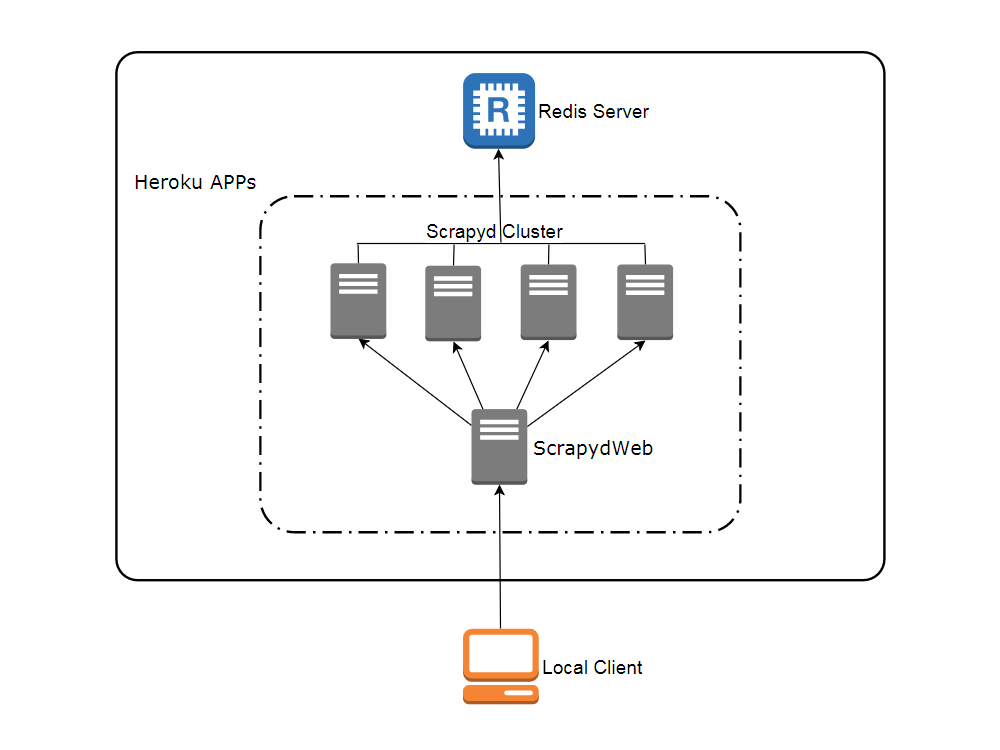
开源项目 如何通过 Scrapyd + ScrapydWeb 简单高效地部署和监控分布式爬虫项目 LogParser v0.8.0 发布:一个用于定期增量式解析 Scrapy 爬虫日志的 Python 库,配合 ScrapydWeb 使用可实现爬虫进度可视化 如何免费创建云端爬虫集群 时隔五年,Sc 阅读全文
posted @ 2017-07-25 12:58
my8100
阅读(838)
评论(0)
推荐(0)

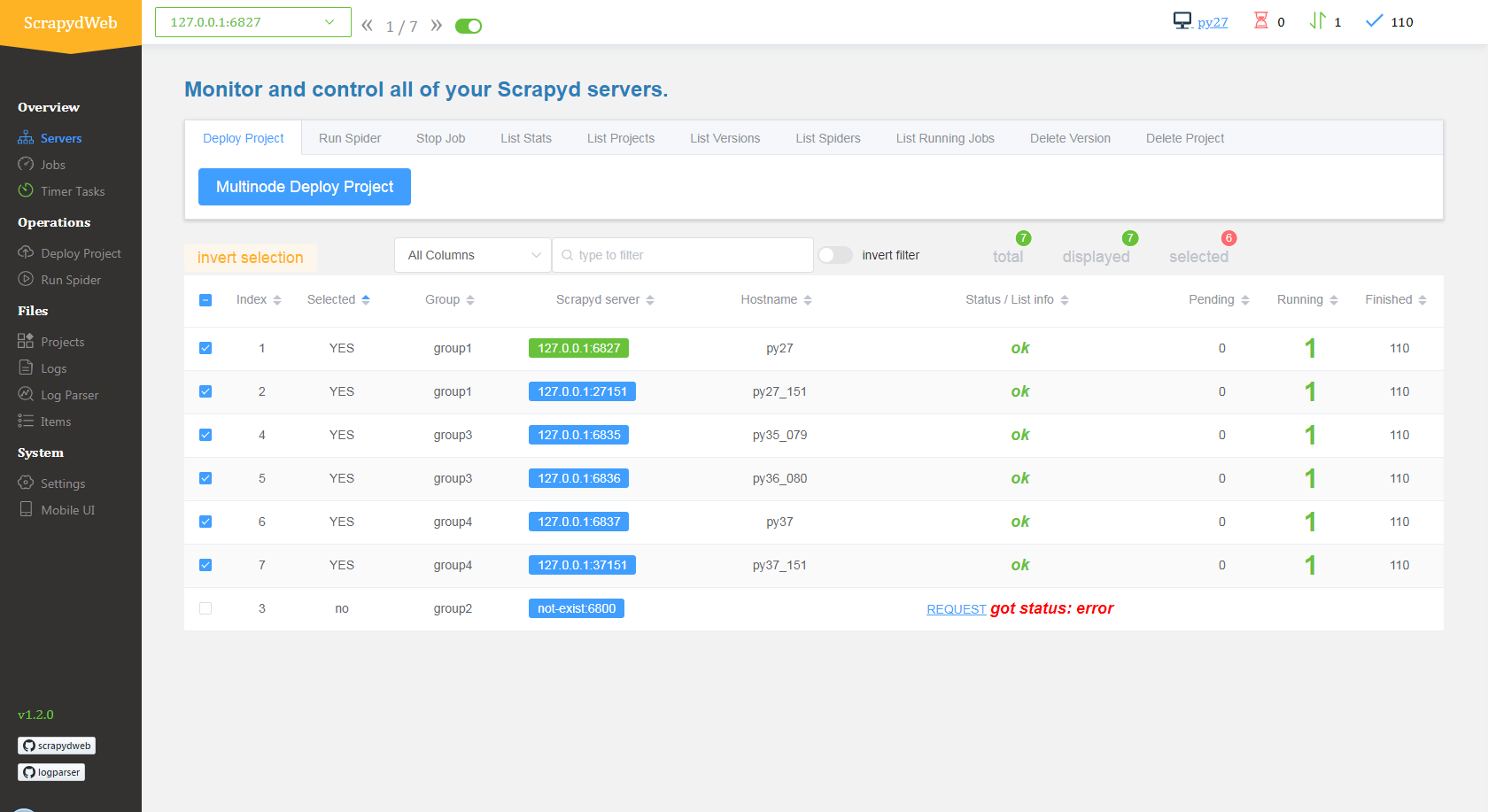 阅读全文
阅读全文
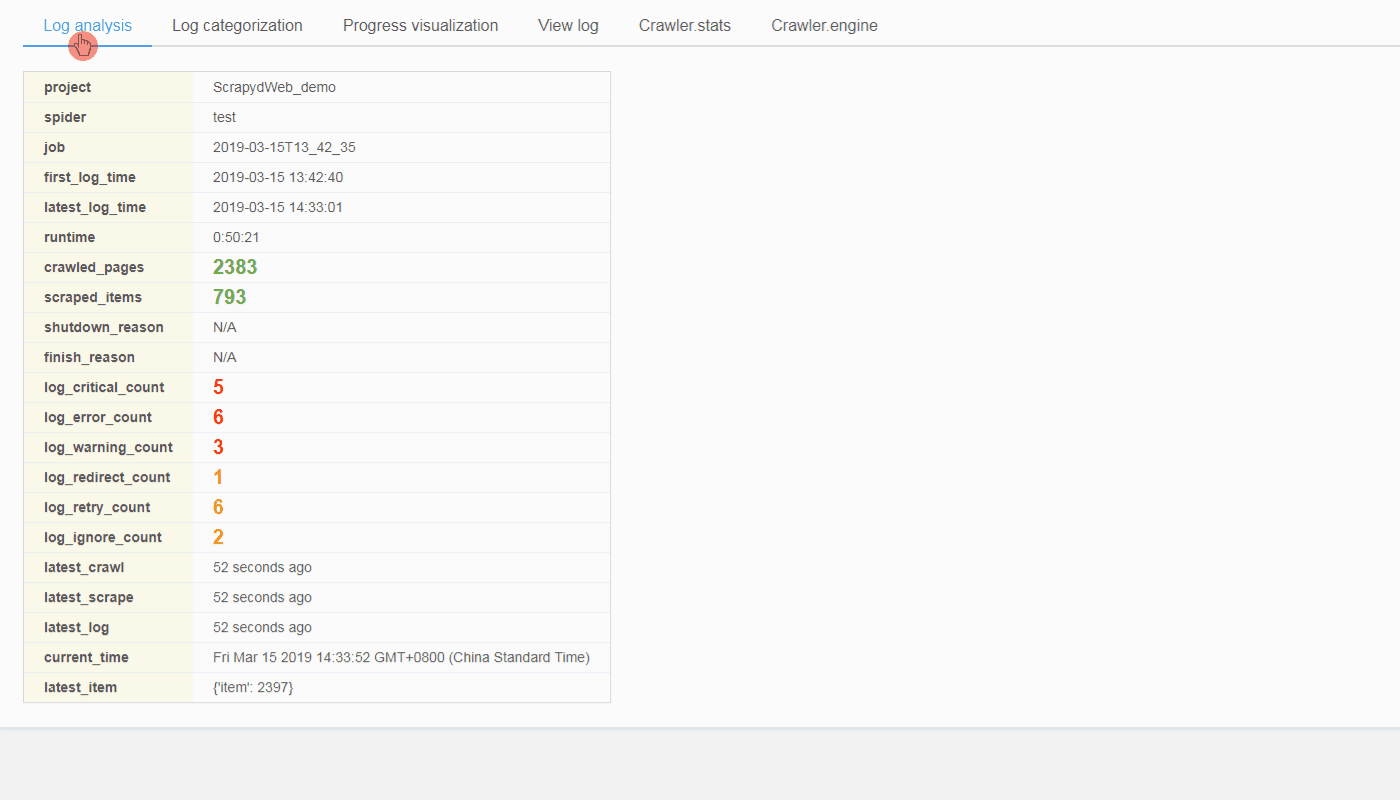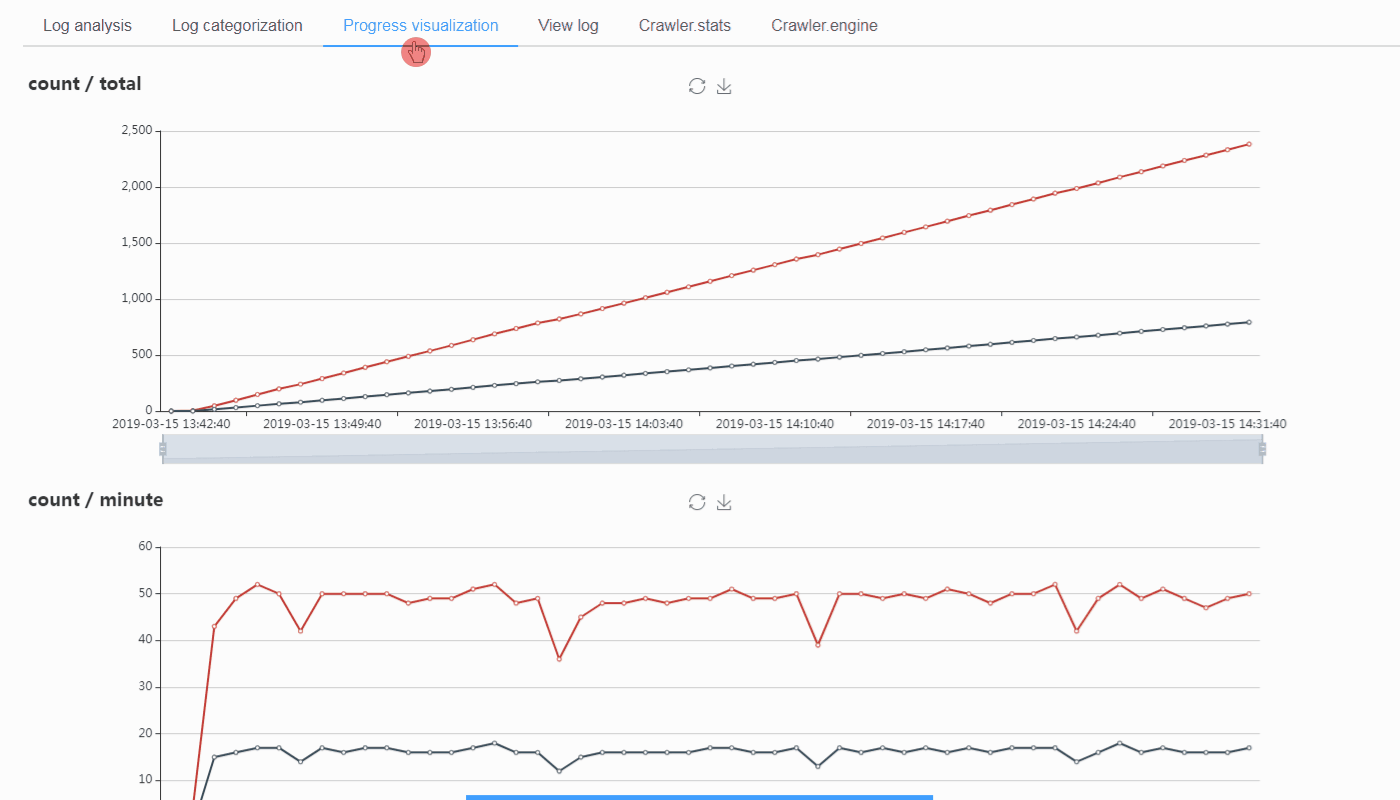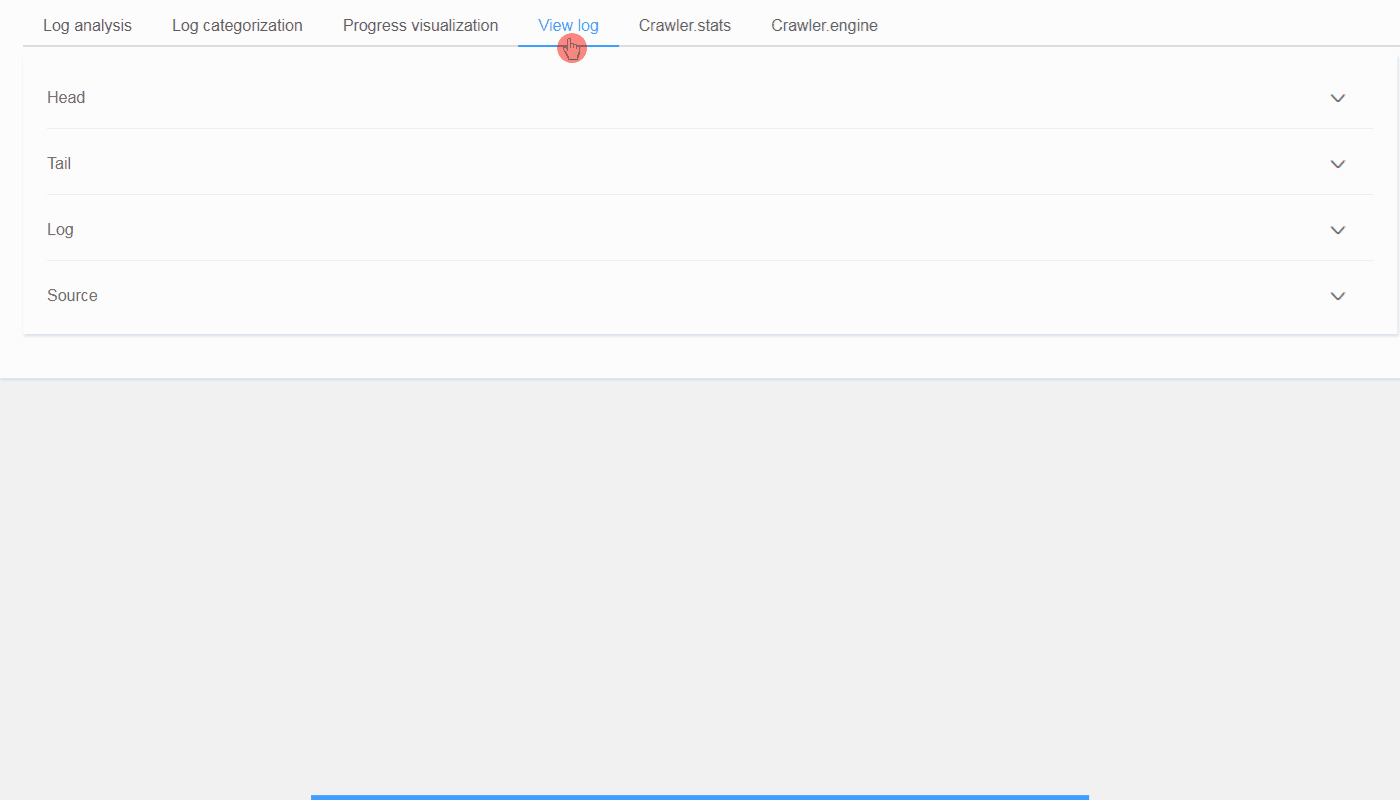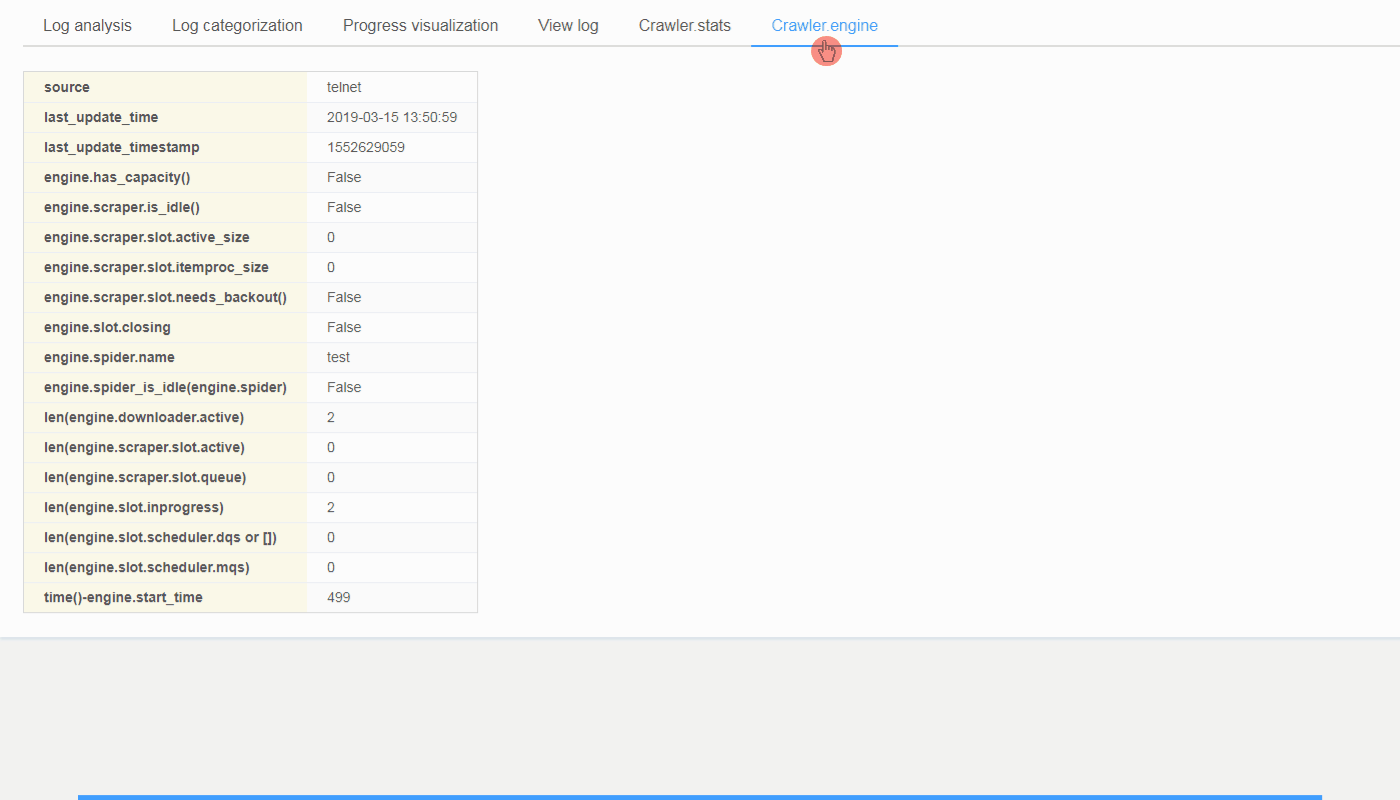 阅读全文
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号