SECONDO基础知识的学习
1. 介绍 SECONDO
SECONDO 是一个 DBMS 原型,专注于空间数据和时空数据的可扩展性和支持。
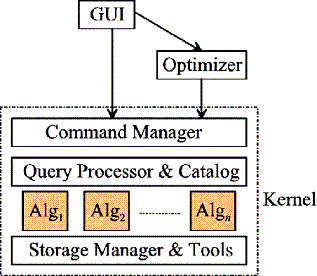
1.1 内核
Secondo 采用更激进的观点,将整个执行系统(称为内核)构建为一组代数。
Secondo 内核是通用的,因为它不支持特定的 DBMS 数据模型。相反,它能够存储在任何可用代数中实现的任意类型的数据。
Secondo 内核管理一组数据库。每个数据库都包含一组命名类型和命名对象。命名对象由名称、类型和该类型的值组成。内核提供了七个基本命令来操作类型和对象:
 |
命令 1 - 2 定义和删除类型。命令 3 - 6 创建和删除对象并为其赋值。命令 7 计算表达式并将结果返回到用户界面。 类型表达式由可用代数提供的类型构造函数构建,值表达式由对象名称、可用类型的常量和可用代数的操作构建。 |
Secondo 内核在命令行窗口中有一个简单的面向文本的用户界面(SecondoTTYBDB、SecondoTTYCS)。可以键入基本命令、打开和关闭数据库、导入和导出数据、管理事务等等。
内核是用 C++ 实现的。
1.2 查询优化器
Secondo 的第二个主要组件是查询优化器。与内核相比,它仅限于由代数为属性类型扩展的关系模型。这在一定程度上是因为 SQL 本身与关系模型密切相关。
1.3 Javagui
Secondo 的第三个主要组件是用 Java 编写的图形用户界面,因此被称为 Javagui。其基本结构如下图所示。
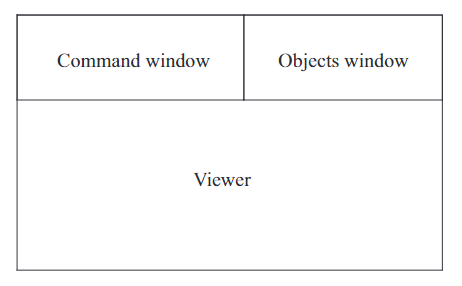 |
在命令窗口中,可以输入内核命令或优化器 SQL 命令,类似于 SecondoPLTTY。 查询的结果显示在查看器窗口中。 对象窗口包含当前显示(或至少加载到用户界面中)的查询列表或对象名称。 |
Javagui 可由查看器扩展,这些查看器可以专门用于显示特定的数据类型。因此,底部会根据所选的查看器而变化。
Javagui 不能与内核或优化器链接在一起,只能用于客户端-服务器(多用户)模式。Javagui 只能与内核通信。
1.4 SECONDO 提供的两种语言水平
除了 DBMS 一般提供的 SQL 之外,Secondo 还提供了独特的可执行语言来制定查询。问题是何时使用哪个级别。这两个级别都有优点和缺点:
- 可执行级别使用起来更复杂,并且需要详细了解可用的查询处理操作。另一方面,简单的查询可以很容易地用可执行语言编写。用户可以完全控制操作数据的步骤。内核系统的全部功能都可用,甚至可以使用最新添加的类型或索引结构。
- SQL 级别更易于使用,它提供了基于成本的优化。另一方面,SQL 级别受限于关系模型和 SQL 支持的查询形式。如果在 SQL 框架中可能的话,内核的高级添加需要额外的工作才能集成到优化器中。因此,优化器的开发滞后于内核的开发。
可执行语言的特点是复杂性和表达能力介于 SQL 和编程语言(如 C++)之间。事实上,人们可以用 Secondo 可执行语言编写复杂的“程序”。这些可以作为脚本存储在文件中并由 Secondo 执行。
2. SECONDO 的运行
2.1 单一用户界面
脚本 SecondoTTYBDB 是 SecondoBDB 的包装器。启动后,提示等待用户输入。数据库查询直接发送到 Secondo 内核,但一些操作直接由用户界面处理。所有其他命令都以分号或两个换行符终止(对于多行命令)。
启动 SecondoTTYBDB (也即是启动了 SECONDO 的单用户版本):

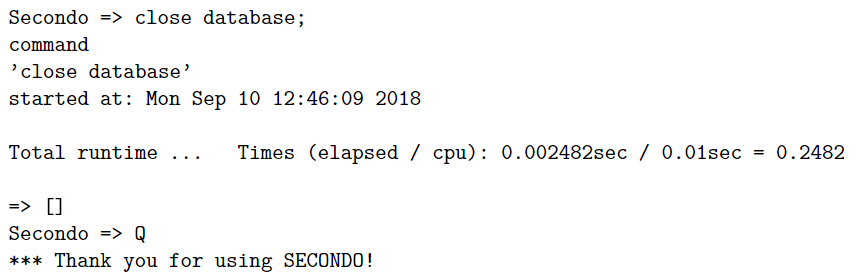
可以输入命令open database berlintest;打开 Berlintest 数据库,直接输入命令query mrain atinstant instant("2003-11-20-06:06");进行查询,输入命令close database;关闭数据库,输入Q关闭 SecondoTTYBDB ,如下所示
位于 Optimizer/ 目录中的接口 SecondoPL 运行带有 Secondo 绑定的 SWI Prolog 解释器。 Secondo 查询优化器无缝集成。
SecondoPLTTY 接口是 SecondoPL 和 SecondoTTYBDB 接口的组合。
2.2 客户服务器结构
Secondo 的客户端服务器模型允许多个用户或应用程序同时访问数据库,它将服务器部分和用户界面(客户端)分开,用户界面使用TCP/IP连接到服务器,因此不再需要在本地。
Secondo 侦听器反过来在传入的客户端连接上启动 Secondo 服务器,由 bin/ 目录中的 SecondoMonitor 程序启动。目前,它必须在 bin/ 目录本身中启动。
除了命令行界面之外,还有一个方便的图形用户界面,即 Javagui,它位于目录 Javagui/ 中。 Javagui 通过 TCP/IP 连接连接到正在运行的 Secondo 服务器。如果优化器服务器正在运行,Javagui 会自动连接并使用它。Javagui 本身以脚本 sgui 启动,并且必须在 Javagui/ 作为当前工作目录中执行。
3. SECONDO 中的查询
查询处理是 Secondo 的主要任务。与其他数据库管理系统 (DBMS) 一样,查询是用查询语言编写的。与其他系统相比,Secondo 提供两种查询语言:(1) 一种可执行语言和 (2) 一种类似 SQL 的语言。
可执行语言:可执行语言是一种低级语言。在这种语言中,详细描述了数据流和运算符之间的交互。数据流的描述称为查询计划。直接指定查询计划是 Secondo 的一个独特功能。可执行语言的优点是可以准确地指定应该如何处理查询以及应该使用哪些运算符。
类 sql 语言:类 sql 语言是一种声明性语言;只指定查询的结果。Secondo 的查询优化器生成所需的查询计划(用可执行语言描述),该计划计算所需的结果。与可执行语言相比,类 sql 语言有一些优势。对于熟悉 SQL 的人来说,这种语言更容易使用,查询更短,并且查询经过了优化(查询优化器生成了一个成本优化的查询计划)。
3.1 可执行语言
可执行语言用于通过描述运算符树来指定查询计划。运算符树描述了数据的处理方式。不执行查询计划的优化,操作完全按照指定的方式执行。
关系由元组组成。当处理一个关系时,处理是逐个元组完成的。feed 运算符可以将关系转换为元组流。在 Secondo 中,查询的结果必须是已知数据类型,并且不能是流。确实存在几个运算符来收集流并将其转换为某种数据类型。运算符 consume 获取流并创建一个新关系(如下图)。相反,运算符 count 获取流并生成一个带有流中元素数量的整数作为结果。
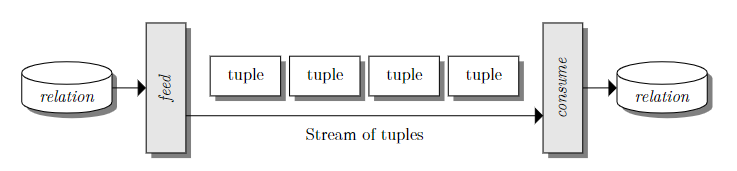
可执行语言的主要任务是描述运算符树。这些运算符树由 Secondo 的查询处理器执行。
在 Secondo 中,常量具有类型和值,它们可以使用以下语法定义:
 |
请注意,整数、字符串或布尔值等简单类型可以直接用作常量。 前三个例子可以写成 5、“secondo”和 TRUE。 |
常用的基本命令如下,可用于创建对象和执行查询
| query <value expression> | 计算给定值表达式并显示结果对象。 |
| let <identifier> = <value expression> | 计算给定值表达式,但不在屏幕上显示结果对象,而是将结果存储在名为 <identifier> 的对象中。仅当数据库中尚不存在 <identifier> 对象时,该命令才会成功运行;否则,将显示错误消息。 |
| derive <identifier> = <value expression> | 与 let 命令的工作方式基本相同,不同之处在于在创建和恢复数据库转储期间对已创建对象的处理。derive 命令应该用于没有外部表示的对象,例如索引。 |
| update <identifier> := <value expression> | 将值表达式的结果赋给数据库中的现有对象。 |
| delete <identifier> | 从当前打开的数据库中删除名称为 <identifier> 的对象 |
| type <identifier> = <type expression> | 在数据库中创建指定类型。 |
| delete type <identifier> | 从数据库中删除指定类型。 |
常用的组合命令如下:
| if <value expr> then <command1> [ else <command2> ] endif | 仅当条件 <value expr> 评估为真时运行命令 <command1>。 |
| while <value expression> do <command> endwhile | 在条件 <value expression> 计算结果为真时执行 <command>。 |
管理数据库的命令如下:
| create database <databasename> | 创建一个名为 <databasename> 的新数据库。 |
| open database <databasename> | 打开名为 <database-name> 的数据库。 |
| close database | 关闭当前打开的数据库。 |
| delete database <databasename> | 删除名称为 <database-name> 的数据库。在删除数据库之前,需要关闭所有数据库。 |
Secondo 导入或导出数据所需的命令如下,这些命令对于创建备份或加载现有数据库很有用。
| save database to <file> | 将当前打开的数据库以嵌套列表格式写入文件<file>。如果文件存在,将被覆盖,否则将被创建。 |
| restore database <identifier> from <file> | 将文件 <file> 的内容导入数据库 <identifier>。如果数据库已经存在,将被覆盖,否则将被创建。 |
| save <identifier> to <file> | 将对象 <identifier> 写入文件 <file>。如果文件已经存在,它将被覆盖。 |
| restore <identifier> from <file> | 创建一个名为 <identifier> 的新对象。如果已存在另一个同名对象,则该命令将失败。对象的类型和值从文件 <file> 中读取。 |
以下命令可以显示有关可用数据库、现有类型和对象以及 Secondo 已知的运算符和代数的信息。
| list databases | 显示所有已知数据库的名称列表。 |
| list algebras | 显示包含所有活动代数模块名称的列表。 |
| list algebra <identifier> | 显示指定代数的类型构造函数和运算符。 |
| list types | 显示当前打开数据库的命名类型列表。 |
| list objects | 显示当前打开数据库的对象列表。 |
3.2 类 sql 语言
这种语言基于 SQL 并实现了 SQL 标准的一个子集。类 SQL 语言由用 Prolog 编写的优化器处理。优化器用可执行语言生成查询计划,并将生成的查询传递到 Secondo 内核执行。类 SQL 语言的查询被提供给优化器,该优化器生成以可执行语言编写的查询计划。
4. SECONDO 的定制
4.1 改变代数模块集
一个新的代数模块可以通过将两个相应的行插入到 /secondo 目录下的文件 makefile.algebras 中来激活,例如
|
第一行引用代数模块所在目录的名称 第二行定义代数模块的名称 |
如果需要,可以通过删除或注释掉这两行来停用模块。但是,一些模块依赖于其他模块,因此在停用代数模块后,另一个模块可能无法再工作。在这种情况下,编译器会向用户提供一条错误消息,指出不可用的模块。
在 makefile.algebras 文件中发生任何更改后,必须通过调用 make 命令重新编译 Secondo 系统。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号