Queries in natural languages are still not supported in MODs. Since most users are not familiar with structured query languages, it is essentially important to bridge the gap between natural languages and the underlying MODs system commands.(MOD 中仍然不支持自然语言的查询。 由于大多数用户不熟悉结构化查询语言,因此弥合自然语言和底层 MOD 系统命令之间的差距至关重要。)
研究方法
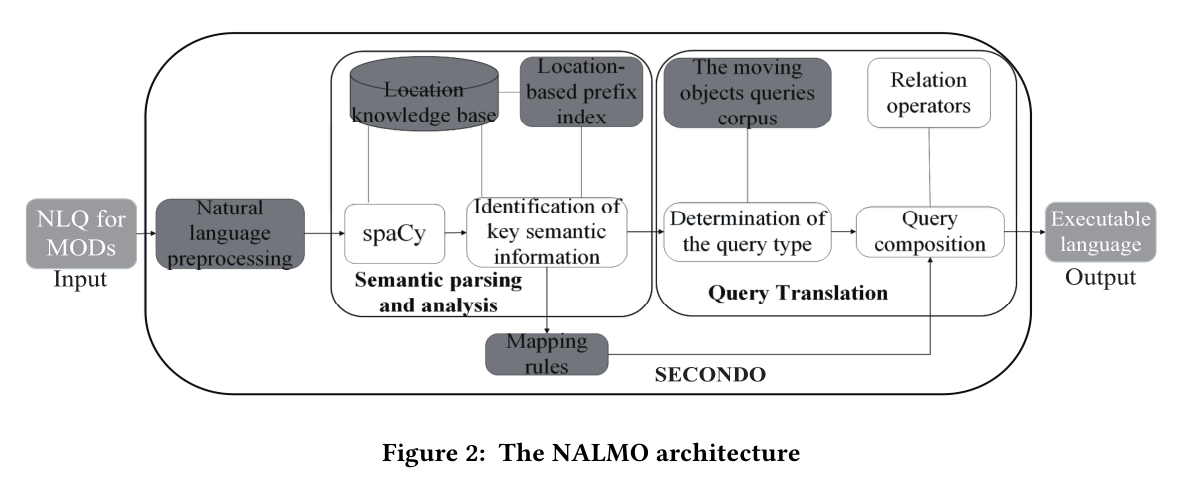
we design a natural language interface for moving objects, named NALMO. NALMO is able to well translate moving objects queries into structured (executable) languages.(我们为移动对象设计了一个自然语言界面,命名为 NALMO。NALMO 能够很好地将移动对象查询翻译成结构化(可执行)语言。)
We use semantic parsing in combination with a location knowledge base and domain-specific rules to interpret natural language queries.(我们使用语义解析结合位置知识库和特定领域的规则来解释自然语言查询。)
We design a corpus of moving objects queries for model training, which is later used to determine the query type. We support four kinds of queries including time interval queries, range queries, nearest neighbor queries and trajectory similarity queries.(我们设计了一个用于模型训练的移动对象查询语料库,稍后用于确定查询类型。我们支持四种查询,包括时间间隔查询、范围查询、最近邻查询和轨迹相似性查询。)
Extracted entities from parsing are mapped through deterministic rules to perform query composition.(从解析中提取的实体通过确定性规则映射以执行查询组合。)
系统架构
自然语言理解
We retain or delete the punctuations, and utilize the tool spaCy to perform word segmentation and do entity recognition.(我们保留或删除标点符号,并利用工具spaCy进行分词和实体识别。)
Since entities are approximately processed by spaCy, key information for moving objects queries is not accurate and the results are not sufficient for structured language construction. To increase the translation quality, we propose an algorithm to further parse the spatio-temporal data.(由于spaCy对实体进行了近似处理,因此移动对象查询的关键信息不准确,结果不足以进行结构化语言构建。 为了提高翻译质量,我们提出了一种算法来进一步解析时空数据。)
In order to determine the location, we generate a location knowledge base which extracts objects whose attribute is point or region.(为了确定位置,我们生成一个位置知识库,它提取属性为点或区域的对象。)
In order to improve the query efficiency, we construct a locationbased prefix index for matching the location knowledge base. A large number of locations often contain the same prefix. Therefore, the index can effectively improve the extraction efficiency of location information.(为了提高查询效率,我们构建了一个基于位置的前缀索引来匹配位置知识库。 大量位置通常包含相同的前缀。 因此,该索引可以有效提高位置信息的提取效率。)
查询翻译
The translation consists of two steps: (i)determining the query type and (ii)constructing the structured language.(翻译包括两个步骤:(i)确定查询类型和(ii)构建结构化语言。)
There are different types of queries and a corpus is built to determine the query type. The corpus makes use of an LSTM neural network to train a model for identifying the query type.(有不同类型的查询,并且构建了一个语料库来确定查询类型。 语料库使用 LSTM 神经网络来训练识别查询类型的模型。)
Extracted entities are mapped to the data relation and corresponding values according to the query type. At the same time, operators are selected to constitute the query structure.(根据查询类型将提取的实体映射到数据关系和对应的值。 同时,选择运算符来构成查询结构。)
实验评估
We evaluate our approach using 240 natural language queries extracted from popular conference and journal papers in the domain of moving objects. (我们使用从移动对象领域的流行会议和期刊论文中提取的 240 个自然语言查询来评估我们的方法。)
Experimental results show that(实验结果表明,(i)NALMO的准确率和精度分别达到98.1%和88.1%,并且 (ii) 翻译查询的平均时间成本为 1.47 秒)
NALMO achieves accuracy and precision 98.1%and 88.1%
the average time cost of translating a query is 1.47s

 浙公网安备 33010602011771号
浙公网安备 33010602011771号